Attributi con molti valori negli alberi decisionali
Un altro problema frequente nella costruzione di un albero decisionale, è la presenza di attributi con molti valori.
In alcuni casi limite, un attributo assume tanti valori quanti sono gli esempi del training set.
Esempio. Ad esempio, nella scelta di un ristorante un attributo potrebbe essere il nome del ristorante. Ogni ristorante ha un nome diverso dagli altri. Tecnicamente sembra un attributo rilevante... ma non lo è.
Nella scelta dell'attributo più rilevante bisogna considerare questo aspetto.
In caso contrario, si rischia di costruire un albero decisionale complesso e inefficiente.
Come risolvere il problema?
Una soluzione consiste nel calcolare il guadagno informativo di un attributo, tenendo conto del costo necessario per ottenere l'informazione.
Un esempio pratico
In questo training set l'attributo X2 ha molti valori.
Ogni esempio ( riga ) della tabella ha un valore diverso nell'attributo X2.
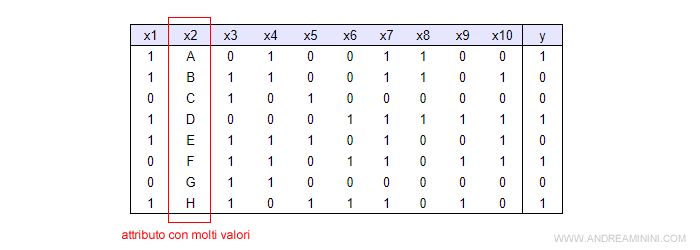
Se calcolassi l'indice di Shannon Wiener per trovare l'attributo più rilevante, anche l'attributo X2 verrebbe selezionato.
Gli attributi X2, X6, X9 hanno il guadagno informativo più alto.
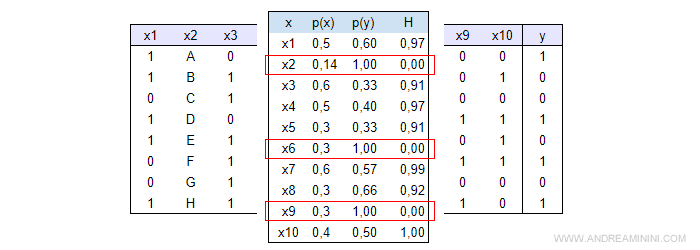
Nota. Le variabili X2, X6 e X9 hanno un guadagno informativo massimo V=1-H=1 perché l'indice di Shannon Wiener è zero (H=0).
Al momento non si riesce a capire quale attributo scegliere.
Tuttavia, scegliere uno o l'altro non è indifferente perché l'attributo X2 ha un valore differente a ogni esempio. E' quindi meno utile di X6 e X9.
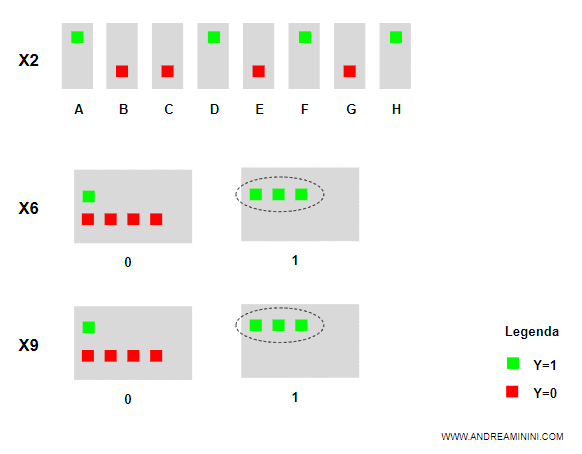
Viceversa, gli attributi X6 e X9 hanno un'informazione più discriminante perché quando X6 e X9 sono uguali a 1 in tre casi su tre y è uguale a 1.
Esempio pratico. L'attributo X2 potrebbe essere il nome del ristorante. L'attributo X6 la presenza di un parcheggio per i clienti del ristornate. L'attributo X9 un menù con prezzi economici. E' evidente che X6 e X9 influenzino la scelta del cliente di entrare nel ristorante molto più di X2.
Come fare a eliminare gli attributi con molti valori?
Una soluzione è il rapporto tra il valore dell'informazione (V) e la quantità di informazioni contenute nell'attributo.
Il calcolo di questo indice riduce l'importanza degli attributi con molti valori.
Esempio
Il rapporto tra il valore informativo V e la quantità di valori dell'attributo riduce l'importanza dell'attributo X2.
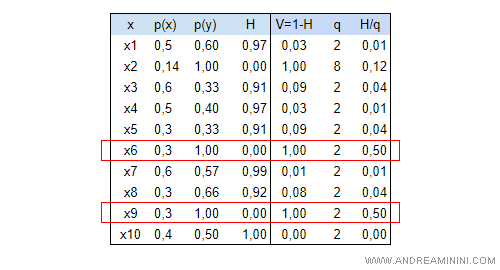
Si tratta soltanto di una soluzione semplice (o banale) per rendere l'idea ma già abbastanza efficace.
In realtà, esistono molti altri metodi migliori. Tra questi c'è l'indice di guadagno ( gain ratio ).
Come calcolare l'indice di guadagno ( gain ratio )
Il gain ratio penalizza gli attributi con sottoinsiemi simili.
La formula dell'indice di guadagno di un attributo è la seguente:
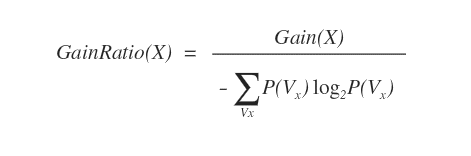
Nota. Il denominatore della formula è detto Split Information. Misura la somiglianza dei sottoinsiemi generati dall'attributo e sfavorisce quelli con molti sottoinsiemi aventi la stessa cardinalità.
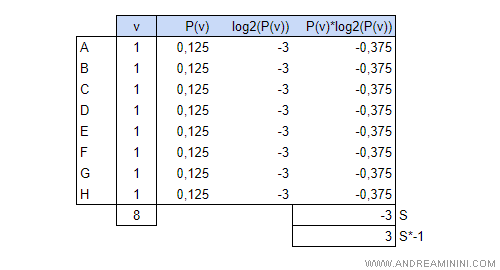
Ad esempio, l'attributo X2 ha otto valori diversi V={A,B,C,D,E,F,G,H}.
Il gain ratio di X2 è 0.33.
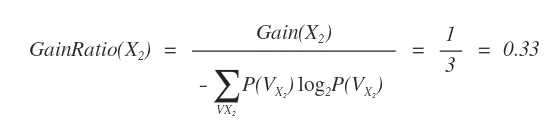
L'attributo X6 ha due valori diversi V={0,1}.
Il gain ratio di X6 è uguale a 1.

L'attributo X9 ha due valori {0,1}.
Anche il gain ratio di X9 è uguale a 1.

Calcolando il gain ratio (GR) per tutti gli attributi ottengo la seguente tabella:
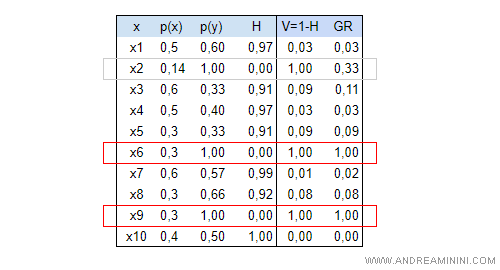
Gli attributi X6 e X9 hanno il gain ratio più alto ( 1.00 ).
Pertanto, sono gli migliori attributi nella costruzione di un albero decisionale, quelli da selezionare prima degli altri.
L'attributo X2 si è invece ridimensionato a 0.33 ed è diventato un attributo secondario.
In questo modo si è risolto il problema dell'attributo con molti valori.
Svantaggi del gain ratio. Potrebbe comunque capitare che un attributo con molti valori sia realmente più significativo di altri. Il gain ratio lo penalizza a prescindere. Quindi, il gain ratio non risolve tutti i problemi della selezione dell'attributo ottimale. Ne risolve alcuni, ma ne potrebbe creare altri.




