L'algoritmo di iterazione delle politiche
L'algoritmo di iterazione delle politiche è utilizzato per trovare una soluzione a un problema decisionale di Markov ( MDP ).
- Come funziona l'algoritmo? Si basa su queste caratteriste fondamentali:
- Data una politica π calcola l'utilità degli stati Up seguendo π.
- Seleziona la politica π+1 che massimizza l'utilità attesa (MEU) al passo successivo.
- L'algoritmo termina se la politica π+1 non apporta alcun miglioramento rispetto alla precedente politica π.
Dopo ogni ciclo l'algoritmo migliora la politica ossia la sequenza di azioni per risolvere il problema.
Un esempio pratico
L'agente deve raggiungere l'obiettivo C2 a partire dalla casella iniziale A2, evitando in tutti i modi la casella C3.
Per farlo può seguire diversi percorsi e ogni percorso è una politica ( π ) differente.
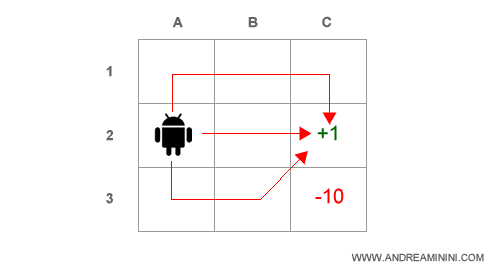
Nota. Ogni passo costa all'agente una perdita di utilit à pari a -0.1. Inoltre, le azioni hanno un margine di errore del 20%. Quindi se l'agente decide di spostarsi in una casella, ha una probabilità pari a 0.8 di riuscirci e una probabilità pari a 0.2 di deviare nella casella a destra o a sinistra.
Ipotizziamo che la politica corrente π sia A3→B3→C2
Quindi l'agente deve spostarsi da A2 a A3.
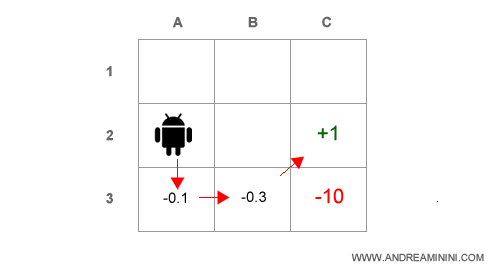
Per ogni stato A3, B3, C2 della politica è possibile calcolare l'utilità stimata in base alla migliore azione successiva, fino al raggiungimento dell'obiettivo finale (C2).
Nota. La prima politica è casuale perché l'agente non ha informazioni sulle utilità degli stati ( caselle ). L'utilità U(s) di ogni stato è uguale a zero. Pertanto, il vettore delle utilità U è nullo.

A partire da questa politica, l'agente deve verificare se ci sono politiche alternative migliori.
Comincia con l'analizzare le scelte alternative da A2 ossia A2→A1 , A2→B1 , A2→B2 , A2→B3 .
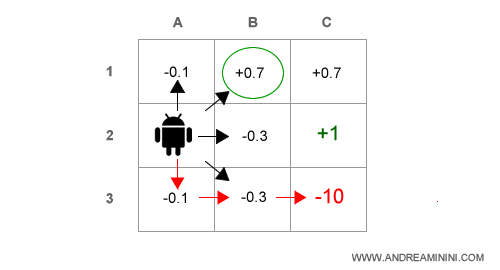
L'agente scopre che può ottenere un'utilità stimata più alta sulla casella B1.
Nota. Seguendo la politica attuale ottiene U(A3)=-0.1. Scegliendo di andare verso B1 ottiene U(B1)=0.7. E' quindi più alta.
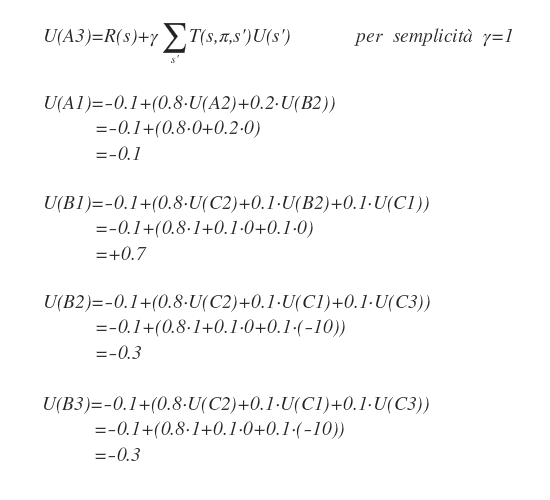
A questo punto sostituisce la politica corrente π con la nuova politica A2→B1→C2.
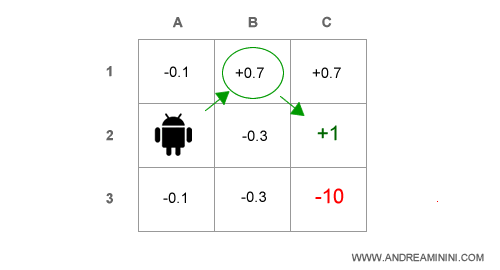
Al turno successivo l'agente ripete l'analisi a partire da B1 per verificare se esiste una politica migliore rispetto a A2→B1→C2.
Nota. Questa volta il vettore delle utilità non è più uguale a zero. Per ogni stato si prende in considerazione la stim a delle utilità calcolata nell'iterazione precedente.
Seguendo la politica corrente π ( A2→B1→C2 ) il passo successivo B1→C2 ha un'utilità attesa pari a 0.74.
L'agente può analizzare le azioni alternative ossia B1→C1 e B1→B2.

In questo caso le politiche alternative forniscono un'utilità attesa inferiore ( 0. 56 e -0.23 ) rispetto alla politica corrente 0.74.
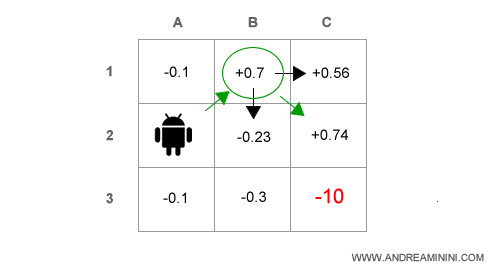
Quindi l'agente continua a eseguire la politica corrente π ( A2→B1→C2 ).
Nel passo successivo raggiunge l'obiettivo (C2) e l'algoritmo termina l'esecuzione.
Quali sono i vantaggi e svantaggi dell'algoritmo
L'algoritmo è una variante dell'algoritmo di iterazione dei valori.
Prende spunto dalla considerazione che una soluzione approssimata è quasi ottimale ed è sicuramente meno costosa di una soluzione ottimale.
In effetti, l'algoritmo di iterazione delle politiche è più efficiente dell'iterazione dei valori.
Dal punto di vista degli svantaggi, se le politiche da analizzare sono molte, la complessità dell'algoritmo potrebbe diventare impraticabile.
Nota. Per superare gli svantaggi dovuti alla complessità computazionale, si possono selezionare e ridurre il confronto soltanto sulle politiche più probabili, scartando ex-ante o durante l'elaborazione quelle con poca probabilità di successo.
Lo pseudocodice dell'algoritmo
Lo pseudocodice dell'algoritmo è il seguente:

Dove mdp è l'insieme degli stati e del modello di transizione T.
Aggiornamento parziale. Quando lo spazio degli stati diventa molto grande, l'aggiornamento di Bellman può diventare impraticabile. In questi casi per ridurre la complessità dell'algoritmo si può limitare l'aggiornamento a un numero predefinito di passi in avanto o entro un sottoinsieme di stati locali. In questo caso si parla di iterazione delle politiche modificata.




