La differenza tra overfitting e underfitting
- L'overfitting e l'underfitting sono due problemi tipici del machine learning in cui il modello raggiunge scarse performance nella classificazione dopo l'addestramento ma per motivi diversi.
- Nell'overfitting ci sono troppi parametri nel modello e un'elevata variabilità della classificazione. Il modello è troppo complesso e sensibile ai dati di training ( high variance ).
- Nell'underfitting ci sono pochi parametri nel modello e un'elevata discrepanza nella classificazione ( high bias ). Il processo di apprendimento è troppo semplice.
In entrambi i casi, il modello raggiunge buoni risultati sui dati di addestramento ma scarse performance sui dati di test.
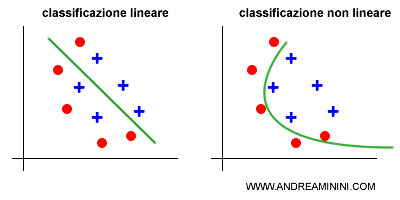
In genere, i problemi di undefitting e overfitting si presentano sui modelli di classificazione lineare.
Nota. Nei casi della classificazione lineare per risolvere il problema dell'underfitting e dell'overfitting basta costruire un confine di classificazione non lineare e/o ricorrere alla regolarizzazione dei dati.
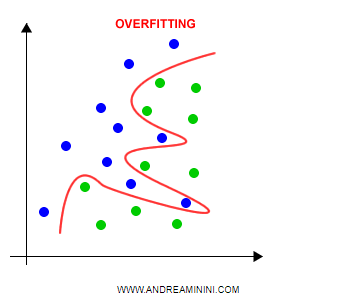
Cos'è l'overfitting
L'overfitting è un problema che si presenta quando la classificazione si basa su troppi parametri.
In questi casi, la varianza della classificazione diventa elevata, perché il modello è troppo sensibile ai dati addestramento.
Come capire se si tratta di overfitting
Se ripeto più volte l'addestramento con dataset di training diversi, il modello di classificazione cambia radicalmente la sua risposta (classificazione) su una stessa istanza.
Questa eccessiva variabilità nella classificazione è un chiaro segnale che l'apprendimento è eccessivamente dipendente dalla casualità nei dati di addestramento.
Per risolvere il problema dell'overfitting devo rivedere i parametri di addestramento.
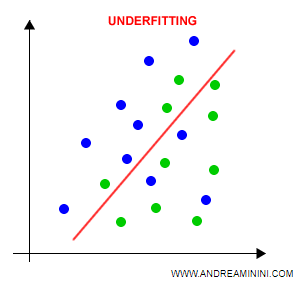
Cos'è l'underfitting
L'underfitting è un problema di apprendimento che si verifica quando la classificazione si basa su pochi parametri.
La classificazione soffre di un'eccessiva discrepanza ( high bias ). E' troppo semplice.
Esempio. Se ripeto l'addestramento su dataset diversi, permane comunque un'elevata discrepanza tra la classificazione del modello e le risposte corrette.
In questo caso il problema non dipende dalla casualità dei dati di training ma dall'eccessiva semplificazione del modello di apprendimento.
Per risolvere il problema dell'underfitting devo ricostruire il modello di classificazione usando più informazioni.
Come capire se è overfitting o underfitting
Per capire se un modello ha problemi di underfitting o overfitting, suddivido il dataset in training set e test set.
Creo il modello sui dati di training.
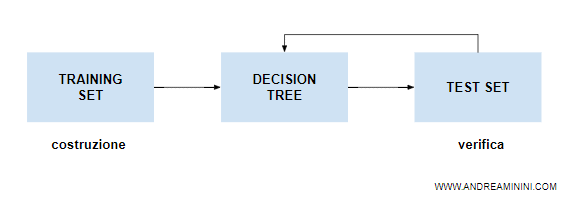
Poi estrapolo le predizioni e verifico l'accuratezza dei risultati sia sui dati di test (test set) che sui dati di addestramento (training set).
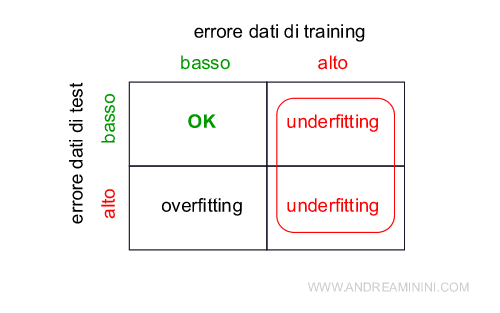
- Se l'errore sui dati di training è elevato, c'è sicuramente un problema di underfitting. Il modello ha generalizzato troppo.
- Se l'errore sui dati di training è accettabile ma l'errore sui dati di test è elevato, c'è un problema di overfitting. Il modello non ha generalizzato abbastanza.
E così via.




