Training Set
L'insieme di addestramento ( o training set ) è un elenco di esempi pratici su cui costruire una base di conoscenza o un algoritmo decisionale nel machine learning.
Come funziona? La macchina analizza i dati per trovare dei nessi tra una serie di variabili di input ( es. proprietà, caratteristiche dell'ambiente, ecc. ) e una determinata variabile di output ( variabile obiettivo decisionale ).
L'insieme di addestramento consiste in una serie di situazioni che fotografano alcune caratteristiche dell'ambiente.
Chi realizza il training set?
Può essere realizzato dalla macchina stessa osservando l'ambiente circostante.
In alternativa, la lista degli esempi può essere fornita alla macchina da un supervisore esterno per avviare il processo di apprendimento induttivo.
A cosa serve? E' utilizzato nelle tecniche di apprendimento automatico supervisionato del machine learning per consentire alla macchina di imparare dall'esperienza e scoprire nessi di causa effetto tra le variabili stocastiche. E' anche utilizzato per istruire i sistemi esperti.
Un esempio di training set
Questa tavola rappresenta dieci record ( righe ).
Ogni riga fotografa una particolare situazione. E' un vettore di dati { x1, x2, ... , x10 }.
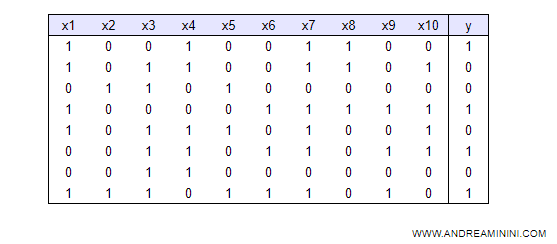
Per ogni record viene rilevato lo stato reale di dieci variabili di input (X) e una variabile obiettivo (Y).
A partire da questa osservazione, la macchina cerca di individuare dei nessi logici per costruire un albero decisionale.
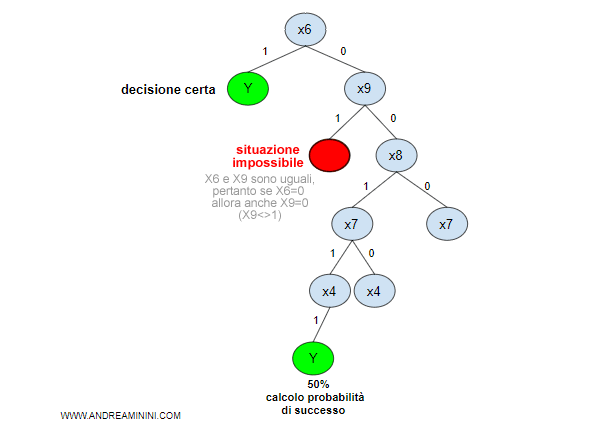
Nota. Nell'esempio in questione ho usato per semplicità delle variabili booleane con valore vero o falso perché sono le più semplici da esporre. Lo stesso metodo può essere usato con variabili discrete o continue, con complessità computazione crescente.
Quanti esempi ha l'insieme di training?
E' preferibile inserire molti esempi nell'insieme di addestramento, perché aumenta l'efficacia del processo di training.
Perché?
Un elevato numero di esempi N riduce la probabilità che un esempio anomalo influisca eccessivamente sull'apprendimento.
Nota. Se l'insieme di training è molto grande, un'ipotesi anomala è improbabile che sia consistente con tutti gli esempi ed è scartata dall'algoritmo di apprendimento.
Secondo la teoria dell'apprendimento computazionale, un'ipotesi consistente con gli esempi è "probabilmente e approssimativamente corretta" (PAC) se l'insieme di training sufficientemente grande.
La differenza tra insieme di training e di test
L'insieme di addestramento ( training set ) non va confuso con l'insieme di test ( test set ).
- L'insieme di training costruisce un albero decisionale ( decision tree ) a partire dall'osservazione degli esempi.
- L'insieme di test verifica l'efficacia dell'albero decisionale appena costruito, sottoponendo alla macchina delle situazioni ( vettore X di input ) per controllare la validità delle sue risposte/decisioni.
Quindi, l'insieme di training costruisce l'albero decisionale mentre l'insieme di test ne misura l'efficacia.
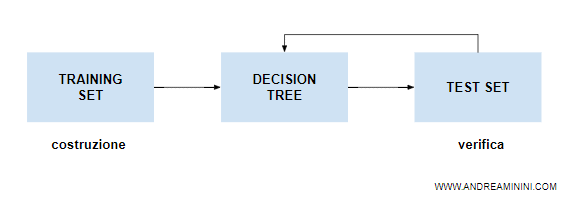
Nota. Se l'albero decisionale è poco efficace, ossia fornisce risposte insoddisfacenti secondo il test set, il processo di apprendimento deve essere ripetuto dall'inizio espandendo il training set con altri esempi. Il processo di machine learning termina soltanto quando l'albero risponde correttamente alle domande contenute nel test set.
Secondo l'ipotesi di stazionarietà l'insieme di training e l'insieme di test devono essere estratti casualmente dalla stessa popolazione di esempi con la medesima distribuzione di probabilità.
In questo modo, un'ipotesi corretta sull'insieme di addestramento, molto probabilmente è corretta anche nell'insieme di test.
L'insieme di addestramento pesato
In un insieme di addestramento pesato gli esempi hanno pesi diversi. Gli esempi con un peso maggiore hanno maggiore importanza.
Nell'elenco degli esempi è aggiunto un ulteriore campo dove è indicato il peso ( importanza ) dell'esempio.

Il peso diventa rilevante nella costruzione dell'albero decisionale.
Nella tabella precedente il secondo esempio vale tre (p=3) mentre il sesto esempio ha un peso doppio (p=2) rispetto agli altri (p=1).
Nota. Se non è possibile aggiungere un campo alla tabella, posso replicare un esempio N volte e selezionare gli esempi da testare tramite una funzione random che sceglie in modo casuale. In questo modo, gli esempi più ripetuti ( e più importanti ) hanno una maggiore probabilità di essere estratti durante la costruzione del decision tree. Ad esempio, la forma randomizzata della tabella precedente è la seguente:
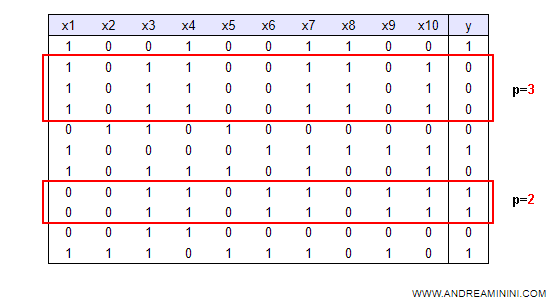
In questo caso il secondo esempio si ripete tre volte (p=3) mentre il sesto esempio si ripete due volte (p=1). Tutti gli altri esempi appaiono una volta sola. Il secondo esempio ha una probabilità di 3/11 ( circa il 27% ) di essere estratto, il sesto esempio di 2/11 ( circa il 18% ) e tutti gli altri di 1/11 ( circa il 9% ).
Il training set pesato è usato nel boosting, una tecnica di ensemble learning.




