La differenza tra classificazione e regressione
Gli algoritmi di machine learning sono divisi in due grandi famiglie: classificatori e regressori.
I classificatori (classification) separano i dati in classi mentre i regressori (regression) interpolano i dati. Quindi, l'output di un modello classificatore è una classe mentre l'output di un modello regressore è un dato numerico.
I classificatori
I classificatori separano i dati in due o più classi. Quando fornisco un esempio al classificatore, l'algoritmo mi restituisce la classe a cui potrebbe appartenere.
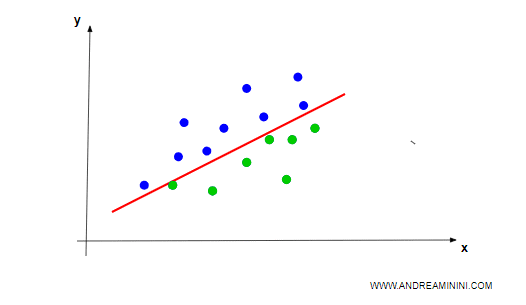
Esempio. Scrivo una lettera su un foglio di carta, la fotografo e invio l'immagine all'algoritmo classificatore. L'algoritmo elabora l'immagine e associa ciò che ho scritto a una lettera dell'alfabeto (classe).
La classificazione può essere lineare o non lineare, a due o più dimensioni, ma la logica è sempre la stessa..
- I classificatori lineari sono semplici e veloci ma risentono del problema dell'underfitting.
- I classificatori non lineari sono più precisi ma più lenti da elaborare. Inoltre, c'è sempre il rischio di cadere nell'overfitting.
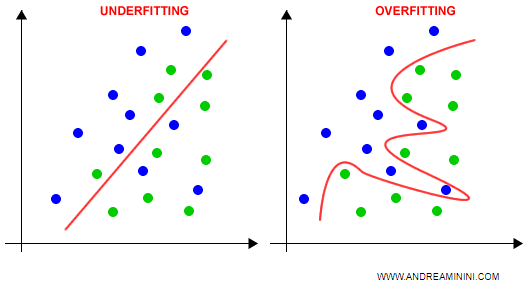
Cos'è l'overfitting? Si verifica quando il modello si adatta eccessivamente ai dati di training. Non è generalizzabile. In pratica, il modello funziona bene sui dati di addestramento, quelli usati per costruire il modello, ma funziona male sui dati che non conosce (dati di test).
I regressori
I regressori si basano sull'interpolazione dei dati per associare tra loro due o più caratteristiche (feature). Quando fornisco all'algoritmo una caratteristica in input, il regressore mi restituisce l'altra caratteristica.
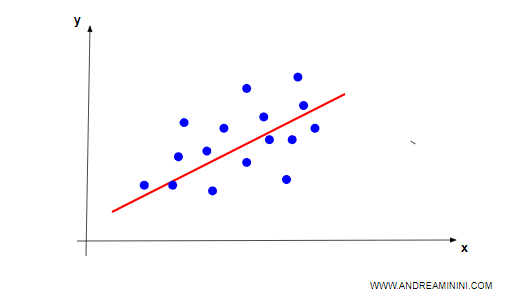
Ovviamente, la regressione può funzionare anche con più di due caratteristiche.
Esempio. Digito una lista di immobili in un database inserendo i metri quadri, la zona e il prezzo. L'algoritmo elabora l'interpolazione tra le caratteristiche. Quando digito in input i metri quadri e la zona, l'algoritmo mi restituisce in output il prezzo più probabile.
La regressione può essere lineare o non lineare, in uno spazio a due o più dimensioni, ma la logica è sempre la stessa.
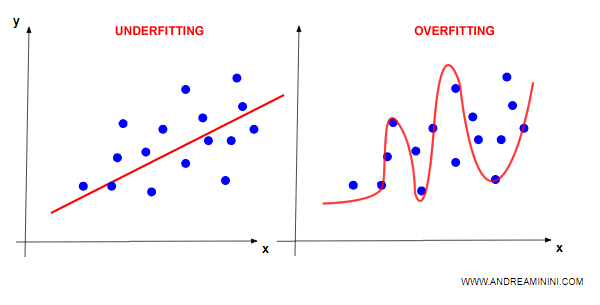
Anche nella regressione può presentarsi il problema dell'underfitting e dell'overfitting.
Per un approfondimento sulle differenze tra overfitting e underfitting.
E così via.




