Il file Robots Txt
Il Robotx Txt è un file del sito web per orientare il motore di ricerca nella scansione delle pagine del sito.
A cosa serve il file robots.txt
E' utilizzato per indicare al search engine quali pagine o cartelle del sito sono indicizzabili e quali, invece, non devono essere indicizzate.
E' un mezzo per influenzare l'indicizzazione e per bloccare l'indicizzazione sulle cartelle riservate del sito web da parte del motore di ricerca.
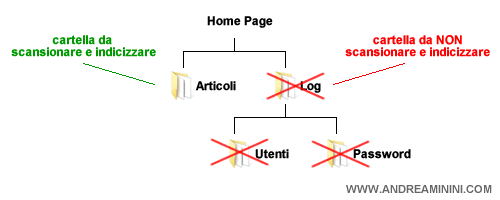
Il file robots.txt è uno degli strumenti per tutelare la riservatezza delle informazioni contenute in alcune cartelle del sito ( es. dati sensibili, privacy, log di accesso, password, statistiche del sito, bozze, contenuti duplicati, tag o categorie, ecc. ).
Esempio. Quando una directory del sito contiene dati riservati è necessario dire al motore di ricerca di non indicizzarla, in caso contrario il suo contenuto potrebbe diventare visibile a tutti sui risultati di ricerca.
Dove si trova il file
Il file robots.txt è situato nella cartella principale ( root ) del sito web, quella dove generalmente si trova anche il documento della home page del sito.
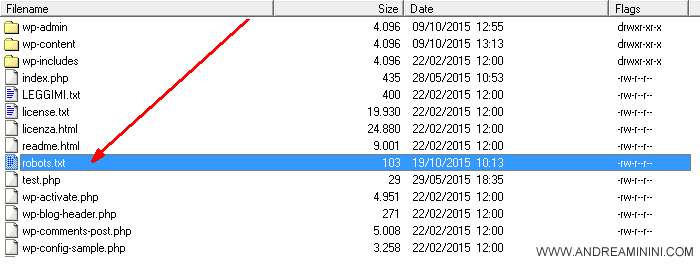
Si tratta di un semplice file di testo con estensione .TXT. Può essere editato con un software qualsiasi di editazione del testo e trasferito sulla root del sito tramite FTP.
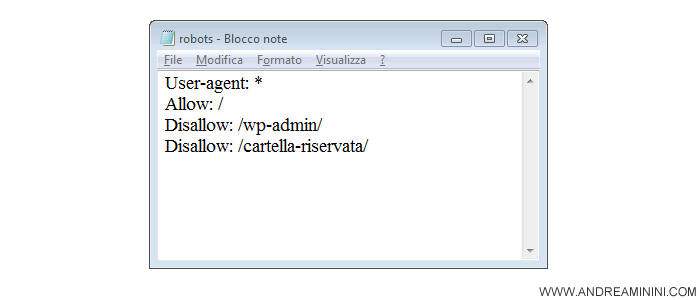
Nota. E' preferibile utilizzare un text editor molto semplice come, ad esempio, il Blocco Note ( Notepad ) su Microsoft Windows. I software di word processo spesso inseriscono del codice aggiuntivo che potrebbe dare fastidio.
Come scrivere il file robots.txt
Nel file possono essere inserite le istruzioni da passare al search engine.
Le principali istruzioni nel file robotx.txt sono le seguenti:
- User-Agent
- Disallow
User-Agent
E' l'istruzione in cui indichiamo il nome dello spider a cui vogliamo impartire l'istruzione. Deve essere sempre scritta prima delle altre.
Per impartirlo a tutti gli spider possiamo scrivere il simbolo dell'asterisco.
User-agent: *
Per passare l'istruzione soltanto allo spider del motore di ricerca Google dobbiamo scrivere nel seguente modo:
User-agent: googlebot
Il crawler del search engine di Mountain View si chiama "googlebot".
Elenco completo dei nomi dei bot. Ogni motore di ricerca ha un nome specifico per il suo agente bot. Una lista completa può essere reperita su questo sito: http://www.robotstxt.org/db.html
Disallow
Questa istruzione inibisce l'accesso agli spider sulle cartelle e/o sui file riservati del sito.
Ad esempio, per proibire la scansione e l'indicizzazione della cartella con nome /cartella/ e del file /cartella/log.txt possiamo scrivere nel seguente modo:
Disallow: /cartella/
Disallow: /cartella/log.txt
La prima istruzione ( Disallow: /cartella/ ) vieta l'accesso allo spider a tutto il contenuto della directory /cartella/, sia ai file che alle sottodirectory della stessa.
La seconda istruzione ( Disallow: /cartella/log.txt ) vieta la scansione soltanto sul file log.txt nella directory /cartella. In questo caso, la scansione è consentita su tutti gli altri file nella stessa cartella poiché è vietata soltanto sul file indicato.
Esempio pratico
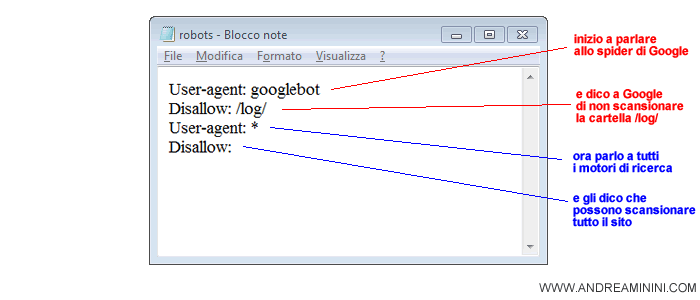
Nel seguente riquadro viene mostrato un esempio di file robots.txt che inibisce allo spider di Google ( googlebot ) l'accesso alla cartella /log mentre lo consente ( * ) a tutti gli atri:
User-agent: googlebot
Disallow: /log/
User-agent: *
Disallow:
L'ordine della sequenza di istruzioni
Il file robots.txt è una procedura interpretata dal crawler e i comandi sono eseguiti in sequenza così come sono scritti, dall'alto verso il basso. Pertanto, è molto importante l'ordine di presentazione delle istruzioni.
Nota. Cambiando l'ordine può cambiare radicalmente anche il messaggio che si passa al search engine
Gli utenti possono vedere il contenuto del robots.txt
Generalmente no, il file robots txt è visto soltanto dagli agenti crawler ( bot ) dei search engine.
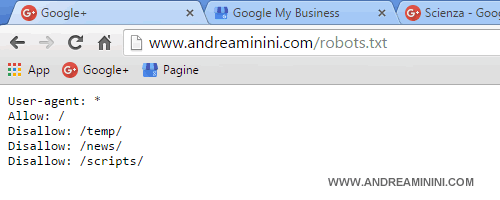
/robots.txt
Tuttavia, il file robots.txt è comunque un file di testo di default che si chiama allo stesso modo e si trova nello stesso posto su tutti i siti web. Quindi, un utente esperto può leggere il suo contenuto, semplicemente digitando il suo indirizzo URL nella barra degli indirizzi del browser.
E' quindi preferibile non inserire informazioni riservate al suo interno. Va usato principalmente per inibire l'accesso alle directory da proteggere, quelle contenti dati segreti o riservati.
Esempio. Se una directory riservata contiene molte sottocartelle, è sufficiente inibire l'accesso dei robots soltanto sulla prima cartella madre senza indicare anche le altre. Le sottocategorie interne sono comunque escluse dalla scansione quando la cartella che le contiene è già stata inibita.
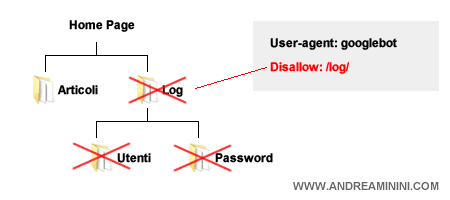
Inserire le sottodirectory nel file robots è inutile ed è anche pericoloso per la sicurezza del sito. Indicando le sottocartelle si potrebbe fornire ai malintenzionati una info utile sulla struttura interna della cartella nascosta e rendergli più facile trovare le informazioni riservate tramite un semplice browser.




