Web scraping
Il web scraping è una tecnica per estrarre informazioni e dati dalle pagine dei siti web tramite delle procedure automatiche. Questa tecnica è anche conosciuta come data scraping.
A cosa serve lo scraping
Il principale scopo dello scraping è l'estrapolazione delle informazioni dal corpus di un testo, disponibile sulla rete internet. I dati sono estratti, elaborati e archiviati in un database.
I documenti scansionati possono essere registrati nella banca dati in forma integrale oppure in una forma rielaborata. Tutto dipende dallo scopo dello scraping.
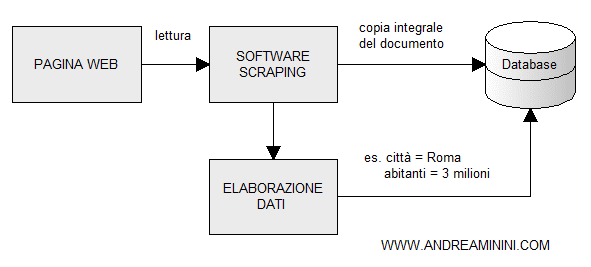
Ad esempio, lo scraping può essere utilizzato per analizzare i contenuti di un sito web, per creare una copia di sicurezza delle pagine, oppure una copia del website a propria disposizione per navigare offline tra i documenti. Si tratta perlopiù di attività legali.
Tuttavia, non mancano anche le finalità malevoli. Lo scraping potrebbe essere usato nella Seo Negative per pubblicare online dei contenuti copiati, facendoli indicizzare sui search engine prima del legittimo autore.
Gli aspetti legali del web scraping
Scansionare un documento tramite un agente automatico non è sempre legale. In alcuni casi, è esplicitamente vietato dai siti web.
L'agente carica in memoria migliaia di pagine web in pochi secondi. Questa attività può danneggiare il sito web, in quanto consuma le risorse del server del sito web, rendendo più lenta o impedendo del tutto la visualizzazione dei documenti a tutti gli altri utenti.
Nota. In alcuni casi lo scraping può anche comportare la caduta del server o il blocco del sistema operativo. Il sito web viene oscurato e resta off-line, oppure dà segni di malfunzionamento ( es. HTTP 500 Error Server ).
L'attività di scraping è simile a quella svolta dai crawler dei search engine, quando navigano tra le pagine dei siti web per scansionare i loro contenuti. Non è un'attività illegale ma, se vietata dal website, occorre evitarla.
- In primo luogo, è necessario analizzare il file robots.txt sul server del sito web da scansionare. Se il sito proibisce l'accesso a tutti gli spider dei search engine, allora il divieto è esplicito e vale anche per i software di scraping.
- In secondo luogo, il divieto di scraping potrebbe essere indicato nella pagina delle condizioni di servizio del website.
Inoltre, l'uso dei dati estratti tramite lo scraping potrebbe violare il copyright. Ad esempio, se i dati ottenuti sono utilizzati per riprodurre dei contenuti online oppure per scopi commerciali, lo scraping ne viola il diritto di autore.
Nota. Se i dati ottenuti dallo scraping sono utilizzati per creare automaticamente dei contenuti online, oltre a violare il diritto di autore si viola anche la regola dei motori di ricerca che vieta l'indicizzazione dei contenuti automatici.
Qualora lo scraping sia possibile, è consigliabile rendere l'agente scraper meno invasivo possibile, riducendo la quantità di documenti letti al minuto entro una soglia accettabile. In questo modo si evita di causare danni al sito scansionato.
Come fare scraping di un sito web
Alcuni software scansionano un website per creare una copia navigabile del sito sul computer dell'utente. Questi programmi si limitano a creare dei contenuti copiati off-line per uso personale.
Software di scraping. Alcuni esempi di software di scraping sono Teleport, Httrack, Simple Html Dom.
Lo scraping può essere realizzato anche tramite procedure agenti online o Parser. Si tratta di programmi sviluppati nel linguaggio di programmazione ASP o in PHP che leggono il contenuto HTML di una pagina web esterna, ne elaborano le informazioni, organizzano e salvano i dati in un database.
Ecco un esempio pratico di web-scraping in Python.
Generalmente gli agenti utilizzano le API di Google per estrarre i risultati del motore di ricerca ( SERP ) oppure navigano dentro le pagine web dei siti per controllare le parole chiave, i link interni ed esterni, le meta informazioni e così via.




