Machine Learning ( ML )
Il machine learning ( ML ) è un sistema di apprendimento automatico, in grado di imparare dagli esempi, dal ragionamento e dall'esperienza. E' uno dei campi di studio dell'intelligenza artificiale.
Una macchina apprende con l'esperienza se la sua performance a svolgere un compito migliora nel corso del tempo dopo averlo svolto più volte ( definizione di Tom Michael Mitchell ).
Per auto-apprendimento si intende la capacità di un sistema informatico ( computer ) di assimilare le nuove informazioni senza l'intervento da parte dell'uomo e di miglorare la capacità decisionale.
A cosa serve il machine learning
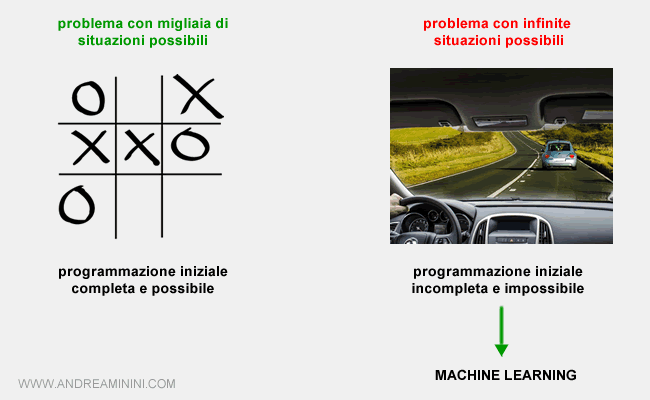
Il machine learning consente alla macchina di affrontare situazioni e problemi non previsti dalla programmazione iniziale, prendendo decisioni e compiendo azioni non programmate.
Nota. In alcuni problemi è impossibile prevedere tutte le possibili situazioni. Il programmatore non può conoscere tutte le situazioni, né prevedere i cambiamenti del mondo o conoscere la soluzione di un problema. Quando la macchina si trova in una situazione non prevista dalla programmazione iniziale, si blocca o la ignora. Per questa ragione è preferibile lasciare alla macchina un margine di autonomia decisionale e dargli la capacità di imparare.
Nel corso del tempo la macchina acquisisce nuove conoscenze e migliora la sua capacità decisionale.
Il software modifica se stesso con l'esperienza ed è in grado di imparare dai propri errori.
Come funziona il machine learning
Nel machine learning il comportamento degli algoritmi non è pre-programmato ma appreso dai dati.
Il computer apprende la nuova conoscenza in vari modi:
- dall'osservazione dell'ambiente esterno
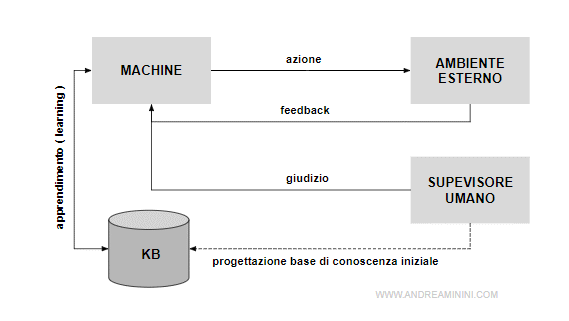
l'agente osserva il mondo esterno e impara dai feedback delle sue azioni e dai suoi errori. - dalla base di conoscenza
l'esperienza e la conoscenza dell'ambiente operativo sono conservate in un database detto base di conoscenza ( knowledge base o KB ).

Le due modalità di apprendimento sono complementari.
L'una non esclude l'altra.
Nota. Esistono diversi livelli di machine learning. Alcuni prevedono anche la supervisione umana. Ad esempio, inizialmente la base di conoscenza non è mai vuota ma contiene alcune informazioni iniziali inserite manualmente dal progettista ( conoscenza pre-esistente o pregressa ). Successivamente, durante il processo di apprendimento, la base cognitiva ( KB ) viene modificata dall'agente tramite i feed-back con l'ambiente, in base alla sua esperienza diretta maturata nel corso del tempo. Un supervisore umano potrebbe anche intervenire durante il processo ML con dei giudizi qualitativi per aiutare l'apprendimento automatico della macchina.
Le tecniche di machine learning
Le principali tecniche di machine learning sono le seguenti:
- Apprendimento supervisionato ( supervised learning )
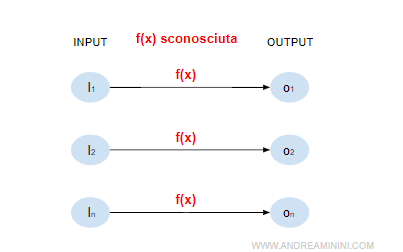
Il progettista fornisce una serie di esempi alla macchina. Ogni esempio è composto una serie di valori di input ed è accompagnato da un'etichetta in cui il progettista indica il risultato o un giudizio di valore. La macchina elabora i dati e apprende dagli esempi per individuare una funzione predittiva o una regola generale.
Pro e contro. Questo tipo di machine learning si adatta bene agli ambienti completamente osservabili e in presenza di un istruttore umano. E' invece poco efficace se analizza i feedback negli ambienti parzialmente osservabili (PO) perché l'agente non riesce a individuare le relazioni di causa-effetto in condizioni di certezza. L'agente è come un bambino che apprende dall'ambiente e dai genitori.
- Apprendimento non supervisionato ( unsupervised learning )
Nell'apprendimento non supervisionato l'agente non ha esempi di input-output da testare. Non c'è un istruttore a decidere se un'azione è corretta o no, né una misura di riferimento per i feedback dell'ambiente. Può comunque apprendere l'esistenza di un legame tra alcuni fattori di input e di output. In pratica, la macchina impara dai propri errori e dall'esperienza.
Pro e contro. Un agente che apprende in modo non supervisionato è incapace di decidere, perché non sa distinguere tra il bene e il male, non sa quale azione è corretta, né quali siano gli obiettivi della sua azione. Non c'è un supervisore a spiegarglieli, né riceve degli esempi iniziali da analizzare. Inoltre, non conosce nemmeno gli input perché deve trovarli da sé. Può comunque costruirsi una funzione realistica e rappresentativa del funzionamento di un ambiente. L'agente è come un bambino cresciuto nella giungla.
- Apprendimento per rinforzo ( reinforcement learning )
L'apprendimento per rinforzo si basa sul meccanismo dei premi, delle ricompense e delle punizioni. L'agente non ha esempi di input e output, né una supervisione che gli spieghi il comportamento corretto da seguire. Tuttavia, ha una funzione di rinforzo associata a un obiettivo da raggiungere che gli permette di valutare i feedback delle azioni. In questo modo, con l'esperienza l'agente costruisce una funzione di comportamento in grado di massimizzare il rinforzo ( premio ). In pratica, la macchina conosce l'obiettivo ma non sa come raggiungerlo.
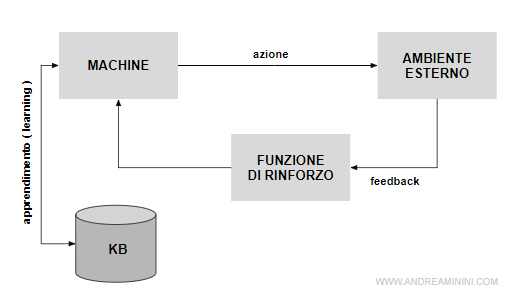
Pro e contro. Questo approccio unisce i pregi dell'apprendimento supervisionato e non supervisionato. L'agente non segue gli schemi input-output del progettista e non necessita di un supervisore umano. Quindi, ha meno vincoli per costruire una funzione rappresentativa dell'ambiente. Inoltre, grazie al rinforzo, può distinguere i comportamenti desiderabili da quelli negativi, e perseguire un obiettivo ( massimizzare la ricompensa ). Il rinforzo ha anche una funzione di indirizzo. L'agente è come un giovane che cerca il suo primo lavoro.

Le fasi del processo di machine learning
Le fasi del machine learning sono le seguenti:
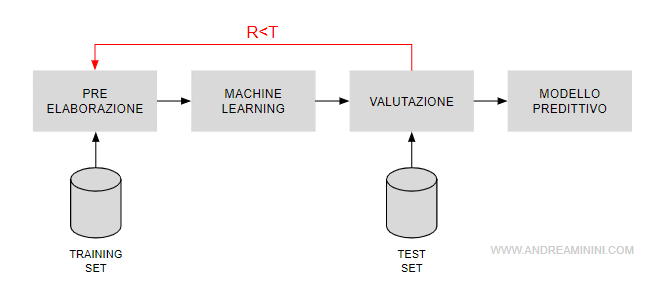
- Pre-Processing. E' la fase in cui analizzo i dati nel dataset di apprendimento per ottimizzare le performance dell'algoritmo.
- Apprendimento. E' la fase in cui l'algoritmo apprende automaticamente dai dati presenti nel dataset di apprendimento ( training set ) per elaborare un modello previsionale.
- Valutazione. E' la fase in cui valuto se il modello previsionale creato dall'algoritmo è accurato oppure no. Per valutare la qualità predittiva fisso una percentuale T di risposte esatte come parametro di riferimento. Provo il modello predittivo con un dataset di test ( test set ), diverso dal dataset di apprendimento, e analizzo i risultati.
- R≥T Se la percentuale di risposte esatte R supera la soglia T, il modello predittivo viene promosso. Le risposte della macchina sono sufficientemente accurate. Il margine di errore delle risposte è accettabile.
- R<T Se la percentuale di risposte esatte R non supera la soglia T, il processo riparte dalla fase pre-processing perché la qualità previsionale non è sufficientemente efficace.
- Predizione. E' la fase finale di applicazione, quella in cui il modello predittivo è usato con i dati reali per risolvere dei problemi pratici, da parte della macchina stessa o degli utenti finali.
Il pre-processing
La fase di pre-processing viene eseguita prima di avviare un processo di apprendimento automatico.
A cosa serve?
Nella fase di pre-processing sono analizzati i dati nel dataset per individuare le informazioni ridondanti e i rumori.
- I rumori (dati irrilevanti) sono eliminati dal dataset.
- I dati correlati (ridondanti) sono combinati tra loro.
Questo mi permette di ottenere la riduzione della dimensionalità del dataset e un discreto miglioramento nella complessità computazionale dell'algoritmo di apprendimento.
La rappresentazione della conoscenza
Le informazioni acquisite dalla macchina possono essere rappresentate in vari modi.
I principali sono i seguenti:
- logica proposizionale
- logica del primo ordine
- reti bayesiane
- reti neurali
- alberi decisionali
La rappresentazione della conoscenza è uno degli aspetti tecnici più importanti nello studio del machine learning, perché influisce sensibilmente sulla complessità spaziale e temporale dell'algoritmo.




