Un problema MDP parzialmente osservabile ( POMDP )
Un problema POMDP è un processo decisionale di Markov ( MDP) in un ambiente parzialmente osservabile ( PO ). In questi casi, l'agente non conosce il proprio stato corrente.
Un esempio pratico. L'agente deve arrivare alla casella C2 ma l'ambiente è parzialmente osservabile. Ad esempio, è al buio. Quindi, l'agente non conosce la sua posizione nella mappa, né quali azioni consentono di raggiungere l'obiettivo.
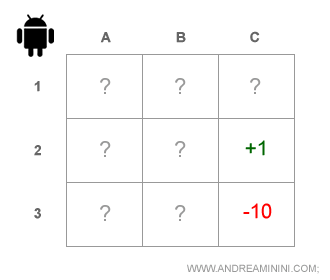
E' un tipico problema non deterministico in cui la soluzione va cercata tramite un modello probabilistico.
La differenza tra MDP e POMDP
In un problema MDP l'agente conosce in quale stato si trova.
Quindi, per trovare la politica ottimale π(s), l'agente fa direttamente riferimento al proprio stato reale s.
L'agente si limita a eseguire la politica raccomandata per lo stato corrente.
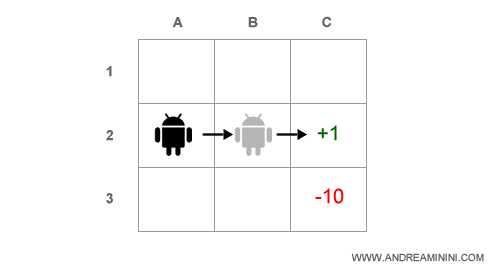
In un problema POMDP parzialmente osservabile, invece, l'agente non conosce lo stato s in cui si trova.
Nota. Nel problema POMDP l'agente non sa di trovarsi nella casella C2. In base all'osservazione diretta, l'agente sa di trovarsi in una casella di confine con un solo muro e di non aver raggiunto la casella obiettivo C2. Quindi, l'agente potrebbe trovarsi anche in B1 o in B3.
In questi casi, la politica ottimale π dipende dagli stati credenza.
L'agente ipotizza una distribuzione di stati possibili in cui potrebbe trovarsi ( stati credenza ) e associa a ciascuna una probabilità.
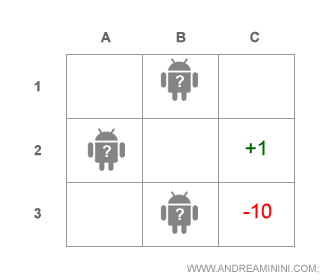
Nota. Nella precedente situazione l'agente ha tre stati credenza ( A2, B1 , B3 ). Ogni stato credenza ha una probabilità del 33%.
Per decidere l'agente deve ridurre l'incertezza con la raccolta di informazioni aggiuntive tramite l'aggiunta di un modello sensoriale delle osservazione.
Quindi un problema POMDP è decisamente più difficile dei problemi MDP.
Il modello POMDP
Il processo POMDP ( pomdipi ) è composto da un modello di transizione, una funzione di ricompensa e un modello sensoriale.
Nota. Si distingue dal processo MDP per l'aggiunta del modello sensoriale ( o modello delle osservazioni ).
A cosa serve il modello delle osservazioni?
Il modello delle osservazioni fornisce le probabilità degli stati (s) a partire dall'osservazione (o).
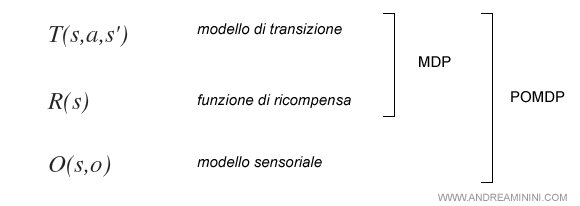
In base alle azioni effettuate dall'agente (a) e dall'osservazione corrente della situazione (s), il modello delle osservazioni elabora una distribuzione delle probabilità degli stati.
C'è però un'altra differenza importante rispetto al modello MDP da considerare. Nel modello POMDP L'agente non conosce con certezza lo stato corrente (s) ossia la posizione (s) in cui si trova.
Quindi, il modello di transizione non può essere tra lo stato corrente e lo stato successivo T(s,a,s').
Nel modello POMDP il modello di transizione è tra lo stato credenza corrente, ossia dove l'agente potrebbe trovarsi, e lo stato corrente successivo T(b,a,b').

Cos'è lo stato credenza?
Lo stato credenza b è una distribuzione di probabilità.
Ogni elemento dello stato credenza b(s) indica la probabilità p(s) che l'agente si trovi in un determinato stato (s) ossia posizione della mappa.
Il nuovo modello di transizione T(b,a,b') è il seguente:
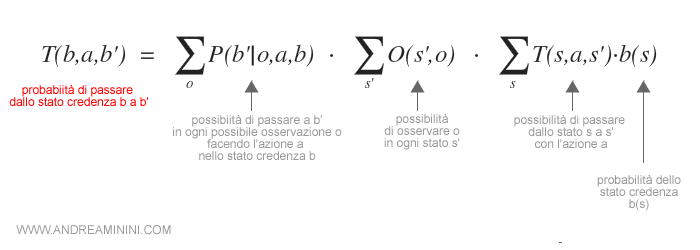
Questo modello di transizione calcola la probabilità di passare dallo stato credenza b a b' compiendo l'azione a.
In conclusione, per risolvere un problema POMDP nello spazio degli stati fisici, si può trasformare il problema in un MDP nello spazio degli stati credenza.
Un esempio pratico
L'agente deve raggiungere l'obiettivo nella casella C2 ed evitare la trappola nella casella C3.
L'ambiente è parzialmente osservabile, quindi l'agente non conosce la sua posizione nella mappa.
Non conoscendo in quale casella si trova, l'agente non può decidere una politica ottimale.
Inoltre, l'agente è al buio e non vede nulla intorno a sé.
Secondo il modello delle osservazioni la distribuzione delle probabilità è la seguente:
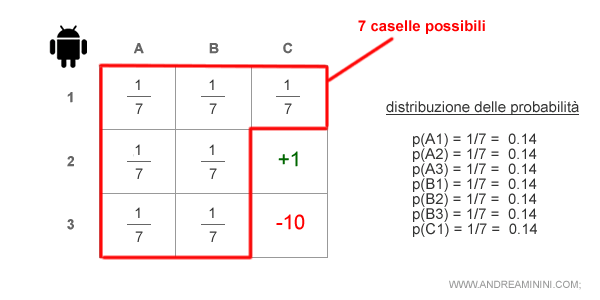
La probabilità di trovarsi nella casella A1 è uguale a 1/7 ossia p=0.14.
La stessa probabilità ( 14% ) si ha anche nelle caselle A2, A3, B1, B2, B3 e C1.
Nota. Nel computo escludo le caselle C2 (obiettivo) e C3 (trappola) perché se fosse là l'agente se ne accorgerebbe. Quindi la probabilità di trovarsi in queste due caselle è zero. Per questa ragione la probabilità è una su sette pur essendo nove le caselle della mappa.
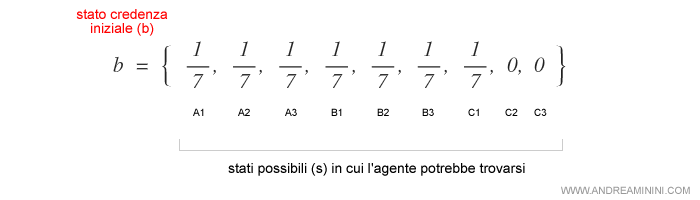
Questa distribuzione di probabilità rappresenta lo stato credenza iniziale (b).
Per decidere la mossa da compiere si utilizza un algoritmo simile a quello del filtraggio ( monitoring ).
Dato lo stato credenza corrente l'agente decide l'azione migliore possibile (a).
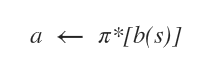
In questo caso l'azione ottimale (a) dipende dallo stato-credenza perché l'agente non conosce la casella in cui si trova.
Nota. Nei problemi MDP invece l'azione ottimale dipende dallo stato corrente perché l'agente sa esattamente dove si trova nella mappa.
Dopo aver attuato l'azione ottimale (a), l'agente si sposta dallo stato s allo stato s' (stato di credenza successivo).
A questo punto l'agente osserva l'ambiente circostante per aggiorna le informazioni del modello sensoriale O.
Poi calcola il nuovo stato credenza b'(s') tramite la seguente formula:
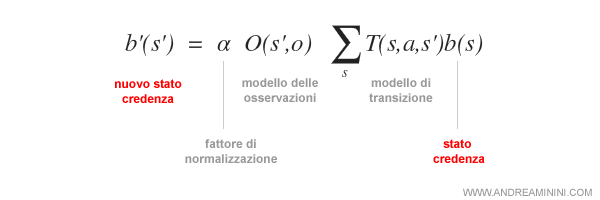
Ad esempio, l'agente si sposta a destra (a) giungendo su una nuova casella.
Nella nuova casella non ha osservato (o) né il traguardo, né la trappola.
Quindi, secondo il modello delle osservazioni (O), adesso l'agente dovrebbe trovarsi in B2, B3, B4 o C1.
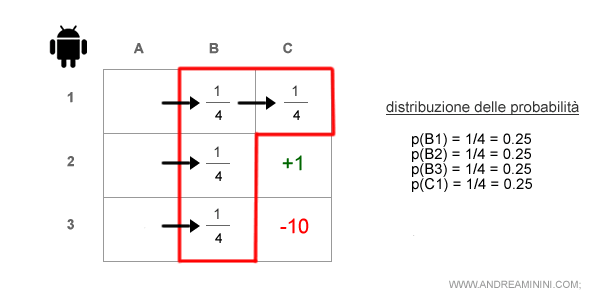
Nota. L'agente esclude A1, A2, A3 perché non potrebbe raggiungerle spostandosi a destra. Così facendo ha ottenute nuove informazioni sulla sua posizione reale.
Il nuovo stato credenza è b(s') è composto da quattro caselle possibili { B1, B2, B3, C1 }.
Ogni casella dello stato credenza ha una probabilità pari a 1/4 ossia 0.25 ( p=25% ).
Come decide l'agente?
Quando l'agente deve decidere come muoversi, non conosce ancora le conseguenze dell'azione.
Quindi non può accedere alle osservazioni (o) sullo stato successivo s'.
Si potrebbe pensare che la scelta di una direzione sia casuale. In realtà, non è così.
L'agente deve scegliere l'azione (a) che conduce dallo stato credenza attuale b(s) al migliore dei possibili stati credenza possibili successivi b(s').
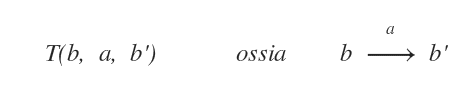
Abbiamo trovato il modello di transizione.
Ora scriviamo anche la funzione di ricompensa in funzione dello stato credenza.
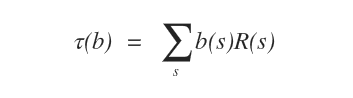
Possiamo così trasformare il modello POMDP in un modello MDP sugli stati credenza.
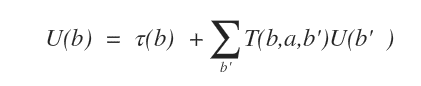
Per capire quali stati-credenza sucessivi (b') sono possibili, l'agente deve analizzare le azioni possibili a partire dallo stato-credenza attuale (b).
Le azioni possibili sono le seguenti:
- spostarsi a destra
- spostarsi a sinistra
- spostarsi in alto
- spostarsi in basso
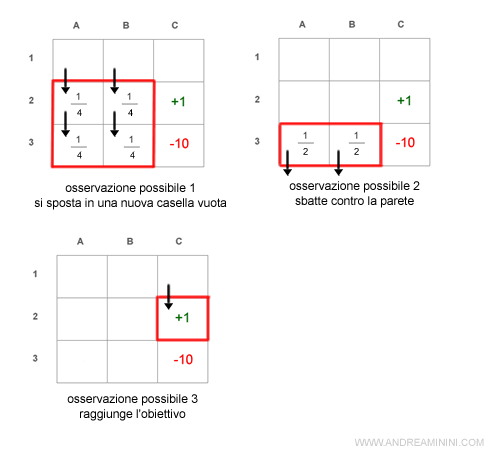
Se l'agente scegliesse di spostarsi a destra avrebbe le sequenti possibili osservazioni:
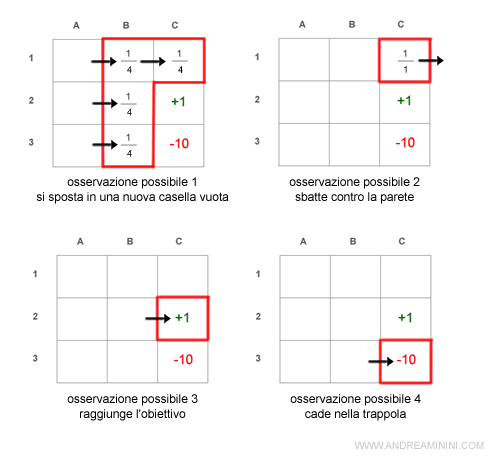
Se si spostasse a sinistra avrebbe una le seguenti osservazioni:
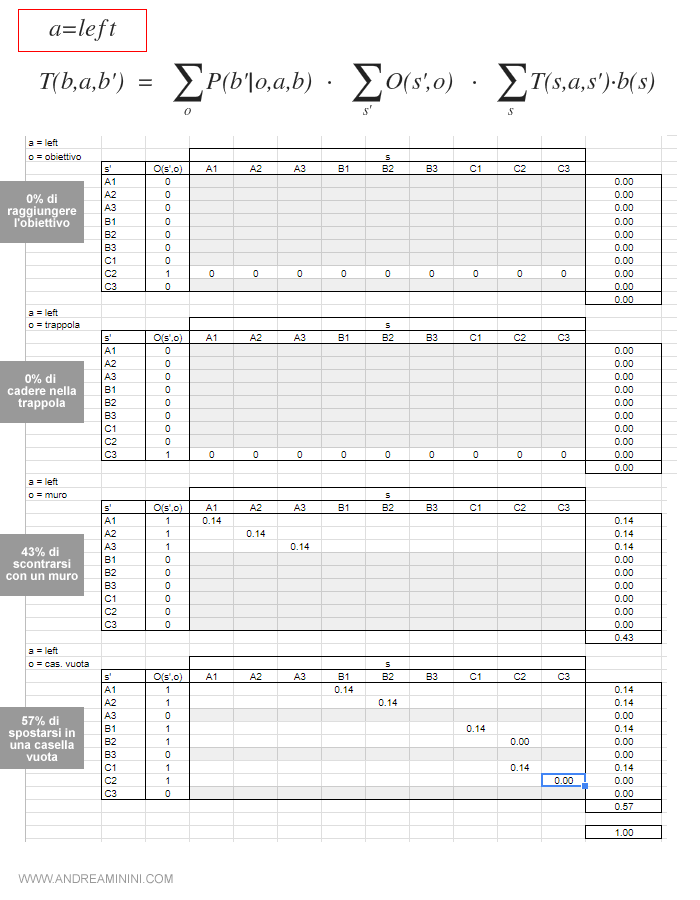
Nota. In questo caso non potrebbe osservare né di raggiungere l'obiettivo, né la trappola, perché sono logicamente impossibili da trovare spostandosi a sinistra.
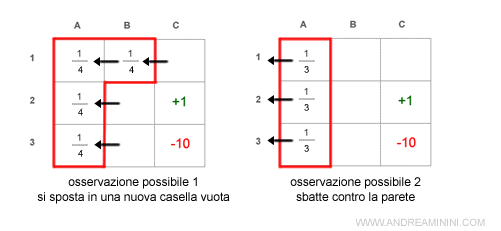
Se invece si spostasse in alto avrebbe le seguenti osservazioni
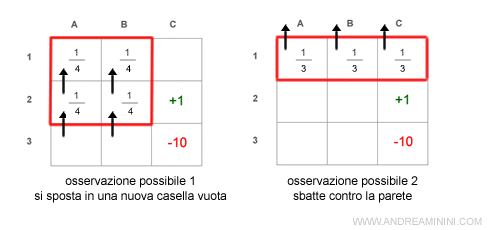
Infine, se si spostasse in basso avrebbe le seguenti osservazioni:
Il passo 1
L'agente decide il primo spostamento.
Secondo lo stato credenza iniziale, l'agente potrebbe trovarsi in una delle sette caselle ( A1, A2, A3, B1, B2, B3, C1 ) con pari probabilità ( p=1/7=0.14 ).
Le osservazioni possibili dopo la mossa sono le seguenti:
- L'agente si sposta in una casella vuota
(16 possibilità) - L'agente si sposta nella casella obiettivo (C2)
(2 possibilità) - L'agente si sposta nella casella trappola (C3)
(1 possibilità) - L'agente non si sposta a causa di un muro
(9 possibilità)
Nota. Quando deve decidere, l'agente non può ancora osservare il feed-back dell'azione. Quindi, considera tutte le possibili osservazioni possibili.
Se l'agente decidesse di spostarsi verso il basso ( azione = down ) avrebbe le seguenti probabilità di osservare questi eventi:
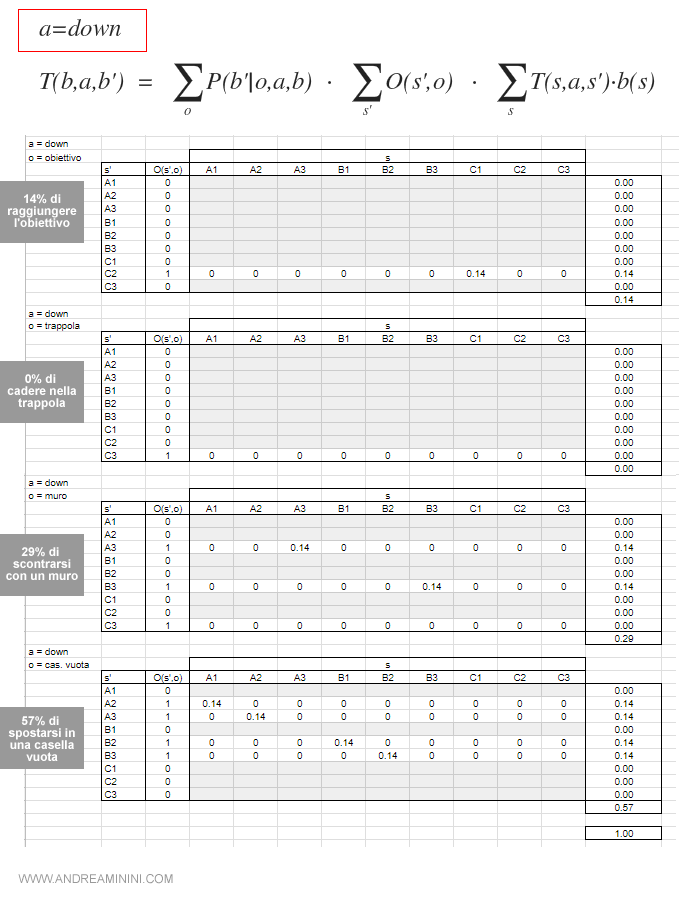
Nota. Per spiegare il procedimento di calcolo prendo come riferimento la prima tabella. Secondo il modello delle osservazioni O(s',o) , l'agente può osservare di raggiungere l'obiettivo (o) solo quando si trova effettivamente nella casella C2. Quindi soltanto questa possibilità è uguale a 1 nella colonna O(s',o). Analizzando gli stati possibili di provenienza (s), la casella C2 (s') è raggiungibile con uno spostamento verso il basso (a=down) soltanto dalla casella C1 (s). Quindi T(s,a,s') è uguale a 1 soltanto per s=C1 quando a=down e s'=C2. La probabilità dello stato credenza b(s) in C1 è uguale a 1/7 ossia 0.14. Essendoci soltanto questa possibilità, la sommatoria è uguale a 0.14. Quindi, la probabilità di raggiungere l'obiettivo con uno spostamento verso il basso nello stato credenza iniziale è pari al 14%.
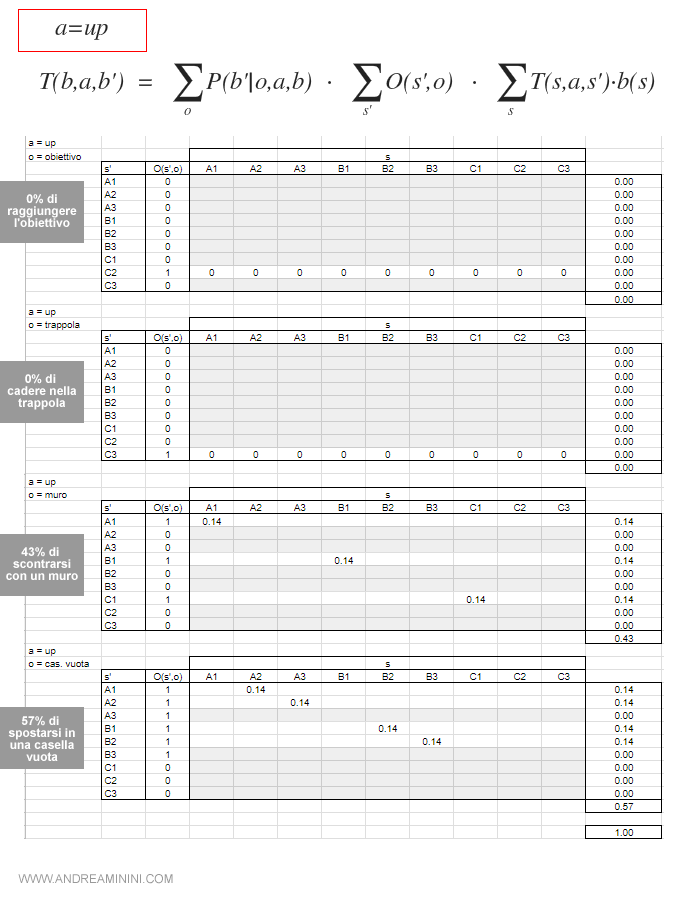
Se invece si spostasse verso l'alto ( azione = up ) le probabili osservazioni sarebbero le sequenti:
Se si spostasse a sinistra ( a = left )
Se si spostasse a destra ( azione = right ) avrebbe le seguenti probabilità di evento
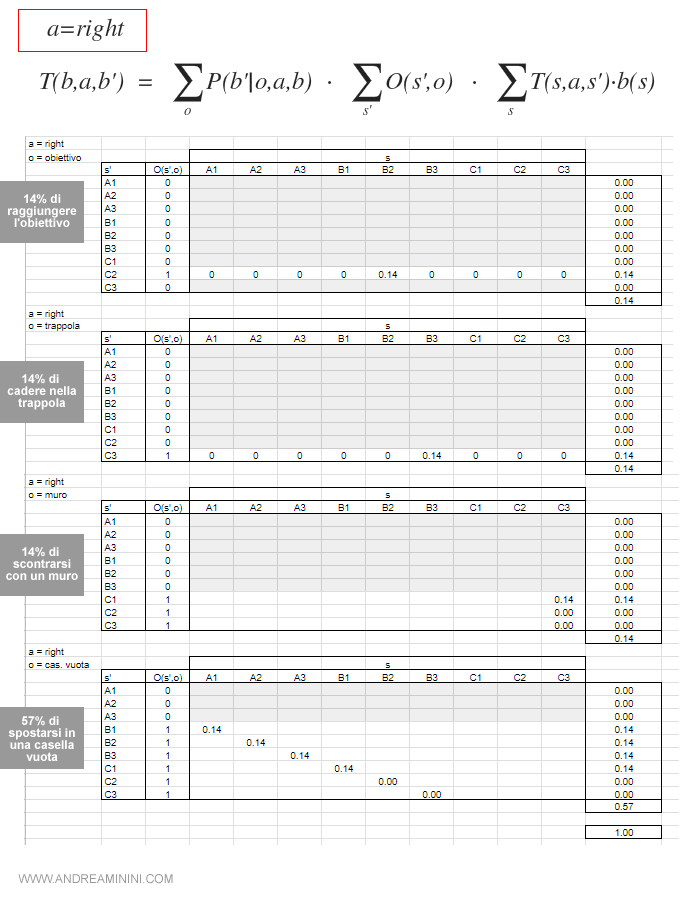
Ricapitolando, le probabilità delle possibili osservazioni (o) dopo la prima azione (a) nel modello di transizione T(b,a,b') sono le seguenti

A questo punto bisogna calcolare la funzione di ricompensa per ogni stato credenza R(b).

All'agente converrebbe muovere verso il basso ( a=down ) perché è l'azione che massimizza l'utilità attesa.
Dopo la mossa, l'agente riaggiorna lo stato di credenza attuale considerando le osservazioni rilevate dopo l'azione e così via.
Esempio. Se dopo lo spostamento verso il basso l'agente incontra il muro, il nuovo stato credenza diventa il seguente:
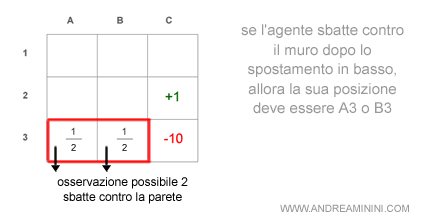
Il procedimento per decidere la seconda mossa è simile alla prima.
Tuttavia, nei passi successivi l'agente ha più informazioni sulla sua posizione.
Quindi, passo dopo passo, la politica ottimale del modello POMDP tende a eguagliare quella di un modello MDP.
Nota. La sequenza di azioni per raggiungere l'obiettivo nel precedente modello POMDP è down + up + right ( + right ). In tre o quattro mosse l'agente raggiunge l'obiettivo.

L'agente non conosceva la sua posizione iniziale nella mappa ma, basandosi sugli stati-credenza, è riuscito comunque a risolvere il problema, riducendo al minimo i costi e i rischi dell'esplorazione ( raccolta delle informazioni ).




