Analisi delle keyword nel contesto
L'analisi delle keyword tradizionale
I primi motori di ricerca analizzavano le singole parole all'interno di un testo. Questi algoritmi si basavano su semplici funzioni matematiche. Per calcolare il valore di un testo rispetto a una determinata keyword, questi algoritmi misuravano la frequenza della keyword all'interno di un testo, la posizione nel titolo, i link in entrata, ecc. Si trattava di algoritmi abbastanza stupidi, quasi meccanici, ed era molto facile ingannarli.
Nell'analisi delle keyword non erano prese in considerazione le altre parole del testo, né il significato semantico delle frasi. Ad esempio, nei seguenti testi A e B la keyword "carta di credito" ha la medesima frequenza e peso. Tuttavia, il primo testo parla effettivamente delle carte di credito, il secondo invece parla di alberghi.

L'analisi del contesto, intorno alle keyword
Nel corso degli anni duemila i motori di ricerca hanno compreso l'importanza dell'insieme delle parole ossia del contesto in cui si trovano le keyword. Data una keyword gli algoritmi verificano l'attinenza delle altre parole del contesto, controllando se esiste un legame tra queste e la keyword ricercata ( analisi del contesto ).

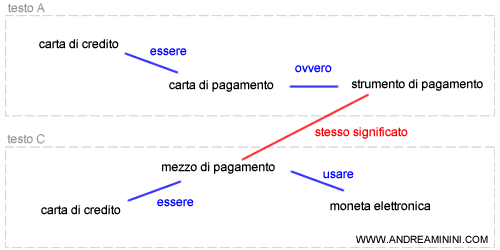
In questo modo gli algoritmi riescono a comprendere che il testo B, a parità di frequenza e di peso della keyword, non fornisce alcuna informazione utiile sulle carte di credito. Si tratta di un importante passo in avanti che non mette però al riparo dai contenuti duplicati e dalle rielaborazione dei testi con altre parole. Ad esempio, i seguenti testi A e C hanno il medesimo contesto, sono scritti in modo diverso ma forniscono le stesse informazioni.

Attualmente i motori di ricerca non sono in grado di comprendere il vero valore aggiunto dei testi e basano il calcolo del ranking soltanto sull'analisi del contesto e all'autorevolezza della fonte. Non riuscendo a comprendere il valore aggiunto semantico dei testi, gli attuali motori di ricerca associano una maggiore importanza il testo pubblicato dalla fonte più autorevole. Si tratta di un criterio di selezione poco intelligente. A volte funziona, a volte no. Ad esempio, alcune fonti sono molto autorevoli ( es. dizionari online ) ma forniscono soltanto una spiegazione sintetica di un concetto ( es. glossario ). Altre fonti, invece, pur essendo poco autorevoli o sconosciute ( es. blog ) potrebbero forniscono informazioni ad elevato valore aggiunto sul medesimo concetto. Del resto la lunghezza del testo non è una variabile affidabile per comprendere il valore informativo di un testo. Un testo lungo potrebbe essere infarcito di frasi inutili e commenti, al solo scopo di "allungare il brodo". Come capire se un testo è veramente utile? L'analisi contestuale non è sufficiente. È necessario abbandonare le euristiche meccaniche e affidarsi all'analisi semantica.
Dall'analisi del contesto all'analisi semantica
In futuro i motori di ricerca impareranno a capire il significato delle frasi di un testo, verificando se le informazioni contenute sono effettivamente veritiere o se sono semplici rielaborazioni di testi già esistenti su internet. Ad esempio, le prime frasi del testo A e del testo C hanno il medesimo significato pur utilizzando parole differenti. I due testi hanno lo stesso valore informativo.
Attualmente l'analisi semantica è già una realtà per concetti molto semplici. Nei prossimi anni i motori di ricerca potranno utilizzare grandi banche dati semantiche che gli consentiranno di calcolare il valore aggiunto di un testo rispetto agli altri presenti in rete. Questo parametro si aggiungerà a quello dell'autorevolezza della fonte che, di per sé, non garantisce sempre un'informazione di qualità. Con l'analisi semantica i motori di ricerca diventeranno veri e propri sistemi esperti in grado di fornire risposte alle domande degli utenti tramite un processo inferenziale basato sull'intelligenza artificiale. L'era dei motori di ricerca potrebbe, quindi, finire e lasciare il posto a quella dei risponditori automatici. 15 / 04 / 2014




