Apprendimento cumulativo
L'apprendimento cumulativo ( o incrementale ) è una tecnica di machine learning in cui la macchina ha una conoscenza pregressa e impara man mano che acquisisce nuova conoscenza.
La tecnica si basa comunque sull'apprendimento induttivo ma valorizza la knowledge già acquisita in memoria. Le nuove conoscenze non si sostituiscono alle precedenti, bensì le integrano e le modificano.
E' una tecnica apprendimento automatico per eliminazione graduale delle ipotesi.
Come funziona l'apprendimento incrementale
Inizialmente la macchina è dotata di una knowledge base pregressa.
In genere, è un database di conoscenza con regole di base programmato dal progettista.
Questa conoscenza di base delinea lo spazio delle ipotesi che la macchina prende in considerazione durante l'apprendimento.
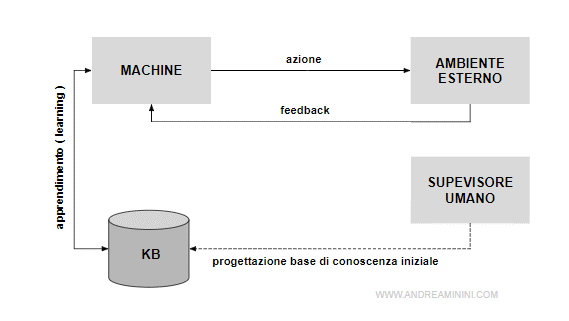
Nel corso del tempo la macchina modifica lo spazio delle ipotesi man mano che acquisisce la nuova conoscenza.
Quindi, la conoscenza pregressa non è cancellata ogni volta che ne subentra un'altra, bensì modificata.
Nota. La conoscenza pregressa influisce sensibilmente sul processo di apprendimento, perché i nuovi dati sono valutati in base alla conoscenza corrente. Questa caratteristica migliora la sicurezza del sistema. Da un lato riduce il rischio di subire modifiche troppo radicali e repentine al processo di classificazione. D'altro canto, non chiude del tutto la porta al cambiamento delle ipotesi. La macchina impara ma con prudenza.
Qual è il vantaggio della conoscenza pregressa?
Secondo i test compiuti in laboratorio, gli agenti con una conoscenza pregressa trovano più velocemente un metodo di classificazione consistente rispetto a quelli che partono da zero.
Un esempio pratico
Una macchina è istruita per riconoscere un particolare tipo di fiore, ad esempio le margherite, in base all'altezza dello stelo e alla larghezza del petalo.
Lo spazio delle ipotesi è composto dall'insieme dei dati iniziali.
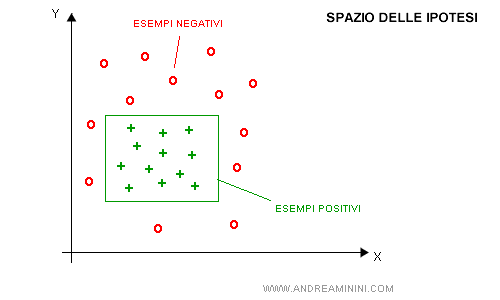
Nota. I simboli + e O indicano rispettivamente gli esempi positivi e negativi della classificazione. In pratica, sono gli esempi classificati correttamente perché positivi o negativi.
Nel corso del tempo la macchina acquisisce nuovi dati per induzione.
Nei nuovi dati emergono due situazioni anomale:
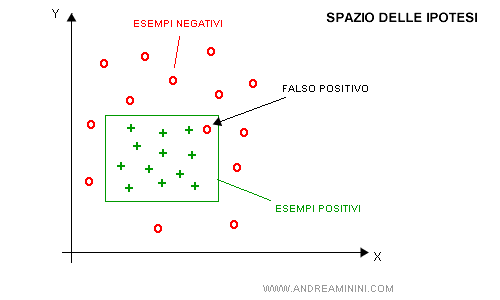
- Un falso positivo. E' un esempio che viene classificato come positivo ma non lo è. Ad esempio, una pianta erbacea ha fiori simili alla margherita ma non sono margherite. Inizialmente la macchina le classifica come margherite.
- Un falso negativo. E' un esempio che non viene classificato perché sembra negativo, in base all'attuale metodo di classificazione, ma in realtà è un esempio positivo. Ad esempio, una margherita più alta del solito.
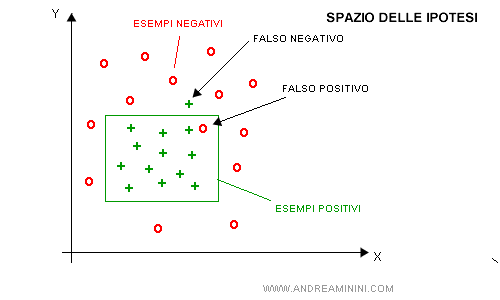
Quando l'agente riconosce un falso positivo, deve modificare le regole di classificazione per escluderlo.
Lo spazio delle ipotesi si riduce per specializzazione.
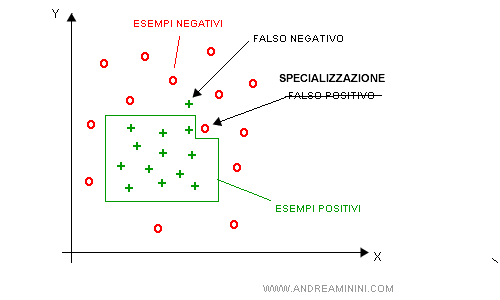
Viceversa, quando l'agente riconosce un falso negativo, deve modificarle per includerlo.
In questo caso lo spazio delle ipotesi viene ampliato per generalizzazione.
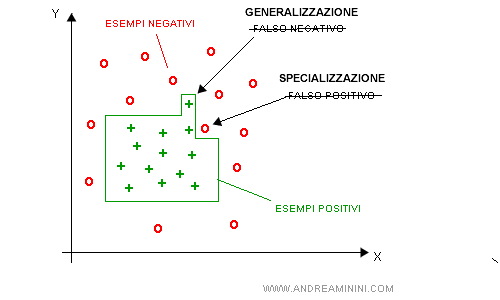
Così facendo, l'agente migliora lo spazio delle ipotesi, rendendolo più consistente con la realtà osservata.
Tecniche di apprendimento cumulativo
L'apprendimento cumulativo può essere sviluppato secondo due modelli di algoritmo:
- Algoritmo dell'ipotesi migliore. L'algoritmo della ricerca migliore mantiene in memoria soltanto l'ipotesi corrente. Pertanto, impegna uno spazio di memoria ridotto. Ha una bassa complessità spaziale.
Esempio. Quando l'algoritmo analizza un esempio, modifica l'ipotesi corrente. Non conserva in memoria tutti i possibili spazi delle ipotesi ma soltanto le variazioni apportate.
Tuttavia, non è detto che l'apprendimento sia sempre miglioratvo. L'algoritmo potrebbe trovarsi anche in una situazione peggiore o in un vicolo cieco.In questi casi, per uscire dall'impasse l'algoritmo deve annullare l'ultima modifica e tornare indietro con un'operazione di backtracking.Nota. Il backtracking è un'attività utile ma molto rischiosa, perché aumenta il tempo di esecuzione del programma ( complessità temporale ). Inoltre, ogni modifica per rendere consistente un esempio potrebbe rendere inconsistenti quelli analizzati precedentemente. E' quindi necessario rivalutare tutti gli esempi dopo ogni modifica allo spazio delle ipotesi.
- Apprendimento con spazio delle versioni ( Version Space ). L'algoritmo mantiene in memoria più ipotesi. Man mano che arrivano nuovi esempi, l'algoritmo elimina le ipotesi non consistenti dallo spazio delle ipotesi. Ciò che resta è detto spazio delle versioni ( version space ). E' un approccio incrementale perché non richiede nessun backtracking.
Nota. Questo approccio richiede un notevole spazio di memoria, perché lo spazio delle ipotesi deve essere inizialmente caricato in memoria. Tuttavia, lo spazio delle ipotesi potrebbe essere molto grande. Inoltre, l'algoritmo presuppone "ottimisticamente" che lo spazio delle ipotesi contenga la soluzione del problema. Il che... non è detto.




