La classificazione supervisionata
Nel machine learning la classificazione ( classification ) è una categoria di apprendimento con supervisione.
Come funziona la classificazione
L'algoritmo viene istruito dal supervisore a riconoscere le categorie tramite una serie di esempi pratici ( dataset training ).
In ogni esempio sono forniti alla macchina:
- le variabili descrittive dell'ambiente (x)
- un'etichetta per indicare il risultato desiderato (y) ossia la classe di appartenenza dell'esempio.
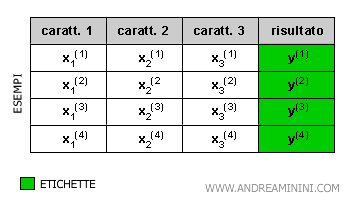
Il sistema elabora gli esempi alla ricerca di una regola generale di classificazione detta modello.
Una volta costruito il modello, la macchina lo utilizza per classificare le nuove istanze, sulla base delle osservazioni compiute sull'insieme di training.
Importante. Non è il supervisore a scrivere le regole del modello. E' la macchina a trovare le regole e a creare il modello predittivo sulla base degli esempi forniti dal supervisore.
Un esempio pratico
Per costruire un filtro antispam istruisco la macchina a riconoscere le email spam.
Creo un insieme di training composto da N esempi ( email ).
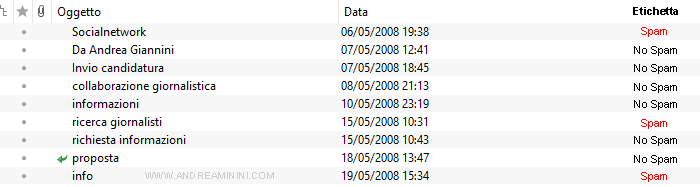
Per ciascun esempio dell'insieme indico due caratteristiche ( features ) della email.
- Peso della email in KB (x1)
- Lunghezza del titolo (x2)
Nota. In questo caso ho volutamente creato un dataset training molto semplice, per spiegare il funzionamento della classificazione automatica. In realtà, le caratteristiche (x) da considerare sono molte di più. Al momento è importante soprattutto sottolineare che nell'apprendimento supervisionato è il supervisore a scegliere le caratteristiche da analizzare. Non è la macchina a sceglierle.
Poi assegno a ogni esempio un'etichetta (y) per classificarlo:
- spam
- no spam
Nota. Questo esempio è una semplice classificazione binaria a due valori ( spam , no spam ). In altri esempi più complessi potrei anche usare una classificazione multiclasse a più valori ( es. riconoscimento dei caratteri e dei numeri in un sistema OCR ). Il funzionamento è sempre lo stesso.
Essendoci soltanto due caratteristiche (x1,x2) e un'etichetta (y), posso rappresentare l'insieme dei dati su un piano cartesiano.
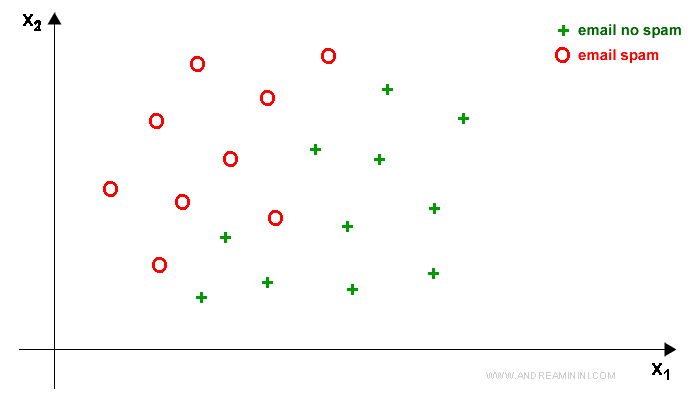
Osservando la rappresentazione grafica dei dati è subito evidente che ci sia una regola a distinguere le email spam e no spam.
Tuttavia non è una regola lineare e non è facile trovarla.
Come posso trovare questa regola?
Potrei scriverla io ma ci vorrebbe molto tempo e potrei commettere degli errori durante la programmazione.
Quindi, mi affido al machine learning lasciando questo compito alla macchina.
La macchina analizza gli esempi nel dataset training e calcola automaticamente un modello predittivo tramite gli algoritmi di apprendimento automatico.

Una volta calcolato, posso usare il modello predittivo per analizzare le nuove email in entrata.
Ogni email in entrata viene classificata nelle classi spam e no spam.
Le email spam sono riconosciute, separate dalle altre e cestinate automaticamente.
Nota. Per creare questo semplice filtro antispam, io non ho dovuto scrivere le regole del filtraggio. E' stato l'algoritmo di machine learning a trovarle e a scriverle, analizzando gli esempi che gli ho fornito.
Per ulteriori approfondimenti
Per un approfondimento consiglio la lettura dei miei appunti sull'Iris Model.
Si tratta di un esempio pratico di classificazione supervisionata, sviluppato con TensorFlow e il linguaggio python.
Il meccanismo di funzionamento è lo stesso.




