L'analisi automatica dei testi
Cos'è l'analisi automatica del testo
L'analisi automatica dei testi è un'operazione di text data mining che consiste nel trovare delle informazioni utili in un testo tramite un algoritmo. Si parte da una collezione di testi o di documenti da analizzare. In gergo è detto "corpus".
Normalmente i testi riguardano un argomento particolare o una materia, in modo da circoscrivere il vocabolario intorno a un tema.
E' preferibile utilizzare testi scritti usando le stesse regole di sintassi. Facilita l'analisi ma non sempre è possibile.
Come funziona un linguaggio
Il linguaggio naturale è una sequenza di stringhe composte da parole che segue un insieme di regole ( grammatica ).

Ogni stringa può essere associata a uno o più significati ( semantica ).
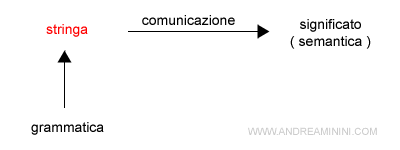
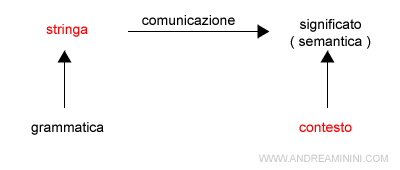
Tuttavia, la formalizzazione del linguaggio naturale è molto difficile perché il significato della stringa dipende anche dal contesto ( discorso, situazione, ecc. ).
Inoltre, in una comunicazione anche una frase sgrammaticata potrebbe veicolare un messaggio e avere un significato.
Nota. La lingua cambia continuamente. Ai linguisti spetta il compito di individuare le regole della lingua così come è, ma non sempre c'è accordo sulle regole grammaticali. Quindi, spesso una lingua ha più grammatiche, leggermente diverse tra loro.
Suddividere il testo in frammenti
I testi sono suddivisi in frammenti, paragrafi o frasi. Ogni singolo frammento ( pacchetto o segmento ) viene identificato con codice alfanumerico progressivo, che consenta di risalire al testo e all'ordine di sequenza del frammento al suo interno.
Associare delle etichette ai frammenti
Talvolta è utile associare a ciascun pacchetto un'etichetta per veicolare delle meta- informazioni. Ogni etichetta è una variabile in cui registrare il valore ( stato ) di una particolare proprietà del testo.
Ad esempio, è un testo vicino a una foto? Si tratta di un sottotitolo? E' un tag? E' un commento di un utente? E così via. E' un'operazione facoltativa ma, a volte, consente all'elaborazione dei dati di andare più a fondo nell'analisi.
La normalizzazione del testo
E' un'operazione di pretrattamento del testo che permette di eliminare le ambiguità presenti nei frammenti del corpus. Le parole del testo sono confrontate con le occorrenze di una libreria per individuare i termini complessi e specifici del lessico di un vocabolario.
1] La disambiguazione delle forme grafiche
2] La riduzione delle parole con iniziale maiuscola
3] L'analisi dei segmenti lessicali
L'assegnazione del codice della forma grammaticale
A ciascun simbolo grafico del corpus viene associato un codice riconosciuto. Ad esempio:
NM per i nomi propri
N per i sostantivi
NUM per i numerali
FORM per le forme idiomatiche
AGG per gli aggettivi
AVV per gli avverbi
PREP per le preposizioni
PRON per i pronomi
V per i verbi
O per gli stranierismi ( termini stranieri usati nel linguaggio corrente )
DAT per le date
Quando una forma grafica può essere catalogata in più voci, viene associata al gruppo dei codici separati da un carattere speciale ( es. N+AGG ).
L'analisi lessicometrica
Il corpus normalizzato viene elaborato per estrarre alcune informazioni statistiche sulla sua composizione.
La lessicazione
In questa fase il corpus viene analizzato per individuare le unità lessicali ( lessia ) all'interno del testo. Ad esempio, si usa la lessicazione per trovare i termini peculiari e le parole chiave del testo.




