Come funziona un motore di ricerca semantico
Cerchiamo di capire il funzionamento di un motore di ricerca semantico partendo da un semplice presupposto, gli attuali search engine sono composti da migliaia di algoritmi, spesso indipendenti l'uno dall'altro.
Nessuno può affermare di conoscere come lavora Google o Bing, nemmeno gli stessi progettisti riescono a prevedere con esattezza i risultati dopo un aggiornamento algoritmico.
Per affrontare questo argomento dobbiamo cercare di analizzarlo in modo più astratto, cercando di evitare la complessità degli algoritmi, e studiare il search engine come un sistema.
Qual è lo scopo di un search engine?
Un motore di ricerca può essere visto come un sistema con molti input e un output. E' una sorta intermediario tra l'utente ( domanda ) e i siti web che forniscono le informazioni su internet ( offerta ).
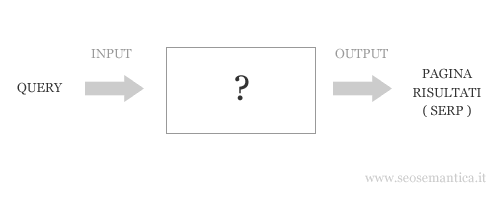
Non conosciamo cosa c'è dentro la scatola, possiamo però osservare direttamente quello che chiediamo al motore di ricerca e studiare le sue risposte. Dobbiamo però tenere sempre a mente qual è il fine del motore di ricerca.
Lo scopo del search engine è rispondere con efficacia alle domande degli utenti online. Il motore di ricerca raggiunge il suo obiettivo quando fornisce all'utente un'informazione utile per soddisfare il suo bisogno o per risolvere il suo problema.
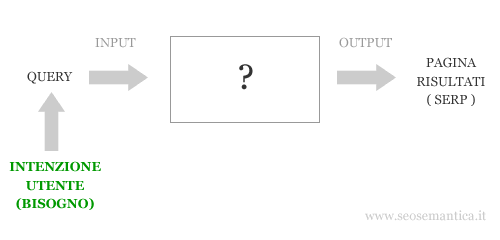
Ma fornire risposte utili non è poi così facile. Per fare bene il suo lavoro il search engine deve prima capire l'intenzione dell'utente che si nasconde dietro le sue parole. Deve comprendere il significato sia della query dell'utente che dei contenuti delle pagine web.
Come un motore di ricerca comprende il significato?
I primi motori di ricerca non analizzavano il significato delle parole, erano degli algoritmi molto semplici, quasi meccanici. Spesso era sufficiente soltanto la corrispondenza letterale tra la query e il titolo della pagina web.
Questo modus operandi era molto impreciso poiché le parole non hanno una sola accezione. Una parola può esprimere bisogni diversi a seconda del contesto e gli stessi bisogni possono essere rappresentati con parole diverse.
Un motore di ricerca semantico è un algoritmo di information retrieval molto più evoluto e risale al concetto madre che si cela dietro una mera sequenza di parole, lettere e simboli.
Non è un'impresa facile. Gli attuali algoritmi semantici non posseggono ancora un grado di intelligenza artificiale sufficiente per interpretare il senso di un discorso in linguaggio naturale.
Ad esempio, un algoritmo non riesce a capire l'ironia o le metafore, né le senzazioni o gli stati d'animo delle persone.
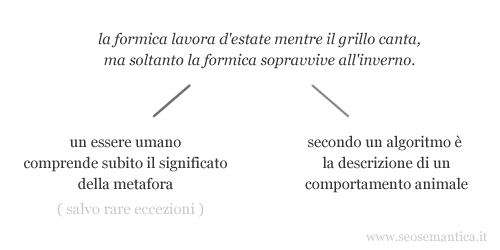
Gli algoritmi possono soltanto dedurre l'essenza del contenuto, la sua vicinanza a un particolare argomento, seguendo un processo di comprensione associativa. Nel prossimo paragrafo approfondiremo la conoscenza di questo processo.
La domanda: la query dell'utente
Quando un utente digita una query può esprimersi scrivendo una domanda in linguaggio naturale oppure con un elenco di parole chiave ( keywords ).
Il search engine non riesce a interpretare il significato di una domanda, può comunque risalire al bisogno dell'utente analizzando le associazioni delle parole.
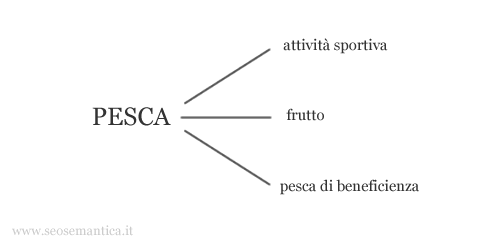
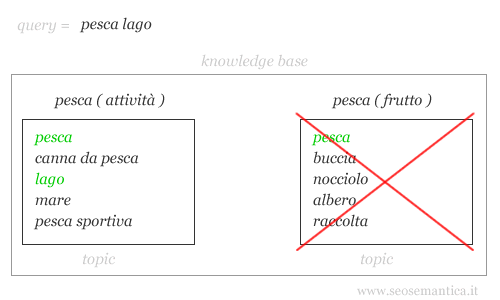
Ad esempio, se l'utente digita la query "pesca lago", è chiaro che vuole andare a pescare. Viceversa se cerca "pesca nocciolo", molto probabilmente sta cercando informazioni sulla frutta.
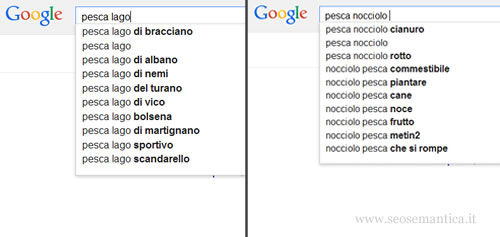
Come fa il search engine a capire il senso delle query? E' molto semplice, utilizza una base di conoscenza ( knowledge base ) in cui sono registrate le entità e le co-occorrenze per ciascun argomento ( topic ).
In alcuni casi, il motore di ricerca prende in considerazione anche altri elementi aggiuntivi, come le query formulate precedentemente dall'utente o, se quest'ultimo è loggato con un account al search engine, i suoi interessi e le informazioni che normalmente legge sul web.
Il caso particolare delle entità
Le entità meritano un paragrafo a parte. Un medesimo concetto può essere rappresentato con parole diverse, mantenendo comunque lo stesso significato. In questo caso ci troviamo dinnanzi a un'entità.
Facciamo un esempio pratico, come si chiama quella cosa verde con le foglie e le radici? Senza averlo nominato, non ci vuole molto a capire che stiamo parlando di un albero.
Alcuni concetti sono esprimibili mediante un insieme di parole più o meno vasto. L'albero possiamo chiamarlo "tree" (inglese) o "arbre" (francese) o "oggetto di colore verde con le radici e le foglie" ma la sostanza non cambia. Lo stesso può dirsi per molti altri concetti, reali o astratti che siano.
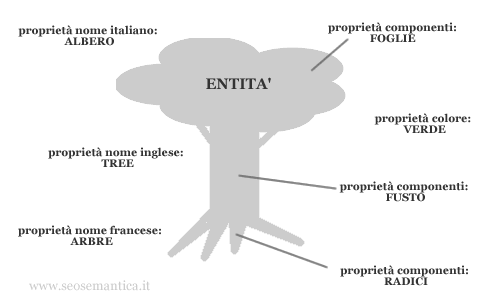
Come fa il search engine a riconoscere le entità? Anche in questo caso sono molto utili le knowledge base. In una base di conoscenza sono memorizzate sia le co-occorrenze per ogni topic, le parole più frequenti, e sia i gruppi di parole che descrivono le entità.
Una volta effettuato il matching tra le parole digitate dall'utente e quelle di un'entità, diventa molto più semplice risalire al reale bisogno dell'utente.
L'offerta: le pagine dei risultati ( serps )
Dopo aver compreso l'esigenza informativa dell'utente, il search engine deve trovare delle risorse che siano in grado di soddisfare efficacemente il suo bisogno. Seleziona tutte le risorse che hanno in comune la stessa entità della query.
All'interno di questo sottoinsieme di risorse, l'algoritmo ricerca quelle che più si avvicinano a una possibile risposta al problema dell'utente, analizzando le co-occorrenze presenti nella pagina ma anche numerosi altri fattori di ranking sia on-page che off-page, come gli anchor text dei link esterni, l'autorevolezza tematica, le citazioni, ecc.
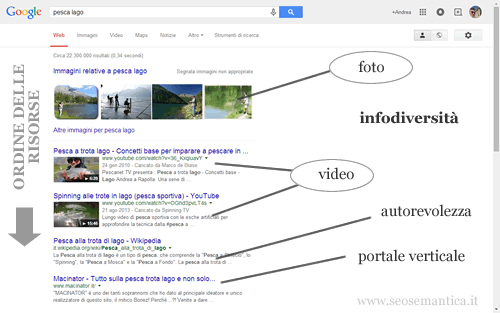
Le risposte sono ordinate secondo criteri diversi, in genere si tratta di euristiche del progettista. Ad esempio, a parità di offerta le risorse possono essere ordinate per autorevolezza del sito o del publisher, per info-diversità della fonte ( pagine web, video, news, immagini, pdf, ecc. ) o del titolo, ecc.
In Google questo processo di fusione dei risultati è conosciuto come universal search.
Se il search engine semantico è riuscito a individuare l'entità della query, è molto probabile che sia in grado di fornire una risposta a tema sull'argomento. Non è detto che quest'ultima sia anche utile, ma questo è un altro discorso ed entrano in gioco altri algoritmi correttivi legati alla user experience.
In conclusione
In questa pagina abbiamo semplificato molto l'argomento per poter descrivere un processo altrimenti molto complesso.
Abbiamo visto come un motore di ricerca semantico si avvalga soprattutto di una base di conoscenza di riferimento, utile per desumere il senso delle query e quello delle pagine dei siti web.
Senza questo database semantico non riuscirebbe mai a risalire all'accezione delle parole, né comprendere le mille sfumature che si nascondono dietro la forma letterale di una frase.




