L'apprendimento con rinforzo
L'apprendimento con rinforzo ( reinforcement learning o RL ) è una tecnica di machine learning in cui l'agente apprende la conoscenza tramite una funzione di rinforzo. E' anche detto apprendimento di rafforzamento o per rinforzo.
Come funziona il reinforcement learning
Nel machine learning RL l'agente riceve in input un obiettivo da raggiungere .
Inizialmente l'agente conosce l'obiettivo ma non sa raggiungerlo, perché non ha un dataset di esempi per fare l'addestramento, né una base di conoscenza pregressa.
Nel reinforcement learning l'agente deve imparare dall'esperienza e costruirsi da sé una Knowledge Base (KB).
Nota. Si tratta di una semplificazione voluta per spiegare meglio il RL. In realtà, è sempre utile avere una piccola conoscenza pregressa iniziale anche nel RL, perché permette di evitare gli errori irreversibili durante il processo di apprendimento esperienziale.
Come impara dall'esperienza?
In primo luogo l'agente osserva l'ambiente che lo circonda e lo trasforma in un vettore di caratteristiche X.
Ogni combinazione di elementi del vettore è un diverso stato dell'ambiente.
Esempio. L'agente deve decidere se uscire con l'ombrello oppure no. L'ambiente operativo può essere definito da tre caratteristiche binarie: x1=piove, x2=nuvoloso, x3=vento. Ogni caratteristica ha per semplicità un valore binario (1=si, 0=no). $$ X = \{ x_1, x_2, x_3 \} $$ Ad esempio, il vettore delle caratteristiche può rappresentare i seguenti stati dell'ambiente $$ X_1 = \{ 1, 1, 0 \} \\ X_2 = \{ 1, 1, 1 \} \\ X_3 = \{ 0, 1, 0 \} \\ \vdots $$
Quando l'agente prende una decisione, analizza il cambiamento dello stato dell'ambiente valutando i feed-back tramite una funzione di rinforzo.
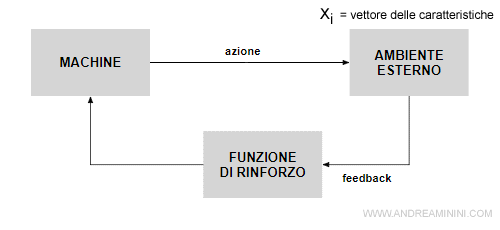
Cos'è la funzione di rinforzo
La funzione di rinforzo ( o funzione di rafforzamento ) misura il grado di successo di un'azione o decisione, rispetto a un obiettivo predeterminato.
- Ricompensa. Se il feed-back è positivo, l'agente si è avvicinato all'obiettivo dopo l'azione e la funzione di rinforzo assegna un premio ( ricompensa ) alla macchina. La ricompensa è un valore reale positivo.
- Penalizzazione. Se il feed-back è negativo, l'agente si è allontanato dall'obiettivo dopo l'azione e la funzione di rinforzo assegna una penalizzazione ( penalty ) alla macchina. La penalizzazione è un valore reale negativo.
Nota. Ho semplificato lo schema della funzione di rinforzo per spiegare meglio il funzionamento. In realtà, la ricompensa e la penalizzazione non sono assegnate dopo una singola azione bensì dopo una sequenza di azioni. Altrimenti la macchina non potrebbe mai fare un passo indietro per farne due in avanti.
Mentre fa esperienza la macchina raccoglie preziose informazioni sui feed-back delle azioni e le registra nella Knowledge Base (KB).
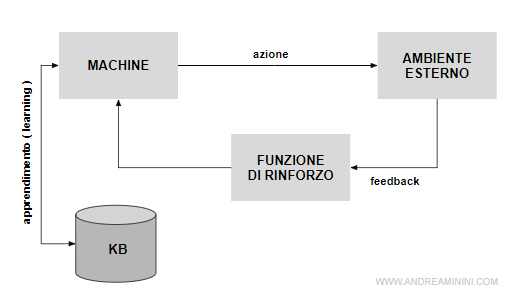
Lo scopo dell'agente è la massimizzazione della funzione di rinforzo.
Nella KB a ogni stato dell'ambiente Xi associa le azioni con la ricompensa più alta.
Esempio. Se l'obiettivo è non bagnarsi e il vettore dello stato indica una situazione in cui piove, è nuvoloso e c'è vento $$ X_i=(1,1,1) $$ la decisione di portare con sé l'ombrello ottiene sicuramente una ricompensa più alta rispetto alla decisione di uscire di casa senza.
Questo permette all'agente di ripetere nel tempo le azioni più profittevoli ed evitare quelle in perdita in ogni stato dell'ambiente Xi.
In pratica, l'agente impara a vincere giocando le partite.
Nota. I dati raccolti nella KB sono simili a un dataset etichettato (training set) e sono utili per generalizzare il modello statistico decisionale anche a quegli stati su cui la macchina non ha ancora informazioni sufficienti. In modo simile al machine learning supervisionato. Ad esempio, la macchina conosce che è utile portare l'ombrello se piove, è nuvoloso e c'è vento X=(1,1,1). Tuttavia, non ha informazioni sullo stato in cui piove, è nuvoloso ma non c'è vento X=(1,1,0). In questo caso, la macchina può comunque decidere per vicinanza di portare l'ombrello.
Pro e contro del reinforcement learning
Il reinforcement learning (RF) unisce i vantaggi dell'apprendimento supervisionato e non supervisionato.
- Apprendimento non supervisionato. Come nell'apprendimento non supervisionato, nel RF la macchina non è legata a una tabella di esempi con input e output scritti da un progettista. Quindi, è meno legata al contenuto del training set e può prendere le decisioni con meno vincoli e un maggiore grado di libertà. Tuttavia, a differenza dell'apprendimento non supervisionato, l'agente non inizia il processo di apprendimento senza conoscenza pregressa. Nel reinforcement learning la macchina può distinguere fin da subito le azioni positive e negative tramite una funzione di rinforzo.
- Apprendimento supervisionato. Come nell'apprendimento supervisionato, nel RF l'agente è aiutato nel processo di apprendimento. Tuttavia, i feedback non sono etichette aggiunte da un supervisore negli esempi dell'insieme di training ma una funzione matematica di rafforzamento. Pertanto, a differenza dell'apprendimento supervisionato, nel RF la macchina è in grado di valutare anche situazioni non previste inizialmente dal progettista.
E così via




