Come trovare le co-occorrenze di una keyword
Un tool gratuito per controllare le co-occorrenze di un argomento si chiama Seo Hero Tech.
A cosa serve? A partire da una parola chiave mi consente di sapere quali sono le co-occorrenze del termine nei documenti posizionati ai primi posti su Google. E' un tool utile nel text mining, seo semantica e copywriting.
Come funziona Seo Hero Tech
Il servizio è online all'indirizzo www.seo-hero.tech
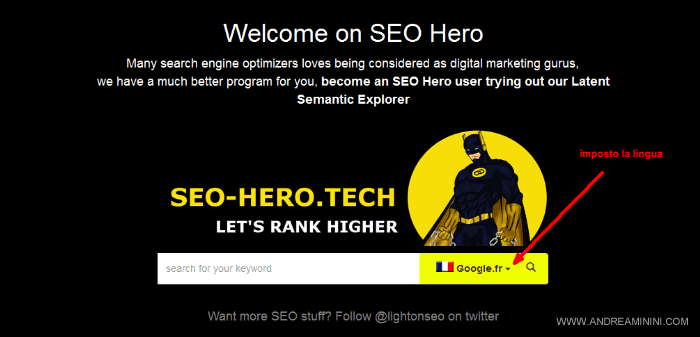
Come prima cosa seleziono la lingua da analizzare.
Posso scegliere tra i risultati di Google Italia, Francia o USA.
In questo caso seleziono l'italiano di Google.it.
Poi digito la parola chiave da approfondire. Quella di cui voglio conoscere le co-occorrenze.
Può essere una keyword unica o composta.

A questo punto clicco sul pulsante per avviare la ricerca.
E' l'icona a destra, quella con il simbolo della lente di ingrandimento.
Il tool comincia a scandagliare le informazioni online sulla SERP di Google per trovare le co-occorrenze più frequenti.
Cos'è una co-occorrenza? E' una parola che in genere accompagna un'altra parola quando si parla di un particolare argomento o contesto. Ad esempio, se la chiave di partenza è SEO, alcune co-occorrenze sono "ottimizzazione", "motori di ricerca", "search engine optimization", ecc.
La lista delle co-occorrenze viene pubblicata nella sezione inferiore dello schermo.

L'elaborazione dura qualche minuto. Però i risultati sono visualizzati in tempo reale.
Quindi, i primi dati sono visibili già dopo pochi secondi.
Come leggere i risultati del tool
Nella sezione di sinistra sono elencati i termini singoli mentre nella sezione di destra i termini composti ( parole doppie ).
Nella colonna DF è indicata la document frequency, ossia la frequenza percentuale in cui il termine compare nei documenti elaborati.
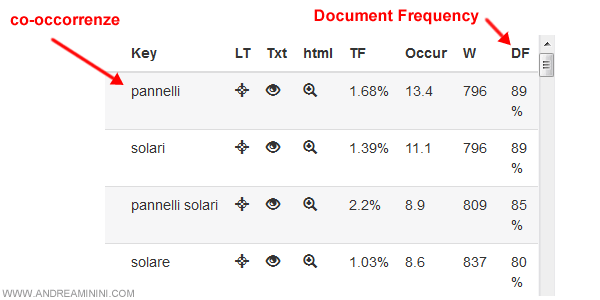
Esempio. Se il tool ha scandagliato 1000 documenti e il termine X ha 80% di DF, vuole dire che è contenuto in 800 documenti.
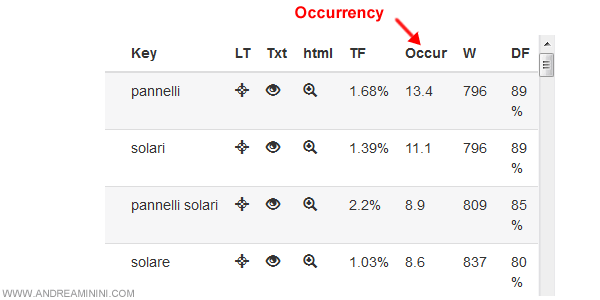
Alla colonna O ( occurrency ) si trova invece la frequenza assoluta media del termine, ossia quante volte è stato usato in ogni singolo documento tra quelli analizzati.
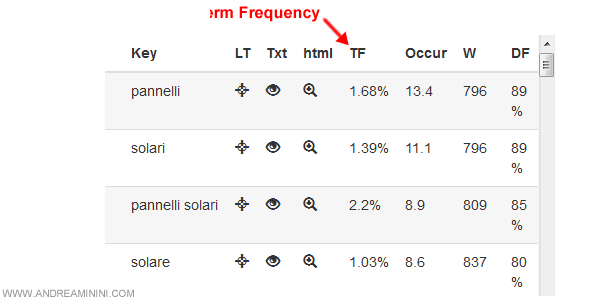
Alla colonna TF ( term frequency ) è misurata la frequenza relativa media della parola nel singolo documento. E' la vecchia keyword density.
Nella colonna W ( words ) è indicato il numero medio delle parole nei documenti analizzati.
In pratica, la lunghezza media dei documenti in cui la parola è presente.

Altre informazioni interessanti sono contenute nelle colonne HTML, TXT e LT.
Personalmente trovo molto utile la prima ( HTML ).
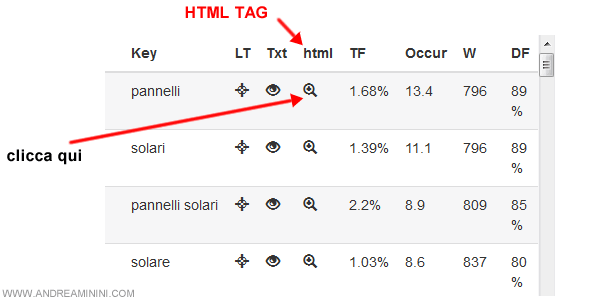
Nella colonna HTML il tool mi indica in quali tag ( H1, H2, H3, P, Title, Metatag, ecc. ) è stato rilevata la keyword.
Per vedere queste info devo soltanto cliccare sull'icona HTML sulla riga della parola chiave.

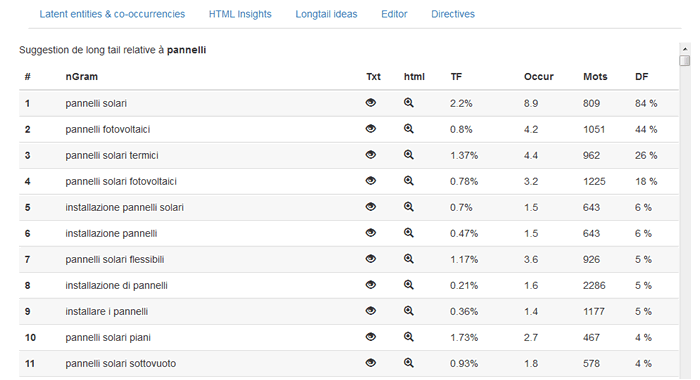
L'icona LT ( Long tail ) mi fornisce un elenco di parole chiave secondarie della stessa keyword.
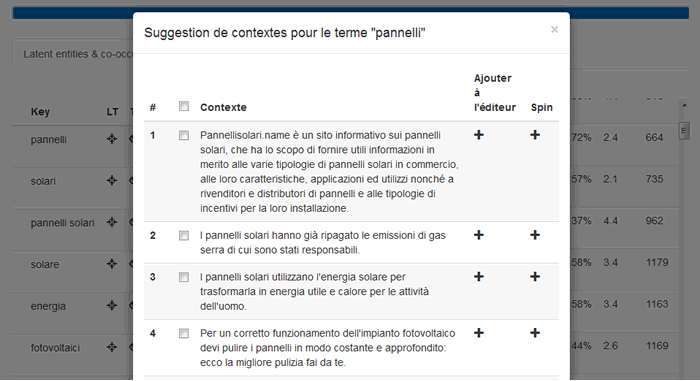
Infine, l'icona TXT elenca alcune frasi di esempio in cui il termine è stato impiegato.
Complessivamente, mi sembra un tool utile e interessante per approfondire il lessico di un tema, argomento e contesto.
Il tool è utile anche per la Latent Semantic Analysis (LSA).
E' abbastanza semplice da utilizzare.
Attenzione. Il tool analizza i documenti online, non le query degli utenti. Pertanto, può essere fuorviante per finalità marketing se utilizzato per studiare i bisogni degli utenti, i significati e le domande latenti dei consumatori. C'è il rischio di ottenere un lessico troppo tecnico. Essendo documenti ben posizionati su Google, dovrebbero essere quelli con la User Experience più alta. Tuttavia, non è sicuro che lo siano. Per finalità marketing è preferibile analizzare le query degli utenti.




