La Cross validation
La cross validation (o validazione incrociata) è una tecnica statistica usata nel machine learning per eliminare il problema dell'overfitting nei training-set. E' detta anche k-fold validation.
Cos'è l'overfitting? Si verifica quando il dataset è composto da attributi irrilevanti che rendono difficile l'induzione dell'albero decisionale.
Come funziona la convalida incrociata
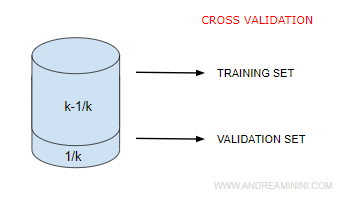
Suddivido il training set in k parti di uguale dimensione. In genere, si divide in 5 o 10 parti.
Poi seleziono una parte 1/k per utilizzarla come validation set.
Le restanti parti k-1/k invece continuano a comporre il training dataset.
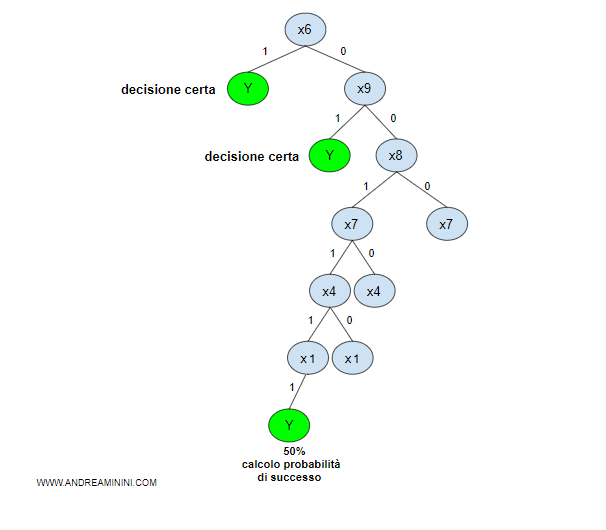
Poi avvio il processo di apprendimento induttivo sul training set residuo ( k-1/k ) per costruire l'albero decisionale.
Una volta costruito, verifico l'efficacia predittiva dell'albero utilizzando il validation set della parte 1/k.
Calcolo così un valore predittivo dell'albero parziale.
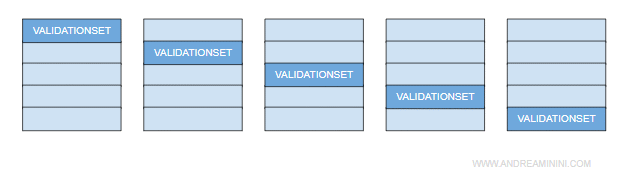
Ripeto la stessa procedura per k volte, selezionando ogni volta un sottoinsieme diverso come validation set.
In questo modo ottengo k alberi decisionali parziali e ognuno ha un valore predittivo.
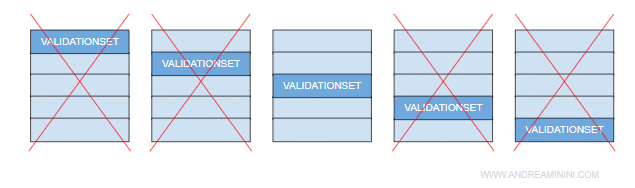
Nota. In ogni esperimento lascio fuori dal training set un sottoinsieme diverso dei dati per usarlo come validation set degli altri. Per questo motivo questa tecnica è anche conosciuta come leave-one-out.
A questo punto, calcolo la media dei valori predittivi ottenuti nei k esperimenti.
Posso così selezionare l'albero parziale con il valore predittivo più alto e utilizzarlo come modello.
L'albero selezionato è quello che risente meno del rumore causato dagli attributi irrilevanti presenti nel dataset ( overfitting ).
Nota. Per evitare il rischio di peeking, ossia di eccessiva influenza dei dati di test sulla realizzazione dell'albero decisionale, verifico l'efficacia dell'albero selezionato anche con un nuovo validation set.




