La storia dei contenuti di bassa qualitÓ
I contenuti di scarsa qualità su internet sono sempre esistiti. Nel corso degli anni duemila si è diffuso un modo di scrivere per il web o, per meglio dire, scrivere per i motori di ricerca e i social network.
Le tecniche di scrittura per i search engine
Le vecchie tecniche di scrittura per i motori di ricerca facevano molto leva sul titolo del documento ( tag title ).
Si scriveva un pezzo dal titolo originale, inserendovi dentro delle keyword molto ricercate, per ottenere un grande flusso di traffico dalle ricerche sui search engine.
A parte l'ottimizzazione delle keyword, però, il contenuto semantico di un articolo era privo di qualsiasi informazione utile per il lettore ed era infarcito di messaggi pubblicitari, appositamente ben camuffati, per indurlo a cliccarvi sopra per errore o perché ingannato.
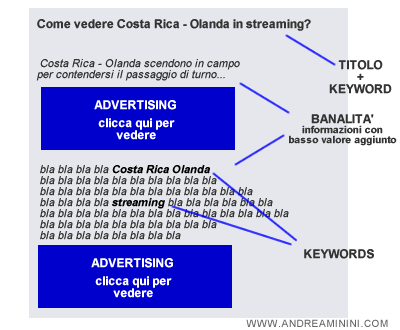
Queste tecniche ingannevoli di comunicazione online furono utilizzate inizialmente dai blogger per aumentare la visibilità del proprio blog su Google e monetizzare i click tramite i guadagni provenienti dagli annunci contestuali Adsense.
Si trattava di pratiche e strategie editoriali predatorie di breve periodo. Il motore di ricerca, prima o poi, avrebbe finito col declassare la reputazione (R) del blog o del suo autore, riducendo il suo trust e impedendo così che si posizioni nuovamente ai primi posti sulle SERP.
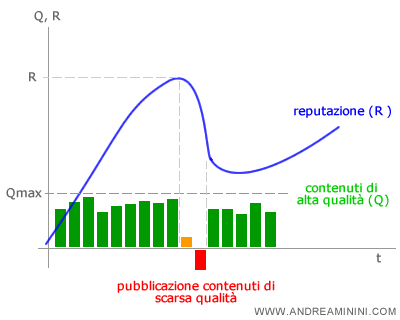
Per individuare questi contenuti ingannevoli è sufficiente analizzare il tempo e tasso di rimbalzo da un risultato per comprendere il grado di soddisfazione di un sito, eliminano dalle SERP tutti quei siti che adottano tecniche fraudolente per trattenere l'utente, come la disabilitazione del tasto back del browser, il refresh immediato o il redirect automatico.
Negli ultimi anni queste tecniche sono utilizzate anche dalle grandi testate giornalistiche e non più soltanto nei blog. Sempre più di frequente anche sui giornali online si incappa in notizie farlocche o titoli ingannevoli per conquistare il traffico e qualche click sugli annunci pubblicitari.
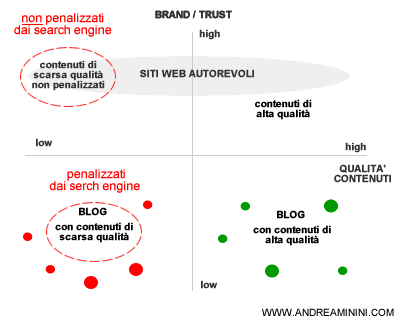
Mentre un blog può essere declassato dal quality manager di passaggio... il sito autorevole di una grande testata giornalistica non sarà mai penalizzato o punito per queste tecniche. Nessun quality manager oserebbe mai declassare il sito web di una grande testata.
Così facendo, il web è sempre più sporco. Il trust non garantisce più la qualità dei risultati a causa di un evidente asimmetria nella gestione delle penalizzazioni da parte dei motori di ricerca che spesso chiudono un occhio sulle pratiche scorrette dei siti web più noti o autorevoli.
E gli indicatori sociali? Inutili o quasi. Nessun motore di ricerca serio dovrebbe mai considerare i segnali provenienti dai social network. I social network sono ormai il "regno dei gattini", un posto ove la qualità dei contenuti raggiunge il livello più basso e le tecniche di like baiting spopolano.
Quanto più una notizia è farlocca, stramba e originale, anche a costo di essere falsa, tanto più è ricondivisa. Se questo non fosse sufficiente... basterebbe pubblicare un post con la foto di un cucciolo o di un gattino per ottenere migliaia di like dalle persone più sensibili e costruirsi così una sorta di autorevolezza sociale-virtuale.
Se nemmeno questo bastasse... beh... gli amici e i segnali sociali ( +1, like, follower, ricondivisioni, ecc. ) sui social network si possono anche acquistare. L'industria del like è una realtà nota e conosciuta a tutti. Per tutte queste ragioni gli indicatori sociali non dovrebbero influenzare i risultati di un motore di ricerca o, perlomeno, essere relegati in un apposito criterio di selezione della ricerca per tipologia di fonte.
Come risolvere il problema? Il fattore umano dei quality manager andrebbe ridimensionato o limitato a casi particolari, poiché il giudizio critico di una persona è soggettivo e facilmente manovrabile. Il peso del trust andrebbe fortemente limitato.
La link popularity è ormai inefficace, la popolazione dei SEO specialist è cresciuta a vista d'occhio e oggi gran parte dei collegamenti ipertestuali sono link non naturali. Dal punto di vista degli algoritmi andrebbero abbandonate le euristiche, quelle regole che giudicano la qualità della pagina da una serie di elementi. In pratica... un'euristica è come un amico pigro che ti consiglia un libro senza averlo mai letto, soltanto perché la casa editrice è nota, l'autore è famoso o la copertina è ben fatta.
Gli algoritmi devono imparare a leggere e comprendere ciò che viene scritto, capire il significato delle frasi e riconoscere le cavolate... quando sono scritte. Non è fantascienza, è già possibile farlo... questi algoritmi intelligenti sono già esistenti ma richiedono più risorse macchine per essere elaborati, in quanto elaborano il linguaggio naturale. Perché i motori di ricerca non li adottano? Probabilmente, l'attuale situazione di monopolio-oligopolio nel settore dei search engine consente ai motori di ricerca di concedersi il lusso di avere le SERP di medio-scarsa qualità. 08 / 07 / 2014




