La differenza tra bias e varianza nel machine learning
Nel machine learning il bias e la varianza sono i due concetti fondamentali che influenzano significativamente la prestazione di un modello. Saper bilanciare questi due elementi è cruciale per lo sviluppo di modelli efficaci.
- Bias
Il bias misura l'accuratezza delle previsioni di un modello sui dati su cui è stato addestrato. Se il modello predice bene questi dati, ha un basso bias. Un modello con alto bias, invece, commette errori frequenti sugli stessi dati di addestramento, indicando una scarsa adattabilità.Questa situazione, nota come underfitting, si verifica quando il modello è troppo semplice o le sue caratteristiche non sono sufficientemente rappresentative per i dati trattati.
- Varianza
La varianza si concentra su quanto le previsioni del modello variano quando applicate a diversi set di dati. Un alto livello di varianza si manifesta quando un modello addestrato su un set di dati specifico non riesce a fare previsioni accurate su nuovi dati.Questo fenomeno, chiamato overfitting, è il risultato di un modello eccessivamente complesso che si adatta troppo strettamente ai dati di addestramento, perdendo la capacità di generalizzare.
Il vero dilemma nel machine learning è il trade-off tra bias e varianza. Aumentando la complessità di un modello, si riduce il bias ma si aumenta la varianza, e viceversa.
Il modello ideale è quello che minimizza sia il bias, per assicurare accuratezza sul training set, sia la varianza, per garantire la generalizzabilità del modello a nuovi dati.
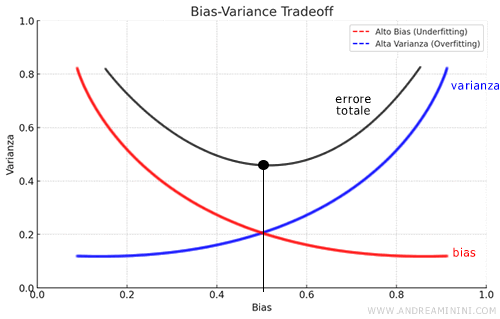
Quindi, bilanciare bias e varianza è fondamentale per ottimizzare le prestazioni complessive del modello.
La sfida è creare un modello che non sia né troppo semplice (rischiando underfitting) né eccessivamente complesso (rischiando overfitting), ma che abbia il giusto equilibrio per funzionare bene sia sui dati di addestramento che su quelli nuovi.
Nota. Per saperne di più sulla differenza tra overfitting e underfitting.
Questo equilibrio può essere raggiunto tramite tecniche come la regolarizzazione ed è fondamentale per la realizzazione di modelli di apprendimento automatico efficaci e generalizzabili.
L'ideale sarebbe avere un modello che minimizza sia il bias che la varianza ma, spesso, questo non è possibile se il problema predittivo è complesso.
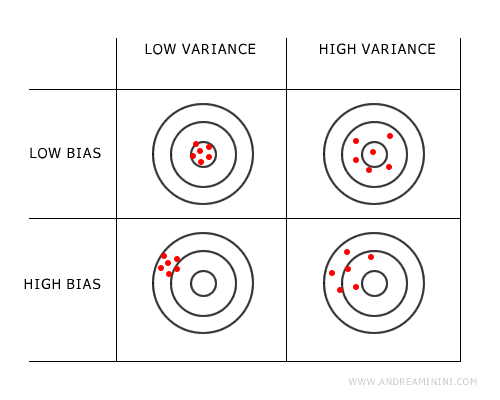
A seconda del problema e dell'obiettivo da raggiungere potrei anche scegliere di minimizzare il bias sacrificando un po' la varianza o viceversa, oppure trovare il giusto equillibrio tra le due.
Di sicuro non esiste una scelta generale valida per ogni situazione.
E così via.




