Il Meta Robots
Il Meta Robots è un metatag del linguaggio HTML che permette di impartire dei comandi agli spider dei motori di ricerca.
A cosa serve il metatag Robots
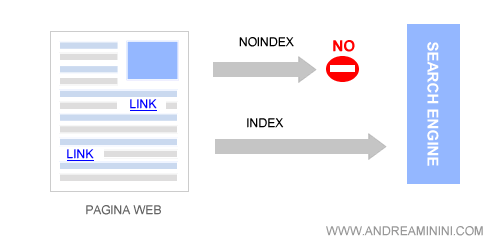
Questo metatag è utile per comunicare agli spider dei search engine se il documento può essere indicizzato ( index ) oppure no ( noindex ).
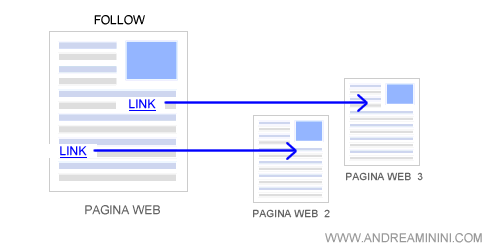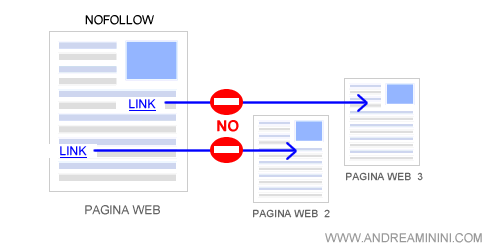
E' anche usato per indicare al crawler se deve seguire i link in uscita dalla pagina ( follow ) oppure meno ( nofollow ).
Come scrivere il meta robots in un documento HTML
Il meta Robots si trova nella sezione Head del documento Html, una zona non direttamente visibile dagli utenti sul browser ma comunque letta dagli spider dei motori di ricerca.
La sintassi del metatag
La sintassi del tag meta robots è la seguente:
<META NAME="ROBOTS" CONTENT="[ parametri ]">
I possibili parametri del metatag sono i seguenti:
- Index. Indica al Search Engine che la pagina può essere scansionata e indicizzata. Il bot può scansionare e indicizzare la pagina. E' un parametro di default.
- Noindex. Inibisce l'indicizzazione del documento sui motori di ricerca. Il bot può scansionare la pagina ma non può inserirla nell'indice dei risultati di ricerca.
Index e Noindex indicano situazioni opposte. La presenza di uno dei due implica la negazione dell'altro, quindi non devono mai comparire insieme nello stesso documento Html.
- Follow. Indica allo spider del search engine di seguire i link in uscita presenti nel documento Html della pagina web. E' un valore di default.
- Nofollow. Vieta la scansione dei link presenti nel documento Html della pagina. Il bot non deve seguirli fino alle landing page a cui sono collegati.
Follow e Nofollow. Anche in questo caso si tratta di valori opposti, l'uno nega l'altro e, quindi, non devono presentarsi insieme nel metatag.
Le possibili combinazioni dei parametri del metatag robots consentono di ottenere diversi risultati.

Per impartire una serie di istruzioni allo spider non è necessario scrivere più volte il metatag. E' sufficiente usare un solo metatag robots e indicare tutti i parametri nell'attributo CONTENT separandoli tra loro tramite le virgole.
Un esempio pratico
Per bloccare l'indicizzazione su un documento e indicare agli spider di non seguire i link in uscita presenti nel documento Html della pagina si può scrivere nel seguente modo:
<HTML>
<HEAD>
<META NAME="ROBOTS" CONTENT="NOINDEX, NOFOLLOW">
</HEAD>
<BODY>
</BODY>
<HTML>
Altri parametri del metatag robots
Il metatag robots può essere usato anche per comunicare altri comandi agli spider dei search engine. In più noti sono i seguenti:
- Archive. Consente al search engine di memorizzare una copia cache del documento e mostrarla nei risultati di ricerca.
- Noarchive. Vieta al motore di ricerca di registrare una copia cache del documento Html.
Archive e Noarchive. Come per i precedenti casi, anche in questa situazione l'uno è la negazione dell'altro e non possono apparire sullo stesso documento.
- Noimageindex. Blocca l'indicizzazione delle immagini contenute in una pagina web.
Nota. Se le immagini sono linkate direttamente o sono raggiungibili in altro modo ( es. elenco della directory, uso in altri articoli, ecc. ) sono comunque indicizzate dal search engine.
- Noodp. Blocca l'uso della descrizione del sito fornita da Dmoz ( ODP ) come snippet della pagina nei risultati di ricerca.
- Noydir. Blocca l'utilizzo della descrizione del sito redatta nella directory Yahoo! come snippet della pagina sulla Serp.
Nota. E' utilizzato solo da Yahoo!
- Nosnippet. Indica al search engine di non mostrare uni snippet della pagina nei risultati di ricerca.
Nota. E' utilizzato solo da Google.
- None. Equivale alla combinazione noindex, nofollow.
Nota. E' usato da Google e da Ask. Non è chiaro se lo utilizzano anche Yahoo! e Bing.
Se la pagina web non ha il metatag robots?
Se un documento non ha il metatag robots documentato nel codice Html, vale la seguente situazione di default: index, follow, archive.
In parole semplici, quando non trova il metatag robots il bot può scansionare e indicizzare la pagina ( INDEX ), seguire i link in uscita ( FOLLOW ) e registrare una copia cache sul suo database ( ARCHIVE ).




