La regressione nel machine learning
Nel machine learning la regressione è un problema di previsione su valori reali detti target, a partire da esempi senza etichetta. L'algoritmo di apprendimento è detto regressore.
Come funziona la regressione
Un dataset di apprendimento (training set) è composto da N esempi.
Ogni esempio è suddiviso in caratteristiche (features) ed eventualmente, nel caso del machine learning supervisionato, anche da una variabile target.
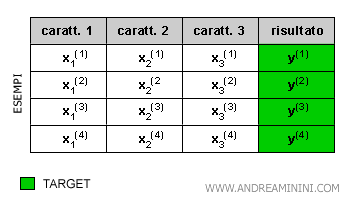
L'algoritmo di apprendimento (regressore) elabora il dataset in input e produce in output un modello previsionale in grado di calcolare il prezzo a partire dalle caratteristiche.
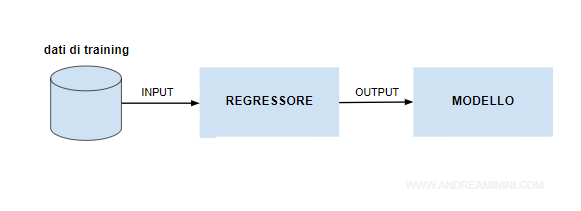
A cosa serve il modello previsionale?
Una volta costruito, il modello viene usato per calcolare la variabile target anche su esempi diversi da quelli di addestramento.
Ad esempio sui dati di test.
Il regressore è un algoritmo lineare o non lineare basato sull'algebra lineare. Può lavorare su due o più dimensioni.
- Regressione lineare
L'algoritmo è molto semplice e veloce. Tuttavia, la generalizzazione è spesso eccessiva e il tasso di errori è elevato. La stima è una retta o un piano. Uno dei problemi più frequenti è l'underfitting ( modello troppo elementare ). - Regressione non lineare (polinomiale)
L'algoritmo di apprendimento è più lento. In genere, l'accuratezza del modello previsionale è più alta rispetto ai regressori lineari perché la stima è una curva o uno spazio curvo. Tuttavia, se il regressore si adatta eccessivamente ai dati di training si rischia di cadere nel problema dell'overfitting. In quest'ultimo caso l'accuratezza potrebbe anche essere peggiore dell'underfitting.
Un esempio pratico
Un dataset è composto dagli annunci di vendita immobilitari di una città.
Ogni esempio è composto dalle caratteristiche degli immobili ( metri quadri, piano, numero camere, ecc. ) e da una variabile target ( prezzo ).
L'algoritmo elabora i dati cercando una relazione tra le caratteristiche e il prezzo.
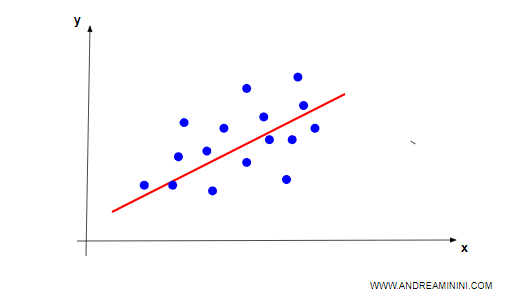
La retta (rossa) indica la variazione del prezzo al variare della caratteristica x.
Nota. Nel precedente grafico analizzo la relazione tra una caratteristica (x) e il prezzo (y). Ad esempio tra i metri quadri di una casa e il suo prezzo. E' un semplice esempio per rendere l'idea. In genere le caratteristiche sono più di una. La rappresentazione grafica sull'iperpiano diventa impossibile quando le caratteristiche sono più di due. Tuttavia, in algebra lineare si può lavorare anche su molte dimensioni ed estrapolare un prezzo anche da N caratteristiche.
Qual è la differenza tra classificazione e regressione
Nella classificazione il modello previsionale produce in output una classe o categoria.
Esempio. Il modello analizza alcune caratteristiche dei fiori e li etichetta con la specie.
Nella regressione, invece, il modello previsionale produce in output una stima numerica.
Esempio. Il modello analizza alcune caratteristiche delle case e gli assegna una stima del prezzo di mercato.
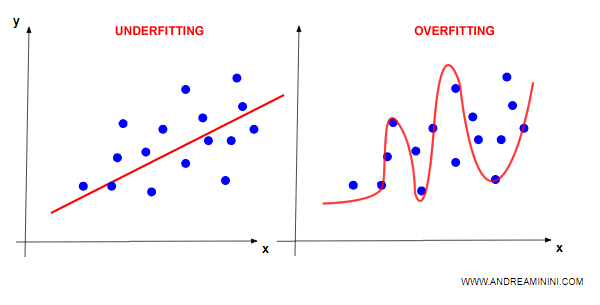
Il problema dell'underfitting e overfitting
Nella regressione si verifica il problema di underfitting e overfitting
- Underfitting. Si verifica quando la regressione è eccessivamente elementare. Il numero degli errori rispetto ai dati di training è molto alto. E' uno dei problemi più frequenti della regressione lineare.
- Overfitting. Si verifica quando la regressione si adatta ai dati di training in modo eccessivo. Il numero degli errori rispetto ai dati di training è basso. Tuttavia, il modello è poco generalizzabile. Quando viene usato come modello previsionale sui dati diversi da quelli di training il tasso di errori è molto alto. Si verifica nella regressione non lineare (o regressione polinomiale).
Per approfondire sulla differenza tra underfitting e overfitting.
E così via.




