Quando usare nofollow e noindex nelle pagine web
L'effetto collezione di un sito web
Un sito web è composto da molte pagine ma non tutte sono utili per l'utente. Una buona parte delle pagine di un sito web sono documenti di servizio, vecchi articoli o brevi comunicazioni agli utenti. Si tratta di pagine poco utili, o a basso valore aggunto, che riducono l'esperienza utente.
Ad esempio, le pagine dei tags e delle news contengono molti testi duplicati poiché aggregano titoli, abstract e link verso altri articoli del sito. Le pagine del disclaimer e delle noti legali contengono richiami di legge ( contenuti duplicati ) e sono linkate da tutte le pagine del sito ma appaiono come documenti off-topic rispetto agli articoli.
Altre pagine del web del sito sono utilizzate per brevi comunicazioni agli utenti, come quelle di ringraziamento per essersi iscritti alla newsletter o per aver lasciato un commento.
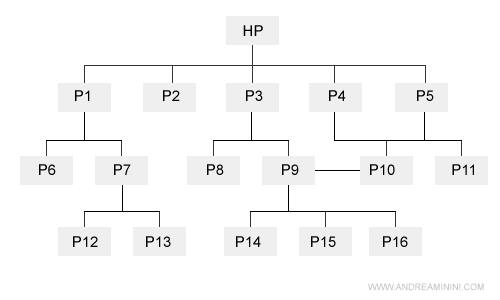
Qualche anno fa si tendeva a lasciare online tutte queste pagine inutili che finivano inesorabilmente nel deep web del sito e qualcuno continuava a trovarle sui motori di ricerca. Un po' come mettere in cantina qualcosa, ben sapendo che non la riutilizzeremo mai più.
Nel tempo i motori di ricerca sono cambiati. Gli algoritmi dei search engine sono meno indulgenti verso le pagine poco utili, le considerano spam engine. C'è da stare molto attenti, se il numero delle pagine inutili è alto, l'intero sito web può essere penalizzato o declassato.
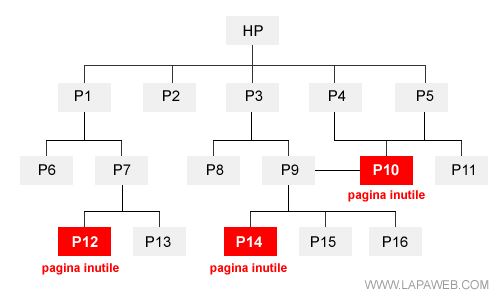
Ad esempio, l'algoritmo Panda di Google penalizza le pagine con pochi contenuti. Se un sito web ne ha molte, inevitabilmente rischia di essere penalizzato nell'insieme e anche i documenti con più contenuti iniziano a perdere posizioni sulle serp.
Una sorta di effetto collezione che premia i siti con molti contenuti di qualità e penalizza tutti gli altri. Ad esempio, nel seguente diagramma di Lapaweb abbiamo disegnato una possibile curva di affidabilità del sito web sulla base della sua percentuale di pagine inutili.
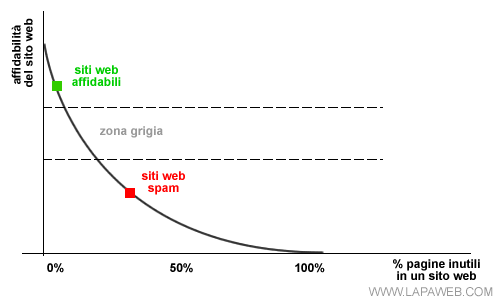
Per evitare questo problema abbiamo due strade a nostra disposizione, possiamo cancellare le pagine inutili oppure deincicizzarle dai motori di ricerca. Vediamo la differenza.
La cancellazione delle vecchie pagine
Guardiamo il sito web come un bonsai e, dopo un'attenta analisi, tagliamo i rami inutili per concentrare la linfa vitale soltanto nelle pagine di qualità. Le pagine inutili sono eliminate fisicamente dal sito web. Nella figura seguente di Lapaweb abbiamo indicato con una X i documenti cancellati.
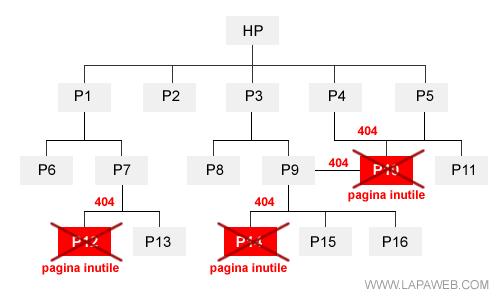
E' una strada abbstanza efficace ma ci espone al rischio degli errori 404 ( file non trovato ). Ad esempio, l'indirizzo URL di una pagina appena cancellata (P10) potrebbe essere ancora linkato da altre pagine del sito ( P9 e P4) oppure da siti web esterni o dai search engine.
Quando un utente clicca sul link, non visualizza più la vecchia pagina ma un errore 404 o, nel migliore dei casi, la nostra pagina di cortesia per avvisarlo che il documento non è più disponibil. Molti errori 404 possono anche causare il declassamento sui motori di ricerca.
E' quindi necessario controllare tutti i link interni del sito web ed eliminare quelli verso le pagine inesistenti. In questo modo togliamo tutti i binari morti del sito. Non possiamo però fare nulla per i collegamenti esterni provenienti da altri siti web.
L'uso del nofollow e noindex ( deindicizzazione )
Tramite nofollow e noindex possiamo ottenere lo stesso risultato della cancellazione di un file ma senza penalizzare l'esperienza dell'utente. Questa operazione è conosciuta come deindicizzazione delle pagine.
Inserendo i parametri nofollow e noindex nel metatag robots della pagina da eliminare, comunichiamo ai motori di ricerca di voler deindicizzare la pagina ( noindex ) e di non seguire i link che partono questa ( nofollow ).
<html>
<head>
<meta name="robots" content="noindex, nofollow">
</head>
<body>
... articolo ...
</body>
</html>
In questo modo, queste pagine cessano di esistere soltanto per il search engine ma non per gli utenti. Le pagine continuano ad essere visibili agli utenti che le raggiungono tramite link. Abbiamo così risolto il problema dell'errore 404 dei backlink interni ed esterni.
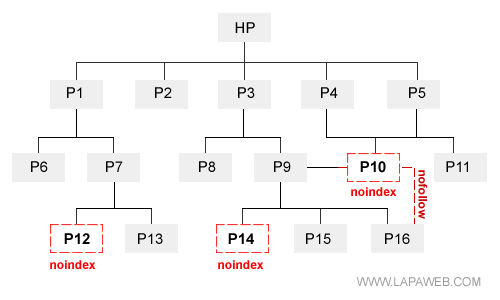
D'altra parte i motori di ricerca cessano di considerarle. Le pagine troppo corte, con contenuti duplicati o a rischio spam, non sono più un pericolo per tutte le altre pagine del sito web.
L'importanza del nofollow
Il noindex potrebbe non essere sufficiente, è necessario specificare anche il nofollow. In assenza del nofollow il motore di ricerca continua a seguire i link provenienti dalla pagina per il computo del page rank, e questo non esclude che le pagine siano penalizzate per spam link.
Il nofollow nei metatags non deve essere confuso con il nofollow sui link. Il nofollow nei metatag dice al motore di ricerca di non seguire nessun link nella pagina, quello sul singolo link è invece limitato a quel collegamento ipertestuale e non agli altri.
L'aggiunta del parametro nofollow nei metatag elimina ogni pericolo. I search engine non devono più analizzarle, né il contenuto, né i link. Siamo così sicuri di non essere penalizzati dai search engine per il deep web del sito e concentrare la potenza del sito soltanto nelle pagine di qualità. Andrea Minini 18 / 01 / 2015
La deindicizzazione con il file robot
Quando le pagine da deindicizzare sono tutte contenute in una cartella del sito e la cartella non contiene altri documenti indicizzati o sottocartelle indicizzate, possiamo deindicizzare tutti i documenti con un'unica operazione tramite il file robots.txt del sito web.




