Come trovare i tag html con regex
Può capitare di dover selezionare soltanto i tag del linguaggio HTML in un documento.
Per farlo si può utilizzare questa espressione regolare.
<[^>]+>
La regex si basa sull'utilizzo di un set di caratteri che esclude il simbolo > di chiusura dalla selezione e da un quantificatore +.
Un esempio pratico
Nel seguente testo è presente un documento ipertestuale con alcuni tag Html.
Come è già noto, i tag del linguaggio Html possono avere lunghezze differenti ( es. <p>, <html>, <ul>, ecc. ).
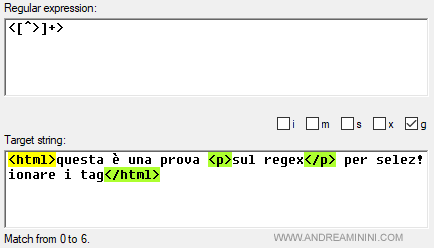
L'espressione regolare seleziona esclusivamente i tag html, lasciando stare tutto il resto.
Inoltre, nel matching la regex individua sia i tag minuscoli che maiuscoli o misti. E' un gran vantaggio.
Nota. L'espressione seleziona anche gli eventuali attributi posti all'interno del tag.
Come funziona l'espressione
L'espressione regolare individua le parti del testo comprese tra il simbolo < e >.
Poi grazie al quantificatore + seleziona tutto ciò che è compreso tra < e >.
Nota. Il set di caratteri [^>] è invece necessario per far terminare la selezione al primo simbolo di chiusura. Se scrivessi semplicemente l'espressione <.+>, la regex selezionerebbe tutto il testo dall'inizio fino all'ultimo simbolo di chiusura > dell'ultimo tag.




