L'apprendimento supervisionato
L'apprendimento supervisionato ( supervised learning ) è un tipo di apprendimento automatico delle macchine.
Perché si chiama supervisionato? Per supervisione si intende la presenza delle soluzioni ( etichette ) nell'insieme di dati di addestramento. Una persona ( supervisore ) fornisce alla macchina degli esempi pratici alla macchina. In ogni esempio sono indicate le variabili di input (x) e il risultato corretto (y). La macchina impara dagli esempi ed elabora un modello predittivo.
Il machine learning supervisionato è probabilmente l'apprendimento automatico più frequentemente utilizzato nella pratica.
Un esempio pratico
Prendo un campione di email e aggiungo su ciascuna un'etichetta ( "spam" o "no spam" ).
La macchina elabora i miei esempi per stimare una regola di riconoscimento generale detta modello.
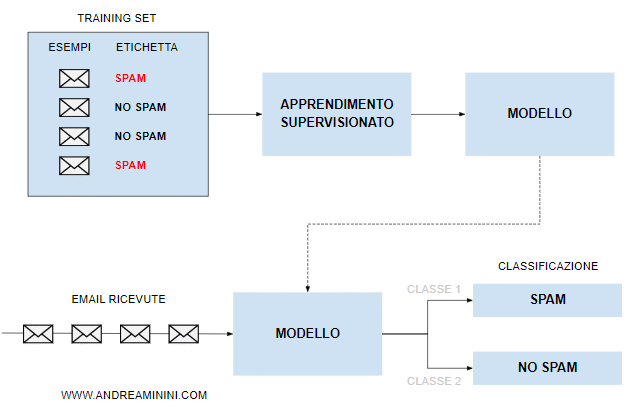
Una volta individuato il modello, la macchina lo usa per classificare tutte le email in entrata in spam e no spam.
In questo modo ho creato un semplice filtro antispam intelligente.
Questo algoritmo è detto algoritmo di classificazione.
Come funziona l'apprendimento supervisionato
Nell'apprendimento supervisionato la macchina deve stimare una funzione f(x) incognita che collega le variabili di input x a una variabile di output y.
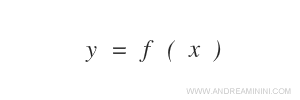
La macchina non conosce la funzione f(x).
Il suo scopo è stimare una funzione ipotesi h(x) in grado di approssimare la f(x).
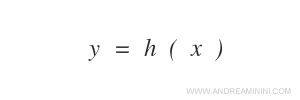
Per farlo analizza un insieme di dati detto training set fornito dal supervisore.
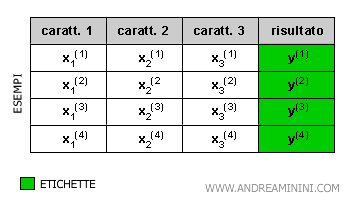
Un training set è un insieme di addestramento composto da un insieme di coppie (x, y).
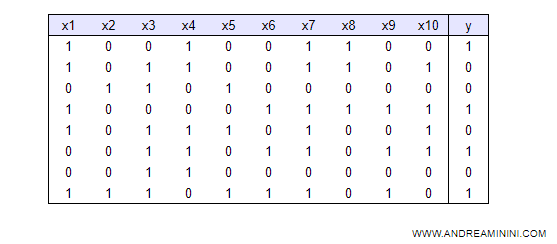
Nota. Ogni riga della tabella è un esempio. Dove Xn può essere una variabile di input o un vettore composto da più variabili di input, mentre y è il risultato finale. Alcuni algoritmi di ML possono lavorare anche con dati non numerici. Tuttavia, in generale gli algoritmi di machine learning supervisionati lavorano soltanto con dati numerici. Pertanto, se il dataset contiene dati non numerici (es. stringhe) devono essere prima convertiti in dati numerici.
Pertanto, l'input di un algoritmo di machine learning supervisionato è una matrice con esempi etichettati.
A partire da questi dati la macchina elabora la funzione ipotesi h(x).
Come capire se la funzione ipotesi è corretta?
La macchina deve valutare l'accuratezza della funzione ipotesi h(x), se approssima o meno la funzione f(x). Tuttavia non conosce la funzione f(x).
Per capirlo utilizza un altro insieme di dati, detto test set, fornito sempre dal supervisore.
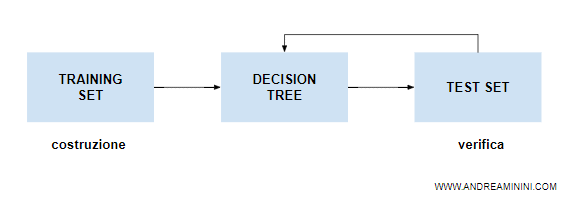
Nota. Sia il training set che il test set sono forniti dal supervisore umano. Tuttavia, i due insiemi sono composti da esempi diversi. Quindi, è opportuno che siano preparati da supervisori diversi e non siano sempre gli stessi.
A questo punto la macchina risponde agli Nt esempi del test set.
Poi confronta ogni sua risposta R con la risposta corretta indicata dagli esperti (Y) nel test set.
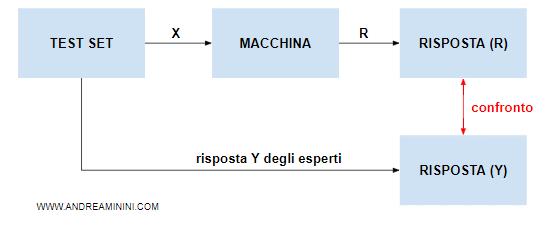
Le risposte coincidente ( R=Y ) incrementano il numero delle risposte corrette Rc della macchina.
Se la percentuale di risposte corrette Rc/Nt della macchina è soddisfacente, la funzione ipotesi h(x) supera l'esame e viene accolta.
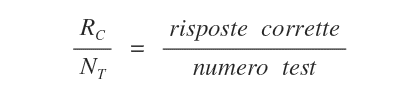
In caso contrario l'apprendimento supervisionato riparte con l'analisi di un ulteriore training set.
E il ciclo ricomincia da capo.
Qual è l'output dell'apprendimento supervisionato?
I risultati in output di un algoritmo di ML supervised possono essere
- numeri reali
- etichette
- vettori
- sequenze
Tipi di apprendimento supervisionato
Le principali categorie dell'apprendimento supervisionato sono:
- La classificazione. La macchina viene addestrata alla classificazione dal supervisore tramite l'aggiunta di etichette sui dati in cui giudica il risultato. Ogni etichetta è una classe discreta che identifica il risultato atteso ( es. spam o no spam ) oppure un giudizio di valore.
- La regressione lineare. Nella regressione lineare il risultato ( output ) è un valore continuo. Alla macchina spetta il compito di trovare una relazione tra i valori di input ( valori descrittivi ) e di output.




