Allocazione Dirichlet latente
L'allocazione Dirichlet latente ( ( Latent Dirichlet Allocation o LDA ) è un modello probabilistico del testo.
Come funziona l'allocazione LDA
Un documento è considerato come un insieme di argomenti, ognuno dei quali è caratterizzato da una particolare distribuzione di termini e parole.
Il modello è stato elaborato prendendo come base di partenza gli studi di Peter Dirichlet.
Peter Dirichlet era un matematico tedesco del XIX secolo. Elaborò una formula sulla distribuzione della probabilità continua.
Il modello LDA
E' un modello di analisi del linguaggio naturale che permette di comprendere il significato semantico del testo analizzando la somiglianza tra la distribuzione dei termini del documento con quella di un argomento specifico ( topic ) o di un'entità.
Il modello LDA è stato ideato da David Blei, Andrew Ng e Michael Jordan. E' stato presentato in un articolo del 2003 su Journal of Machine Learning Research.
Più di recente, la Latent Dirichlet allocation ha conquistato una certa notorietà anche nell'ottimizzazione SEO semantica come possibile fattore di ranking del search engine Google.
Un esempio di funzionamento della LDA
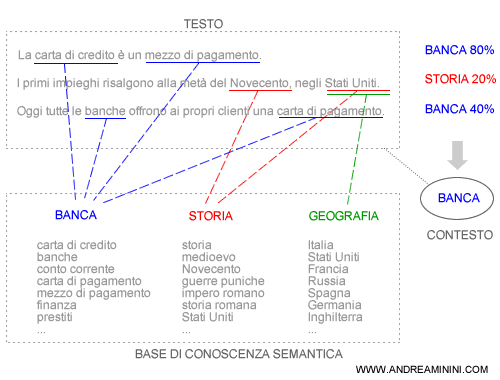
Supponiamo di avere una base di conoscenza composta per semplicità soltanto da due argomenti ( o topic ). A ciascun topic è associata una particolare distribuzione di parole principali.
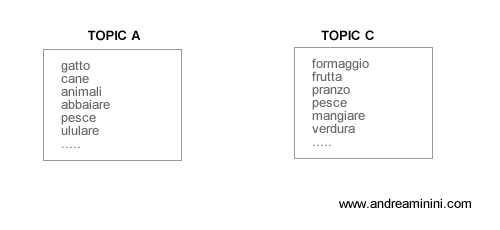
Prendiamo come riferimento questa base di conoscenza per capire il significato delle seguenti frasi di un documento.

Seguendo l'inferenza del modello LDA, l'algoritmo analizza il contenuto delle frasi e associa a ciascuna parola la sua appartenenza ai due topic ( C, A ).
Se una frase ha molti termini in comune con un topic, è molto probabile che stia parlando proprio di quell'argomento.

La prima frase
La prima frase è composta da cinque parole, due di queste sono però stop-word ( "Io", "e" ) e possono essere eliminate. Una volta eliminate le stop-word dal testo abbiamo tre word-count.
Tutte le parole della prima frase ( "mangio", "pesce", "frutta" ) appartengono al 100% al topic C. Soltanto una parola ( "pesce" ) appartiene anche al topic A.
E' quindi probabile che nella prima frase si stia parlando di cibo ( topic C ).

La seconda frase
Nella seconda frase le due parole principali appartengono al topic A al 100%. E' quindi probabile che si stia parlando di animali.
Da notare, il termine "pesce" ha una relazione sia con il topic A ( Animali ) che con il topic C ( Cibo ). Questa relazione può essere scartata perché la frase ha già una relazione al 100% con il topic C.

La terza frase
Nella terza frase non c'è una relazione certa con un topic, perché due termini su tre appartengono al topic A e altrettanti al topic C.
Essendoci una situazione di incertezza, è utile adottare la logica fuzzy affermando che la frase ha un legame al 50% con il topic C e al 50% con il topic A.

In conclusione
L'analisi LDA ha consentito automaticamente di risalire all'argomento delle frasi per associazione delle co-occorrenze con una base di conoscenza ( KB ) di riferimento, senza dover interpretare il significato delle frasi.

Questo algoritmo è abbastanza efficace ed efficiente, perché non consuma molte risorse macchina come un algoritmo interpretativo del testo ( efficienza ).
Pur essendo una semplice euristica, la tecnica restituisce un risultato soddisfacente ( efficacia ).




