L'analisi lessicometrica
L'analisi lessicografica estrae le informazioni statistiche dal corpus normalizzato del testo. Le principali grandezze dell'analisi sono le seguenti:
- Totale occorrenze ( dimensione ). E' il numero complessivo delle occorrenze delle forme grafiche del corpus ( word token ). Rappresenta la dimensione del corpus. In pratica, è il numero complessivo di parole di un testo, includendo nel conteggio anche le parole ripetute.
- Totale delle forme grafiche ( ampiezza o lessico ). E' il numero complessivo delle forme grafiche differenti ( parole, lessie o grafie, word types ) che si presentano almeno una volta all'interno del corpus. Sono escluse dal conteggio le ripetizioni delle stesse parole. Questa informazione rappresenta l'ampiezza del vocabolario e il lessico.
Queste due grandezze consentono di ottenere altri indicatori statistici di sintesi del corpus.
L'estensione lessicale
E' il rapporto percentuale tra l'ampiezza (V) e la dimensione del corpus (N). Indica la ricchezza lessicale del testo. E' indicata in valori percentuali.
V / N x 100
Questo rapporto tende a decrescere con la grandezza del corpus. I testi più lunghi hanno un rapporto V/N tendenzialmente più basso e viceversa.
Ad esempio, quando l'autore di un testo si esprime ripetendo sempre le stesse parole, l'estensione lessicale del testo è molto bassa.
La percentuale di hapax
E' il rapporto tra il numero delle forme grafiche appartenenti alla prima classe di frequenza (V1) e la dimensione del corpus (V).
V1 / V
Gli hapax sono i vocaboli che compaiono nel testo con una frequenza pari a uno, ossia che compaiono una sola volta nel corpus.
Il rango e le classi di frequenza
La classe di frequenza è l'insieme dei termini che si presentano con la stessa frequenza assoluta, ossia hanno lo stesso numero di occorrene nel corpus.
Per calcolare le classi di frequenza è necessario ordinare i termini per il numero delle occorrenze, dal più grande al più piccolo.
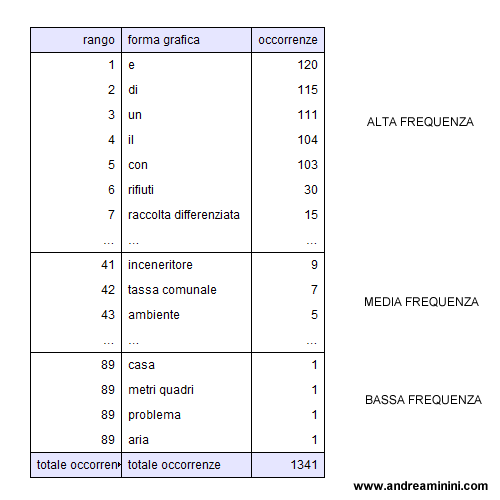
Nell'elenco ordinato viene assegnato a ciascun termine una posizione in base al numero delle volte che si ripete nel corpus. La posizione in classifica di un termine è anche detta rango.
Ad esempio, alla parola più frequente viene associato il rango uno. E così via.
In una stessa posizione ( rango ) possono esserci anche due o più termini, se presentano lo stesso numero di occorrenze.
Ad esempio, se alla classe di frequenza i=100 ( cento occorrenze ) appartengono due termini, a entrambi viene assegnata la stessa posizione e lo stesso rango.
Quando nella classe sono indicati degli intervalli di rango, ossia parole con un numero di occorrenze compreso da un minimo a un massimo, si calcola il valore medio delle occorrenze delle parole che vi appartengono. Alla classe viene dato il nome del rango intermedio.
Ad esempio, se il rango comprende i termini dal 10° al 20° posto nella scala ordinata dei termini più frequenti del corpus, il rango viene definito Rango 15 e il suo valore è pari alla media delle occorrenze di tutti i termini che vi appartengono.
Le parole con rango elevato
Spesso le prime posizioni ( ranghi ) sono occupate dai termini comuni e dagli elementi grammaticali, perché si presentano più spesso nel discorso. Ad esempio, le congiunzione.
Le parole chiave
Si parla di parola chiave per indicare il termine non comune che si presenta con maggiore frequenza nel corpus. Le parole chiave sono un'informazione rilevante per comprendere il significato o l'argomento nel testo. Possono trovarsi sia nei ranghi più alti che in quelli intermedi.
Le parole principali ( o vocabolario )
Nelle posizioni intermedie ( medie frequenze ) si trovano, invece, le parole principali, quelle specifiche del lessico e del vocabolario usato dall'autore. Sono anch'esse importanti per individuare il significato del testo.
La frequenza media generale
E' il rapporto tra l'ampiezza (V) e la dimensione (N) del corpus.
V / N
Questo rapporto tende a decrescere con la dimensione del testo ( N ). Quanto più un testo è grande, tanto più le parole tendono a ripetersi.
Il coefficiente di Guiraud ( o coefficiente G )
E' il rapporto tra l'ampiezza lessicale (V) e il quadrato della dimensione (N) del corpus.
G = V / N2




