Contenuti originali
Un contenuto informativo dovrebbe essere sempre originale, inedito e utile. Le frasi copiate da altri siti web sono un cattivo segnale per i motori di ricerca, in quanto possono ridurre la reputazione del sito che pubblica i contenuto duplicati.
Gli algoritmi dei search enegine sono in grado di riconoscere i contenuti copiati sia integralmente che parzialmente ( singole frasi o paragrafi ). E' sufficiente estrapolare le frasi di un documento e verificare se le singole frasi sono già state indicizzate su altri siti web.
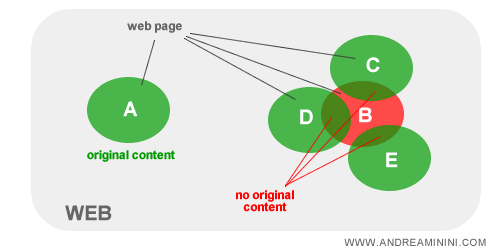
Ad esempio, nel seguente caso il contenuto della pagina A è composto da frasi originali. Viceversa, il contenuto della pagina B è composto da alcune frasi già presenti sul web nelle pagine C, D ed E. La pagina B non è un contenuto originale.
Purtroppo, i motori di ricerca non sempre sono in grado di capire la fonte di un contenuto duplicato. Può capitare che un sito web sconosciuto sia penalizzato, nel caso in cui altri siti più autorevoli duplicano il suo contenuto informativo senza citarlo come fonte.
In passato i search engine usavano la data di indicizzazione del documento per individuare la fonte di un documento. Questa prassi è stata ridimensionata a causa degli aggregatori. Questi siti non producono dei contenuti originali, si limitano ad aggregare i contenuti parziali tratti da altri siti web.
Essendo dei siti continuamente aggiornati, gli aggregatori godevano di una frequenza di passaggio dello spider più alta rispetto agli altri siti ed erano indicizzati prima degli altri dal crawler. Questo fenomeno causava dei problemi sulle SERP. I search engine tendevano a visualizzare nelle prime posizioni gli aggregatori semplicemente perché li trovavano prima.
Per evitare questo problema i search engine passarono a utilizzare l'autorevolezza del sito. In caso di dubbi, tendono a considerare come fonte informativa il sito più autorevole che pubblica il contenuto duplicato. Anche se il sito originale, quello che ha pubblicato il contenuto originale, è stato indicizzato dal search engine prima di tutti gli altri.
I contenuti duplicati o rielaborati sono da evitare
Oggi i testi duplicati o rielaborati sono riconosciuti più facilmente e sono eliminati dalle serp dai filtri del search engine.
Grazie alla campo semantico delle parole e agli algoritmi di stemming, il search engine ha imparato a riconoscere i sinonimi dei termini.
Ad esempio, se un testo usa le stesse parole di un altro oppure dei sinonimi ( testo rielaborato ) senza offrire alcun valore aggiunto, il motore di ricerca visualizza soltanto quello della fonte più autorevole.




