L'apprendimento induttivo
Una delle forme più semplici di machine learning supervisionato è l'apprendimento induttivo. Si basa esclusivamente sull'osservazione.
Dato un insieme iniziale di esempi di input-output, l'agente elabora delle ipotesi per ricostruire la funzione di causa-effetto fino a quel momento sconosciuta.
E' anche conosciuto come inferenza induttiva pura o apprendimento per induzione.
Come funziona l'apprendimento induttivo?
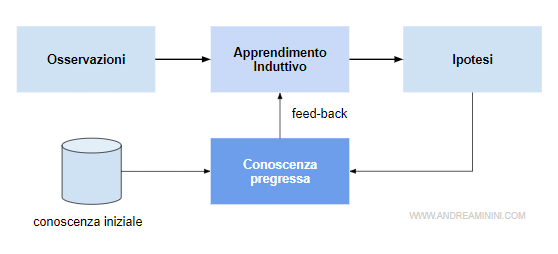
L'agente viene progettato per osservare l'interazione con il mondo esterno. In particolar modo, l'agente analizza i feed-back delle sue decisioni.
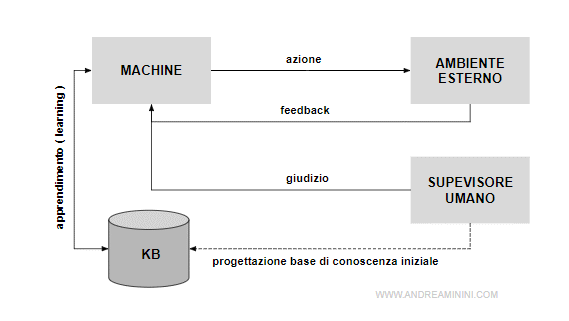
Le percezioni dell'agente artificiale possono essere usate:
- per prendere decisioni ( agente reattivo )
- per migliorare la capacità decisionale dell'agente ( machine learning )
Un esempio pratico di apprendimento induttivo
La macchina acquisisce una serie di esempi di input-output forniti dal supervisore.
La serie di esempi è conosciuta tecnicamente come training set ( insieme di addestramento ).
In questo caso, si tratta di semplici coordinate (x,y) su un piano cartesiano. Dove x è l'input e y è l'output.
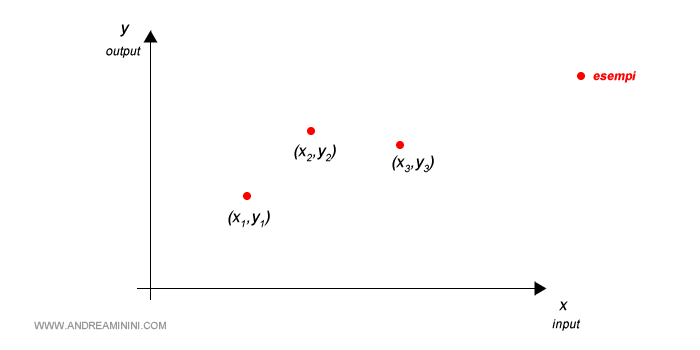
La macchina non conosce ancora la funzione reale y=f(x) che lega la variabile determinante x alla variabile determinata y.
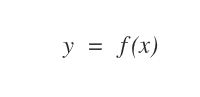
A questo punto, la macchina sceglie uno spazio delle ipotesi contenente diverse funzioni.
Cos'è lo spazio delle ipotesi? In questo esempio lo spazio delle ipotesi è l'insieme di polinomi di grado finito k. E' un insieme finito, composto da un determinato numero di funzioni ipotetiche h(x). Se lo spazio delle ipotesi contiene almeno anche la funzione reale f(x), il problema è realizzabile. Viceversa, se non la contiene, il problema non realizzabile. Essendo la funzione reale f(x) sconosciuta, non è possibile affermare a priori se uno spazio delle ipotesi è realizzabile oppure no.
Poi analizza quali funzioni ipotetiche sono consistenti, ossia hanno i punti in comune con gli esempi di input-output.
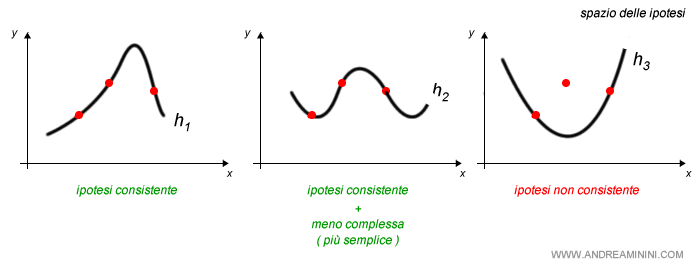
Tra tutte le ipotesi l'agente razionale sceglie la funzione consistente più semplice.
Nota. La scelta della funzione coerente è comunque arbitraria e soggettiva. A volte non è detto che quella giusta sia sempre la più semplice. Tuttavia, non avendo altre informazioni a riguardo, secondo il rasoio di Occam è razionale scegliere l'ipotesi più semplice tra tutte quelle consistenti con i dati. Permette di generalizzare uno schema ( pattern ). Inoltre, in un sistema computazionale è più facile da utilizzare.
La funzione h è detta funzione ipotesi.
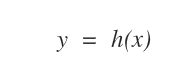
E se la macchina non trova un'ipotesi consistente?
Quando l'agente non riesce a trovare una funzione ipotesi consistente con i dati degli esempi di input-output, ha tre possibilità:
- Ampliare lo spazio delle ipotesi. L'agente amplia l'insieme delle funzioni tra cui cercare quella consistente. Ad esempio, dalle funzioni lineari alle funzioni polinomiali di grado superiore, trigonometriche, ecc.
Pro e contro. Questa strada penalizza la complessità temporale e spaziale dell'algoritmo di ricerca. Inoltre, in molti casi non è possibile analizzare tutte le ipotesi possibili.
- Ipotesi per approssimazione. L'agente sceglie la funzione che approssima meglio la funzione reale, pur non essendo perfettamente consistente con i dati degli esempi. E' una funzione non deterministica.
Pro e contro. L'ipotesi approssimata si basa su una generalizzazione e non corrisponde alla funzione reale. Quindi, potrebbe non essere in grado di prevedere l'andamento futuro dei dati. Implica un rischio. D'altra parte, spesso la soluzione approssimata è l'unica soluzione ragionevole, a basso costo e a bassa complessità computazionale ( più semplice ). In statistica, una delle più semplici funzioni non deterministiche è la regressione lineare.
- Conoscenza a priori. L'agente utilizza la conoscenza pregressa per trovare uno spazio delle ipotesi che contenga la funzione reale f(x). In questo caso, la macchina non parte da zero, perché è stata programmata a priori dal supervisore umano per affrontare queste situazioni. Quindi, l'agente artificiale sa già qualcosa sull'apprendimento e su come apprendere le nuove informazioni.
Pro e contro. Spesso questo approccio è utile. Tuttavia, ha l'handicap di limitare il campo di ricerca dell'agente alle euristiche del supervisore. Ad esempio, le soluzioni migliori, ma più originali, potrebbero trovarsi in uno spazio delle ipotesi non preso in considerazione dalla conoscenza pregressa. Per evitare questo problema è consigliabile usare una conoscenza iniziale minima, lasciando all'agente razionale la possibilità di modificare la KB in base alla conoscenza pregressa, ossia alla conoscenza generata dalle sue osservazioni.
Quale approccio scegliere?
Generalmente, la teoria classica dell'apprendimento si focalizza sulle rappresentazioni più semplici.
Lo spazio delle ipotesi viene espanso cercando di limitare la complessità della ricerca a livelli accettabili.
Nota. Tuttavia, ogni strada ha pro e contro. Nel machine learning non è detto che la soluzione più semplice, più logica o quella più complessa siano le migliori. A volte la soluzione migliore è approssimata ed è fornita dalle euristiche.
L'approccio incrementale all'apprendimento induttivo
L'approccio incrementale è una tecnica di apprendimento induttivo.
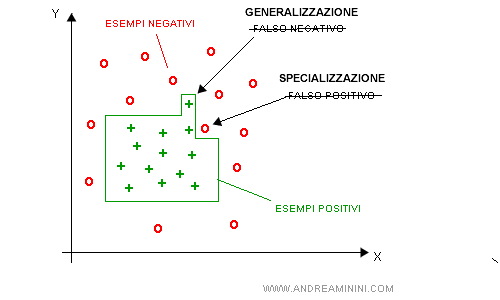
Consiste nell'ampliare ( generalizzazione ) o ridurre ( specializzazione ) lo spazio delle ipotesi per renderlo consistente con gli esempi.
- La generalizzazione amplia lo spazio delle ipotesi rimuovendo una condizione.
- La specializzazione riduce lo spazio delle ipotesi introducendo una nuova condizione.
Lo spazio delle ipotesi H si modifica durante l'apprendimento, a seconda dell'esito sugli esempi di training.
Nota. E' un approccio particolarmente costoso perché ogni modifica allo spazio potrebbe non essere consistente con i precedenti esempi. E' quindi necessario rivalutare tutti gli esempio dopo ogni modifica ed eventualmente annullare la modifica con un'operazione di backtracking.
Come ridurre lo spazio delle ipotesi
La conoscenza a priori permette di eliminare le ipotesi fuorvianti che altrimenti risulterebbero consistenti, facendo perdere tempo e risorse alla macchina.
Esistono diversi approcci per gestire la conoscenza a priori nell'apprendimento induttivo.
- EBL ( Explanation Based Learning ). E' l'apprendimento basato sulle spiegazioni. Estrae delle regole dagli esempi tramite una spiegazione generalizzata.
- RBL ( Relevance Based Learning ). E' l'apprendimento basato sulla rilevanza. Identifica gli attributi più rilevanti per ridurre lo spazio delle ipotesi e accelerare l'apprendimento.
- KBIL ( Knowledge Based Inductive Learning ). E' l'apprendimento basato sulla conoscenza. Ricerca delle ipotesi induttive per spiegare gli esempi tramite una conoscenza di base.




