Analisi grammaticale del testo
L'analisi grammaticale del testo è l'associazione di una parte del discorso a ogni parola di una frase. Consente di stabile le relazioni tra le parole di una frase, quelle adiacenti e quelle contenute all'interno di una stessa proposizione.
Le parti del discorso
Le principali parti del discorso sono le seguenti:
- aggettivo
- articolo
- avverbio
- congiunzione
- interiezione
- preposizione
- pronome
- sostantivo
- verbo
Part of Speech Tagging ( POS )
Il Part of Speech Tagging ( POS ) è un metodo per analizzare grammaticalmente un testo in modo automatico, tramite un software o un algoritmo informatico, e agevolare la comprensione dell'informazione.
E' un metodo utilizzato nell'Information Retrieval ( IR ), nel Text Mining e nell'intelligenza artificiale.
L'analisi grammaticale automatica del testo
Il testo viene dapprima suddiviso in frasi e proposizioni. Le proposizioni sono, a sua volta, trasformate in vettori sequenziali di parole.
Ogni singola parola viene confrontata con una base dati esterna, in cui sono contenuti i possibili termini del discorso.
Cos'è un termine?
Un termine è un insieme di parole ( token ) o di radici ( stem ). Gli elementi dell'insieme possono essere ordinati o meno.
- Gruppo ordinato. Le parole sono suddivise in base alla funzione che svolgono in una frase. Ad esempio, sostantivo o aggettivo. In questo caso, l'ordine dei token nell'elenco veicola un'informazione aggiuntiva. In alternativa, si può usare un tag grammaticale ( es. /V, /N, ecc. ).
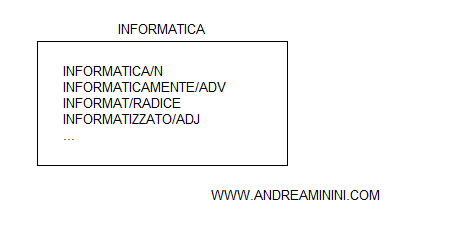
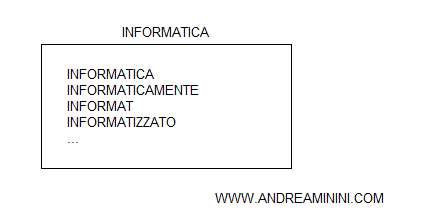
- Gruppo non ordinato. Le parole sono contenute nella lista del termine senza alcuna indicazione aggiuntiva sulla loro funzione e senza alcun ordine particolare.
Nota. L'etichettatura è più difficile nel caso dei titoli, in quanto sono spesso sintetici o stringati e quasi privi di una struttura grammaticale o, comunque, usano una struttura differente rispetto a quella di una frase normale.
L'etichettatura o tagging delle parole
La gestione dei token consente l'etichettatura ( tagging ) delle parole contenute in una frase o delle principali parti o frammenti del discorso ( part of speech ).

Una volta associata a ogni parola o segmento del testo una possibile funzione lessicale, è più facile risalire alla struttura grammaticale del testo.
Come etichettare le parole
Il tag può essere aggiunto alla fine della parola dopo un simbolo separatore ( es. slash / ) sotto forma di lettera maiuscola.
- /ADJ = aggettivo
- /A = articolo
- /ADV = avverbio
- /CNJ = congiunzione
- /UH = interiezione
- /P = preposizione
- /PRO = pronome
- /N = sostantivo
- /V = verbo
Esempio. La frase "il cane abbaia" può essere riscritta nella seguente forma "il/A cane/N abbaia/V".
Il tagging può anche essere più specifico. Ad esempio, è possibile specificare il tipo di verbo aggiungendo un'ulteriore lettera al tag ( es. /VD ) oppure un nuovo tag ( es. /MOD ):
- /VD = passato
- /VG = participio presente
- /VN = participio passato
- /MOD = verbo modale
In alternativa, l'etichettatura del testo può essere effettuata tramite le meta-informazioni del linguaggio XML ( eXtensible Markup Language ) o di qualsiasi altro linguaggio di web semantico.
Nota. Un altro problema riguarda le parole isolate nel testo, quelle poste tra parentesi o negli elenchi puntati. In questi casi, è più difficile risalire alla loro funzione grammaticale all'interno del testo.




