Un esempio pratico su TensorFlow
In questo tutorial ho scritto un esempio di utilizzo di TensorFlow nel machine learning ( apprendimento automatico ). E' un esempio classico di classificazione e riconoscimento, conosciuto come iris model.
Prerequisiti. Per realizzare questo tutorial è necessario avere già installato python3 e TensorFlow sul computer. Purtroppo, spesso Google cambia il nome dei metodi sulle nuove release di TensorFlow. Pertanto, se le istruzioni di questo tutorial vanno in errore, occorre sostituirle con quelle più recenti. Fortunatamente il metodo per sostituirle è indicato nei messaggi di errore stessi.
Come funziona TensorFlow
Inizio a scrivere il programma in python importando le librerie numpy e tensorflow.
import numpy as np
import tensorflow as tf
In una tabella in formato CSV sono inserite le misure di quattro caratteristiche dei fiori.
Sono le variabili indipendenti x del problema.
- Sepal length ( lunghezza sepalo )
- Sepal width ( larghezza sepalo )
- Petal length ( lunghezza petalo )
- Petal width ( larghezza sepalo )

In ciascuna riga è anche indicato il codice della specie (setosa, virginica, versicolor) del relativo fiore Iris.
E' la variabile dipendente y del problema.
- 0 = Iris setosa
- 1 = Iris virginica
- 2 = Iris versicolor
Questa tabella è detta dataset training ( o training set ).
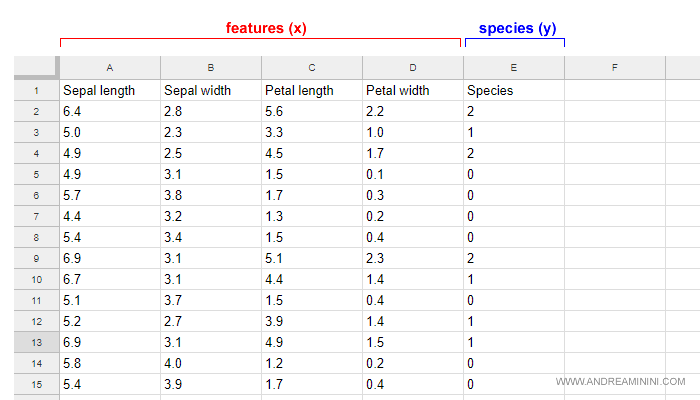
Nota. Il set training è composto da 120 esempi. Il files CSV deve essere scaricato ( iris_training.csv ) e salvato in una cartella a propria scelta sul computer o su una pen drive.
Nel programma python indico il nome e il percorso (path) della tabella csv sul PC.
IRIS_TRAINING = "../_data/iris_training.csv"
Poi carico il dataset nella variabile training_set
training_set = tf.contrib.learn.datasets.base.load_csv_with_header(
filename=IRIS_TRAINING,
target_dtype=np.int,
features_dtype=np.float32)
A partire da questa tabella TensorFlow deve costruire una "funzione" in grado di unire y≅f(x).
Questa funzione è una rete neurale ed è detta modello.

A cosa serve il modello? E' un modello di previsione. Fornendo in input 4 valori qualsiasi (sepal length, sepal width, petal length, petal width) il modello restituisce la specie più probabile del fiore.
Come calcolare il modello
Nel programma python specifico quante sono le caratteristiche dei dati su cui lavorare.
In questo caso sono quattro (sepal length, sepal width, petal length, petal width).
feature_columns = [tf.contrib.layers.real_valued_column("", dimension=4)]
Poi configuro le caratteristiche della deep neural network ( DNN ).
Scelgo di costruire una rete neurale con 3 serie di nodi nascosti interni ( hidden_units ).
La prima serie ha 10 nodi, la seconda serie 20, la terza serie 10.
classifier = tf.contrib.learn.DNNClassifier(
feature_columns=feature_columns,
hidden_units=[10, 20, 10],
n_classes=3,
model_dir="/tmp/iris_model")
Nel codice indico anche il numero delle classi (n_classes) in cui classificare i dati.
In questo caso sono 3 ( iris setosa, iris virginica, iris versicolor ).
E' anche indicata la cartella del computer dove salvare il modello ( es. /tmp/iris_model ).
Perché salvare il modello? E' molto utile salvare il modello perché il calcolo può durare anche molte tempo. Se voglio riutilizzarlo, è meglio salvarlo da qualche parte, in modo da non doverlo ricalcolare ogni volta.
Ora definisco l'area dei dati per costruire il modello a partire dal training_set.
def get_train_inputs():
x = tf.constant(training_set.data)
y = tf.constant(training_set.target)
return x, y
Infine avvio l'elaborazione vera e propria di TensorFlow per costruire il modello.
classifier.fit(input_fn=get_train_inputs, steps=2000)
In questo caso l'elaborazione dura soltanto qualche minuto.
In altri casi anche molte ore.
Da cosa dipende il tempo di elaborazione? Il tempo di elaborazione dipende dalle serie di nodi della rete neurale, dal numero delle caratteristiche e dalle iterazioni necessarie per calcolare un modello con un'accuratezza almeno accettabile.
Come calcolare l'accuratezza previsionale del modello
Una volta trovata trovato il modello, fornisco a TensorFlow un altra tabella con stesse caratteristiche ma altri valori.
Questa seconda tabella è detta dataset test ( o test set ).
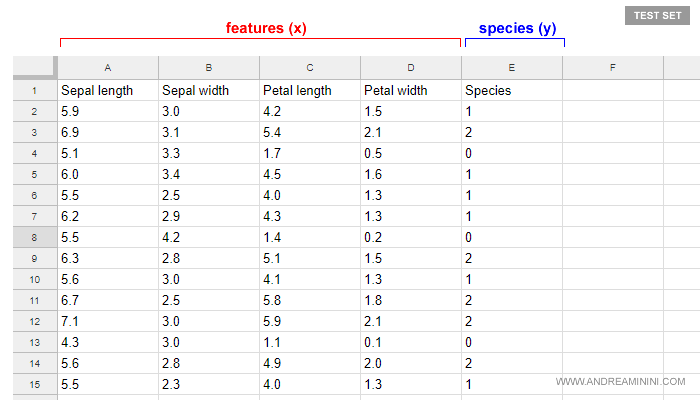
Nota. Il test set è composto da 30 esempi diversi dal training set. Il files CSV deve essere scaricato ( iris_test.csv ) e salvato in una cartella a propria scelta sul computer o su una pen drive.
Sul programma python indico la tabella di test set.
IRIS_TEST = "../_data/iris_test.csv"
Poi la carico in memoria nella variabile test_set
test_set = tf.contrib.learn.datasets.base.load_csv_with_header(
filename=IRIS_TEST,
target_dtype=np.int,
features_dtype=np.float32)
In questo caso TensorFlow vede soltanto le quattro caratteristiche (x) del test set. Non vede la specie (y).
Per trovare il nome del fiore (y) usa il modello appena costruito.
Nel programma python definisco l'area dei dati del test set.
def get_test_inputs():
x = tf.constant(test_set.data)
y = tf.constant(test_set.target)
return x, y
Poi calcolo l'accuratezza del modello
accuracy_score = classifier.evaluate(input_fn=get_test_inputs, steps=1)["accuracy"]
Se il modello è stato costruito bene, dovrebbe trovare comunque il nome dei fiori (y) con un'accuratezza accettabile.
print(accuracy_score)
In questo caso il modello restituisce un'accuratezza del 96,7%.
Come utilizzare il modello previsionale
A questo punto faccio una prova pratica, creo un'istanza con due serie di valori a mia scelta.
Su python definisco l'area dati dell'istanza.
def new_samples():
return np.array(
[[6.4, 3.2, 4.5, 1.5],
[5.8, 3.1, 5.0, 1.7]], dtype=np.float32)
Poi uso il modello per trovare la specie del fiore dei due esempi.
Il modello legge le misure degli esempi e le classifica in una delle tre classi ( setosa, virginica o versicolor ).
predictions = list(classifier.predict_classes(input_fn=new_samples))
Infine stampo a video il risultato che il modello ha estrapolato.
print(predictions)
Se tutto va bene, il modello dovrebbe restituire in output [1,1]
Il modello ha classificato i dati di entrambi gli esempi dell'istanza nella categoria 1 ( virginica ).
Alcune volte potrebbe restituire anche [1,2].
E così via.
Nota. Lo stesso algoritmo di classificazione può essere programmato usando l'algoritmo Perceptron in python senza usare TensorFlow. Il risultato finale è simile.




