Il profiling in Python
Il profiling mi permette di analizzare il numero di chiamate e il consumo di tempo / risorse delle singole righe di codice di uno script Python.
A cosa serve? Mi consente di ottimizzare uno script. Una volta individuati i colli di bottiglia, le istruzioni che rallentano l'esecuzione dello script, posso rimuoverle o gestire il flusso di elaborazione in modo diverso. E' uno strumento utile per migliorare l'efficienza e ridurre la complessità computazionale di un algoritmo.
Un esempio pratico
Sviluppo un semplice script che calcola e stampa la radice quadrata dei numeri da 1 a 1000 con la funzione sqrt() e con l'elevazione a potenza (**1/2).
I due metodi forniscono lo stesso risultato.
- from math import sqrt
- for n in range(1,1000):
- r2 = (sqrt(n))
- r3 = (n**(1/2))
- print(n,r2,r3)
Salvo lo script dandogli il nome prova.py.
A questo punto, per fare il profiling apro il prompt del sistema operativo (dos o linux) ed eseguo lo script con l'opzione cProfile
C:\>python -m cProfile -s cumulative prova.py
L'interprete Python esegue lo script.
Al termine dell'esecuzione visualizza il report di profiling.
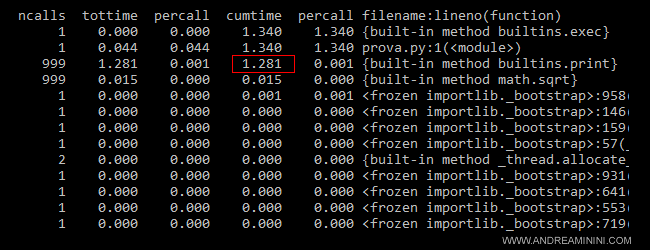
Il report di profiling è composto dalle seguenti informazioni:
- ncall = il numero delle esecuzioni della riga
- tottime = il tempo totale di esecuzione in secondi
- percall = la percentuale del tempo rispetto al totale
- cumtime = il tempo cumulato di esecuzione in secondi
- percall = la percentuale del tempo cumulato rispetto al totale
- filename:lineno = il numero di riga
E' subito evidente che l'istruzione print rallenta l'esecuzione dello script.
Il tempo cumulato di esecuzione della riga print è 1,281 secondi su 1,340 secondi complessivi dello script.
Nota. Se togliessi la print dallo script il tempo di esecuzione diventerebbe soltanto 0,002 secondi. E' un bel miglioramento in termini di complessità temporale.
Come fare il profiling su una funzione
Posso eseguire il profiling anche su una singola funzione dello script.
Devo soltanto importare il modulo cProfile ed eseguire il controllo cProfile.run sulla funzione che mi interessa.
import cProfile
cProfile.run('nomefunzione()')
L'istruzione cProfile.run va inserita dopo la definizione della funzione.
In questo modo, posso effettuare il controllo di profiling soltanto sulla funzione indicata, senza analizzare il resto dello script.
Esempio
- from math import sqrt
- def pippo():
- for n in range(1,1000):
- r2 = (sqrt(n))
- r3 = (n**(1/2))
- print(n,r2,r3)
- import cProfile
- cProfile.run('pippo()')
Poi eseguo il programma dal prompt del sistema operativo oppure dall'interprete.
Il risultato è il profiling sulla singola funzione pippo()
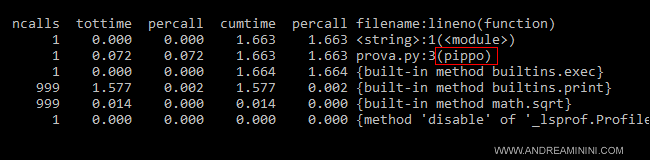
E così via.




