Attributi con valori continui negli alberi decisionali
La presenza di attributi con valori continui, reali o discreti, complica il processo di costruzione degli alberi decisionali perché possono contenere infiniti valori.
Esempio. Il prezzo è un'informazione tipicamente continua. Se un prodotto costa 0.98€ e l'altro 0.99€, in un albero decisionale avrebbero formalmente due valori diversi pur essendo molto simili.
Generalmente un attributo con valori continui ha molti valori. Tuttavia, in questo caso la variabilità dei valori non accresce l'informazione bensì la riduce ( vedi problema degli attributi con molti valori ).
Come risolvere il problema
La soluzione più semplice è la creazione di classi per comprendere un range di valori.
Esempio. La classe A comprende i prezzi inferiori a 0.75€. La classe B i valori da 0.75€ a 1.25€. La classe C i prezzi superiori a 1.25€.
In questo modo la dispersione dell'informazione viene ricondotta a un numero accettabile.
Come creare le classi?
Il raggruppamento in classi e categorie è molto importante perché influisce sull'efficienza e sull'efficacia dell'albero decisionale che si sta costruendo.
In genere, si cerca un punto di demarcazione ( split point ) in grado di massimizzare il guadagno informativo.
Un esempio pratico
In questo insieme di dati un attributo (X2) ha dei valori continui.
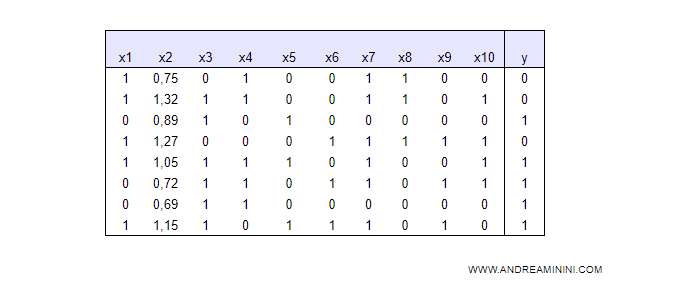
Lo ordino per X2 dal valore più basso a quello più alto.
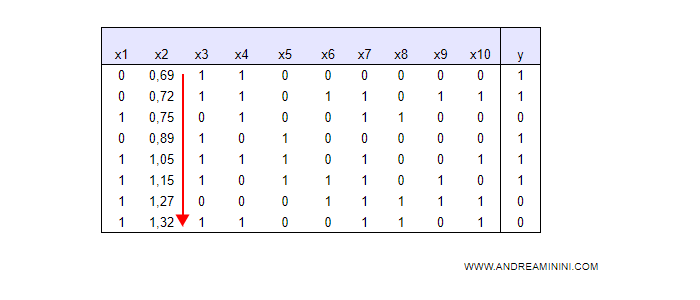
Questa nuova rappresentazione mi permette di trovare a colpo d'occhio due split point.
I valori fino a 0.72 hanno tutti una risposta positiva ( y=1 ) mentre quelli oltre 1.15 hanno tutti una risposta negativa ( y = 0 ).
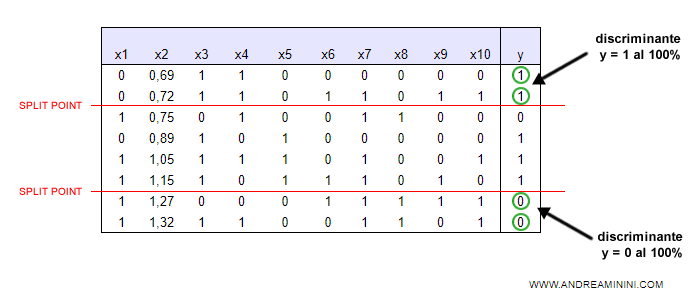
Posso così creare tre classi ( fasce di prezzo )
- Classe A. Da 0 a 0.75
- Classe B. Da 0.75 a 1.26
- Classe C. Da 1.26 a 1.32
La prima classe (A) e l'ultima classe (C) mi permettono di discriminare l'output al 100% rispettivamente per y=1 e per y=0.
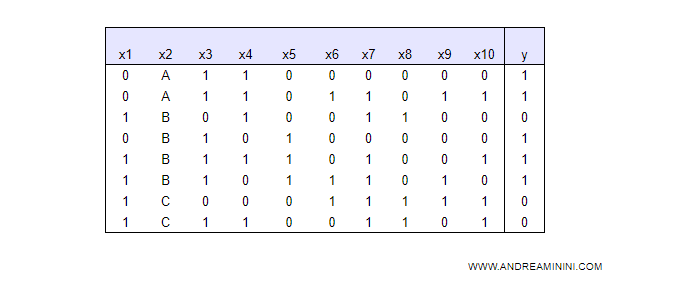
Nota. Tutto sommato anche la seconda fascia (B) è accettabile perché discrimina l'informazione y=1 al 80% in quanto contiene 3 casi positivi su 4.
Questo esempio di costruzione delle classi è molto semplice, quasi banale, ma è comunque utile per comprendere lo scopo dell'algoritmo.
In realtà, esistono algoritmi di selezione molto più complessi per individuare gli split point.
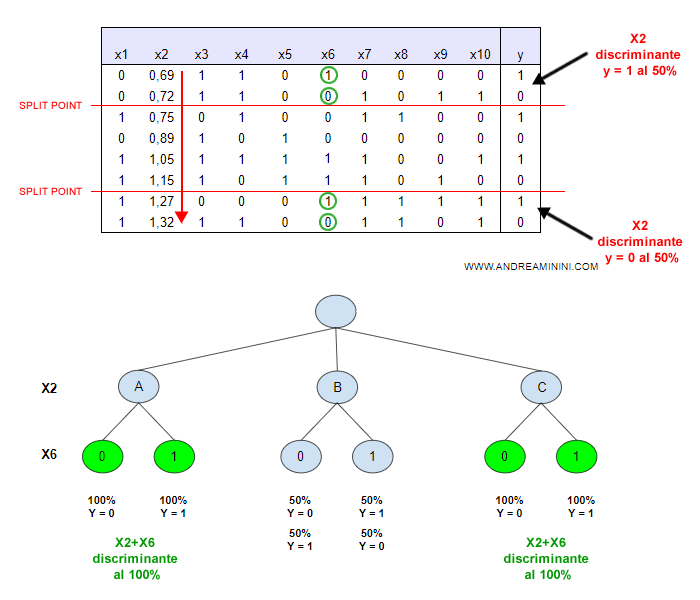
Un altro esempio. Quando non è facile trovare un fattore discriminante diretto per y=1 occorre analizzare le sottoramificazioni della classe negli altri attributi ( x1 ... X10 ). Le classi con sottoramificazioni più discriminanti rispetto a y sono le migliori. In quest'altro esempio le classi A,B,C discriminano soltanto al 50%. Apparentemente è inutile. Tuttavia, se abbino X2+X6 le classi A e C salgono a una discriminazione per y al 100%. Quindi, considerando anche la sottoramificazione in X6 la classificazione A, B, C di X2 è comunque significativa per la costruzione dell'albero decisionale.