L'algoritmo MDP con ricompense scontate
L'algoritmo MDP con ricompense scontate analizza una sequenza di decisioni per valutare l'utilità attesa di una politica, attribuendo un peso maggiore alle prime decisioni e progressivamente minore alle decisioni successive.
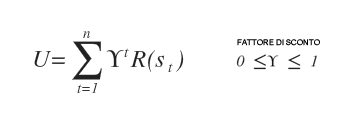
In ogni turno la ricompensa R(st) ottenuta nello stato st viene moltiplicata per un fattore di sconto γt compreso tra 0 e 1 ed elevato a potenza con esponente pari al numero dei passi (t).
A cosa serve?
Se il fattore γ è inferiore a 1, il fattore di sconto si riduce col passare del tempo, rendendo progressivamente meno utili i passi successivi rispetto ai precedenti.
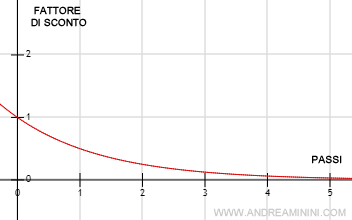
Preferenze non stazionarie. Se il fattore di sconto è inferiore a 1, ad esempio y=0.5, le ricompense iniziali sono più importanti delle successive. Questo causa la non stazionarietà delle preferenze.
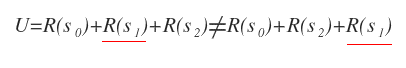
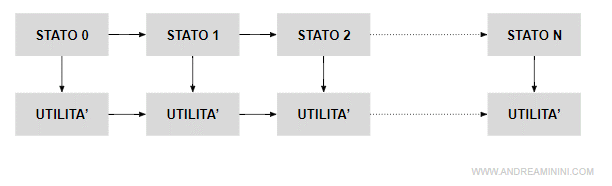
Le preferenze non sono stazionarie perché l'utilità di uno stato S della sequenza cambia in base alla posizione nella sequenza decisionale. Pertanto, non si può affermare che uno stato sia sempre preferibile a un altro.
I vantaggi del metodo delle ricompense scontate
Il metodo ricompense scontate ha diversi vantaggi negli algoritmi MDP ( Markov Decision Process ) rispetto al metodo delle ricompense additive, perché trasforma una sequenza decisionale infinita in una sequenza finita.
Se la sequenza di decisioni è molto lunga, con il metodo additivo l'utilità attesa tende a infinito.
Questo causa un problema. E' infatti impossibile confrontare due sequenze che tendono entrambe a infinito.
Inoltre, se non esiste una soluzione ( stato terminale ) l'agente entra in un loop senza fine, consumando inutilmente tempo e risorse per elaborare una sequenza infinita di passi.
Nota. Quando una politica non raggiunge mai uno stato terminale è detta politica impropria. Viceversa, se la raggiunge è detta politica propria.
Il metodo delle ricompense scontate, invece, riduce progressivamente l'utilità addizionale del passo successivo, rendendola sempre più piccola.
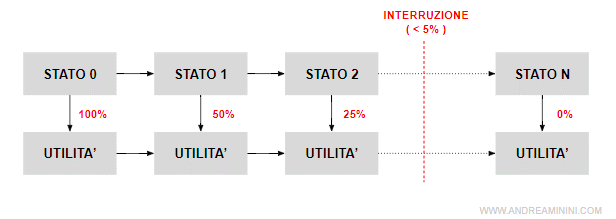
Quando l'utilità scontata aggiuntiva diventa troppo piccola ( es. γt=0.05 ossia 5% ) l'agente può interrompere anticipatamente il processo di ricerca, evitando così di elaborare altri passi con valori infinitesimali.
In questo modo, l'agente ottiene un valore approssimativo dell'utilità della politica che sta esaminando ma risparmia tempo e risorse.
Il metodo delle ricompense scontate ha eliminato il rischio di incappare in un loop infinito e ha migliorato l'efficienza computazionale dell'algoritmo.




