La riduzione della dimensionalità dei dati
La riduzione della dimensionalità ( dimensionality reduction ) è una tecnica di mapping dei dati. E' una delle operazioni di pre-elaborazione del dataset nell'apprendimento automatico non supervisionato.
A cosa serve? Mi è utile nel machine learning per eliminare dal dataset le informazioni ridondanti ( correlate ), meno o poco rilevanti per il problema da risolvere. E' senza dubbio più semplice e meno dispendioso addestrare un algoritmo con uno spazio dati di dimensione inferiore. Quindi è una soluzione al problema della curse of dimensionality.
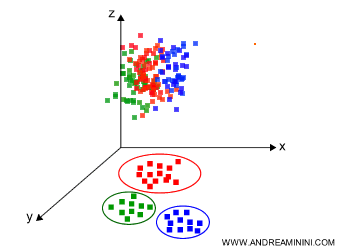
La riduzione dei dati è usata anche per rappresentare i dati in una dimensione inferiore e più interpretabile. Ad esempio, per visualizzare un diagramma 3D in 2D.
Cos'è la curse of dimensionalitity
La curse of dimensionality è un problema della dispersione dei pattern in un grande volume di dati.
Nel machine learning si lavora con una grande mole di dati ( big data ).
A causa dell'elevata dimensionalità, i pattern sono dispersi nel dataset come in un oceano di rumore e dati insignificanti.
In queste circostanze diventa complesso trovare uno schema. L'algoritmo impiega più tempo (complessità temporale) e più memoria (complessità spaziale).
La riduzione della dimensionalità riduce il volume dei dati in cui cercare, senza perdere le informazioni più rilevanti.
Nota. Nel migliore dei casi la riduzione della dimensione non elimina le informazioni rilevanti. In altri casi, invece, il data scientist può decidere di sacrificare alcune informazioni poco rilevanti a vantaggio di quelle più rilevanti.
Come funziona un algoritmo di riduzione della dimensionalità
Ridurre la dimensionalità dei dati non vuol dire soltanto eliminare alcune dimensioni (rumore) ma soprattutto combinare tra loro le informazioni ridondanti e correlate.
Gli obiettivi dell'algoritmo sono i seguenti:
- Eliminare il rumore dei dati
- Combinare le informazioni correlate
Un dataset viene di una dimensione iniziale Rn viene ridotto a uno spazio di dimensione inferiore Rk dove k<n.
I dati sono compressi in un sottospazio dimensionale più compatto.
Per ottenere questo risultato posso seguire diverse tecniche.
Le tecniche di riduzione della dimensionalità dei dati
Le principali tecniche di riduzione della dimensionalità dei dati sono le seguenti:
- Principal Component Analysis (PCA)
La tecnica consiste in un mapping lineare dei dati non supervisionato. E' anche detta tecnica KL (Karhunen Loeve). L'obiettivo della tecnica è individuare le dimensioni che rappresentano meglio i pattern. - Linear Discriminant Anaylis (LDA)
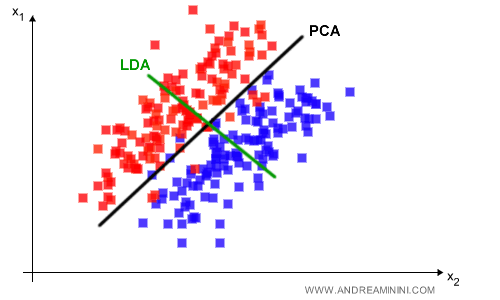
La tecnica LDA è un mapping lineare dei dati supervisionato. L'obiettivo della tecnica LDA è individuare le dimensioni che discriminano meglio i pattern.Differenza tra PCA e LDA. In questo esempio riduco la dimensione da R2 a R1 usando le due tecniche LDA e PCA. Entrambe le tecniche lavorano su un mapping lineare ma individuano un iperpiano (segmento) completamente diverso. Pertanto, sono soluzioni alternative e complementari con pro e contro. La tecnica PCA conserva l'informazione mentre la tecnica LDA distingue meglio le due classi.
- t-distributed Stochastic Neighbor Embedding (t-SNE)
E' una tecnica non lineare e non supervisionata. E' usata per visualizzare i dati multidimensionali in una dimensione bidimensionale o tridimensionale. - Indipendent Component Analysis (IC)
Questa tecnica si basa sulla trasformazione lineare su una base indipendente. - Kernel PCA
E' una tecnica di mapping non supervisionata e non lineare. - Local Linear Embedding (LLE)
E' una trasformazione non lineare basata su mapping locale anziché globale. Considera soltanto le relazioni tra i gruppi di pattern più vicini.
Pro e contro della riduzione dei dati
La riduzione della dimensionalità ha vantaggi e svantaggi.
- Vantaggi. La riduzione della dimensionalità comprime il volume dei dati, riducendo la complessità computazionale dell'algoritmo di apprendimento.
- Svantaggi. La riduzione della dimensionalità può degradare le informazioni e le prestazioni predittive dell'algoritmo di apprendimento.




