La ricerca semantica
La ricerca semantica, o semantic search, è un nuovo approccio IR per trovare informazioni in un database. Qual'è la sua caratteristica? Non utilizza soltanto le parole chiave ma anche la semantica e approfondisce il significato dei termini.
La cosa migliore per comprendere la ricerca semantica è fare un esempio pratico e vedere come funzionava la ricerca classica di un vecchio motore di ricerca.
La ricerca classica: un esempio di funzionamento
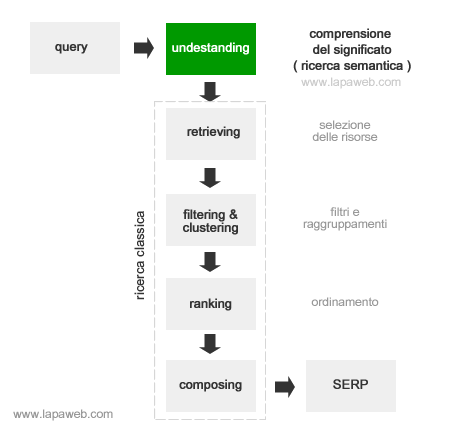
Un motore di ricerca per keyword prende in input la parola chiave digitata dall'utente nella richiesta ( query ), verifica quali documenti la contengono e li elenca in una pagina dei risultati ( serp ) secondo un particolare ordine.
Tutti i documenti elencati hanno una caratteristica, quella di includere al loro interno la parola chiave indicata dall'utente nella sua query di ricerca.
Ora, non ci interessa sapere come il search engine ordini le risorse dalla prima all'ultima, quello che dobbiamo ricordare è soprattutto il fatto che tutte presentano una coincidenza letterale con la parola chiave ( exact matching ).
Quali erano i limiti della ricerca classica?
Nella ricerca classica ogni parola è indipendente da tutte le altre, compresi i sinonimi, le forme di genere, il singolare o il plurale della stessa parola.
Ad esempio, supponiamo che l'utente digiti due query "come fare un sito" e "come fare i siti". Pur essendo molto simili, la ricerca classica genera due serp diverse.
Nella prima pagina dei risultati l'algoritmo seleziona le risorse con i vocaboli come+fare+sito, mentre nella seconda seleziona quelle con la combinazione come+fare+siti.
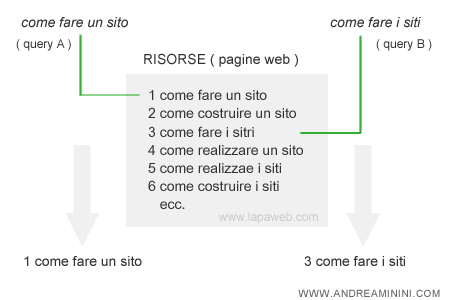
La differenza è soltanto la parola "sito" che nella prima query è al singolare ( sito ) e nella seconda è al plurale ( siti ).
Per semplificare l'esempio non ho preso in considerazione gli articoli nelle query, così come facevano i vecchi search engine che li consideravano dei termini da escludere, conosciuti anche come stop-word.
Volendo fare un altro esempio, proviamo a scrivere altre due query. Nella prima digitiamo "come fare un sito" e nella seconda "come realizzare un sito".
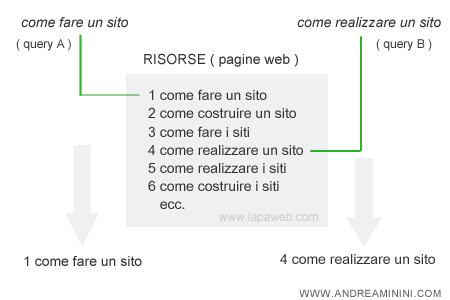
Anche in questo caso le due query sono simili. Cambia soltanto il verbo all'infinito ( fare o realizzare ) ma tutto il resto è uguale. Un algoritmo di ricerca classica le considera differenti ed estrapola nei risultati delle risorse differenti.
Nella prima serp presenta le risorse che contengono "fare" e nella seconda quelle che contengono "realizzare". Le pagine estrapolano risorse differenti pur rispondendo al medesimo bisogno dell'utente, quello di ottenere informazioni su come costruire un sito web.
Ne consegue che per essere presenti sul search engine su tutte le query che avevano lo stesso significato, un editore era costretto a creare un moltitudine di pagine web duplicate o con contenuto simile, ognuna delle quali era ottimizzata per un particolare termine ( es. fare, realizzare, costruire, ecc. ).
L'editore per ottimizzare una risorsa ne doveva produrre molte, a rischio di subire una penalizzazione per contenuti duplicati, poiché le pagine erano molto simili tra loro, si distinguevano solo per poche parole chiave. Era un po' frustrante.
La ricerca semantica: come funziona?
Vediamo ora come funziona una ricerca semantica. Come abbiamo detto all'inizio, l'algoritmo non ragiona più sulla keyword letterale ma sul significato della parola.
Prendiamo gli stessi esempi già fatti per la ricerca classica. Quando l'utente digita una query fornisce al search engine una combinazione di parole chiave in input.
Il motore di ricerca analizza il campo semantico di ciascuna parola, cercando di individuare tutte le altre parole pertinenti con i termini.
Così facendo, il motore di ricerca si accorge che le parole "sito" e "siti" sono la stessa cosa. Non solo, si accorge anche che i verbi "fare" o "realizzare" hanno lo stesso significato. Questo processo si chiama espansione del campo semantico.
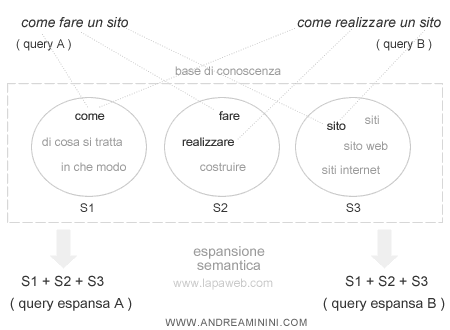
Come fa a capire il significato? Si avvale di una base di conoscenza, un database in cui sono registrate tutte le parole, le relazioni delle parole e le entità ( concetti ).
Riprendendo il nostro esempio, il search engine si accorge che le query A e B utilizzano gli stessi concetti S1+S2+S3. Sono query diverse ma hanno lo stesso significato. A questo punto, sostituisce le query iniziali con le query espanse.
A questo punto, il motore di ricerca può selezionare tutte le risorse che hanno una coincidenza con il campo semantico espanso della query.
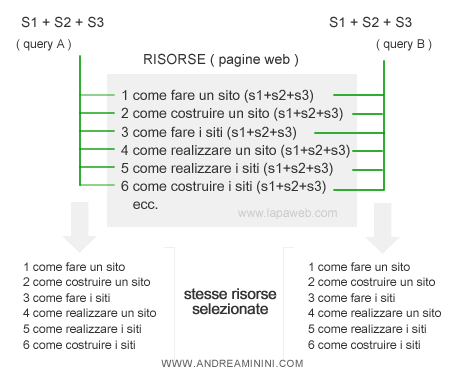
Come si può vedere nella figura precedente, ora l'algoritmo seleziona risorse anche con parole chiave diverse dalla query iniziale. Le risorse selezionate hanno lo stesso significato ma una forma diversa.
Una volta selezionate le risorse, il processo è identico alla ricerca classica ( retrieving, filtering, clustering, ranking, composing ). Le risorse selezionate sono ordinate secondo un criterio di merito che non ci interessa analizzare. .
Possiamo scrivere "come fare" o "come realizzare", abbiamo comunque davanti gli stessi risultati o, perlomeno, delle pagine dei risultati molto più simili tra loro.
In alcuni casi potremmo persino avere delle risorse che non contengono al loro interno le parole chiave usate nella nostra query, ma altri termini pertinenti. È un bel passo avanti, non c'è dubbio.
La selezione della ricerca semantica è molto più ampia ed è molto più probabile trovare dei risultati di qualità, i quali ora appaiono su tutte le query simili, ed evitare lo spam.
In particolare, scompaiono dalle Serp tutte le pagine di scarsa qualità che agiravano la concorrenza sul search engine puntando soprattutto sulle differenze letterali delle keyword nelle long tail.
In conclusione
Questa pagina è soltanto un esempio di come può funzionare la ricerca semantica. In realtà, i processi e gli aspetti tecnici della Semantic Search sono molto più complessi rispetto a come li ho presentati.
Tuttavia, spero sia un buon punto di partenza per capire cos'è la ricerca semantica e per approfondire tutti gli altri aspetti, come le entità, la pertinenza e le basi di conoscenza. 17 / 03 / 2015
- IR significa Information Retrieval, è la disciplina informatica che si occupa si studiare le tecniche di selezione e di reperimento delle informazioni in un database.




