Contenuti duplicati
Il contenuto duplicato di un sito web
I contenuti duplicati sono pagine web con un contenuto informativo esattamente o parzialmente uguale a quello di un'altra pagina del sito o di altri siti web. Si tratta di un identico contenuto raggiungibile online tramite indirizzi URL differenti.
- Perché controllare i contenuti duplicati del sito
- L'origine del contenuto duplicato
- Quante volte si può duplicare un testo nel sito web
- Come trovare i contenuti duplicati nel sito
- La gestione delle pubblicazioni del sito web
- La duplicazione da indirizzo URL
- Come risolvere il problema degli indirizzi URL con lo slash
- In conclusione
Perché controllare i contenuti duplicati del sito
I duplicate content sono malvisti dai motori di ricerca e, quando sono molti, possono causare delle penalizzazioni e pregiudicare il ranking di un intero sito web. Il sito perde la sua affidabilità come fonte informativa del search engine.
In alcuni casi, i siti web con molti documenti duplicati possono anche essere classificati come spam engine e scomparire dalle SERPs .
Per questa ragione è una buona pratica verificare i vecchi contenuti, facendo attenzione che non siano presenti delle copie identiche in altre parti del sito web.
L'origine del contenuto duplicato
A volte può dipendere da una cattiva organizzazione delle pubblicazioni, altre volte da problemi tecnici. Spesso non ci si rende nemmeno conto di avere un problema di questo tipo sul sito web. La duplicazione dei contenuti riguarda tutto il sito web e non è facile da individuare per un occhio umano, ma è immediatamente evidente al crawler di un search engine.
Quante volte si può duplicare un testo nel sito web
Non esiste una regola generale valida per tutti i siti. In genere, la presenza dei contenuti duplicati è normalmente accettata dal search engine Google quando si tratta di siti e-commerce e di siti web ad elevato trust ( autorevolezza website ).

E' invece meno indulgente quando si tratta di blog, web magazine, news o siti aziendali a medio-basso trust. In questi casi, il search engine può anche arrivare a una penalizzazione della pagina o del sito.
Perché il search engine penalizza i contenuti duplicati. La presenza del contenuto duplicato è una caratteristica delle spam page. Per questa ragione, quando un search engine individua i contenuti duplicati su un sito web può decidere di penalizzarlo. Soprattutto se il trust e l'autorevolezza del web site non è alta.
La strategia migliore è evitare la pubblicazione dei contenuti duplicati sul sito e seguire una politica di copywriting e di revisione/organizzazione delle informazioni basata sulla differenziazione dei testi.
Come trovare i contenuti duplicati nel sito
Esistono diversi servizi online e software che consentono di analizzare i contenuti del sito e individuare le duplicazioni di frasi e proposizioni al loro interno.
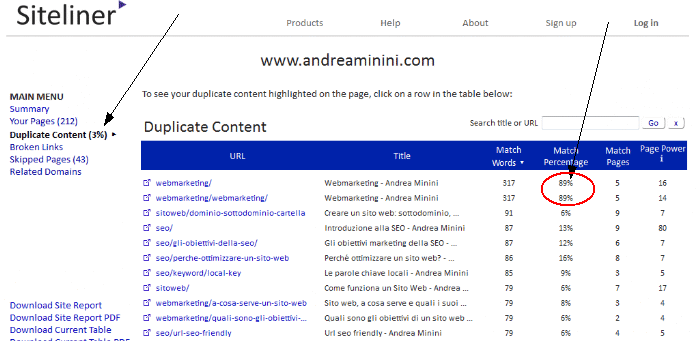
Esempio. La piattaforma Sitelinker analizza il sito come il crawler di un search engine e restituisce in tempo reale un elenco dei risultati con la percentuale dei risultati duplicati e gli indirizzi URL in cui si trovano i risultati duplicati. Tramite questo servizio ho trovato un problema di duplicazione automatica dei contenuti nel mio sito che altrimenti mi sarebbe passato inosservato.
La gestione delle pubblicazioni del sito web
Pubblicare uno stesso articolo in più indirizzi del sito web è inutile. È sufficiente pubblicare il documento in un indirizzo e richiamarlo tramite un collegamento ipertestuale da tutte le altre pagine.
Spesso i contenuti duplicati sono causati anche dalle pagine dei tags e delle categorie. Ad esempio, su Wordpress gli stessi contenuti informativi di una pagina possono essere visualizzati contemporaneamente su molteplici pagine dei tag o delle categorie.
Un'altra cattiva abitudine è quella di copiare i contenuti di altri siti web ( es. articoli di legge, decreti, fonti, ecc. ) al solo scopo di non far uscire il lettore dal sito web. È una pratica controproducente poiché aggiunge dei contenuti duplicati all'interno del sito.
La duplicazione da indirizzo URL
Non sempre però i contenuti duplicati dipendono da una cattiva organizzazione contenutistiche, a volte può capitare che la causa sia un fattore tecnico. Facciamo qualche esempio pratico.
L'indirizzo URL con lo slash finale
Molti siti web dinamici non utilizzano alcuna estensione ( .htm, .html, .php, ecc. ) per richiamare i propri documenti. È sufficiente digitare il nome della pagina nell'indirizzo e quest'ultima viene visualizzata sullo schermo dell'utente.
www.andreaminini.com/seo
Fin qui nessun problema. Proviamo ad aggiungere uno slash alla fine dell'indirizzo, come fosse una directory, e vediamo cosa succede. Dal browser parte una chiamata verso il server, che non trova alcuna directory con quel nome e, quindi, richiama il documento con lo stesso nome.
www.andreaminini.com/seo/
In entrambi i modi, con o senza barra finale, il browser visualizza la medesima pagina. Agli occhi di un motore di ricerca i due indirizzi URL sono distinti. Il primo riguarda un file mentre il secondo una directory.
Potrebbe accadere che il motore di ricerca decida di indicizzare entrambi gli indirizzi. E questo causa un grande problema, perché tutte le pagine del sito web si troverebbero ad avere una pagina gemella, esattamente uguale ma su un indirizzo diverso, con gli stessi contenuti duplicati.
Indirizzo Url con o senza www ( il doppio dominio )
Un altro problema tecnico molto diffuso riguarda il dominio di primo livello dell'indirizzo. Generalmente i siti web sono visualizzati con nomi di dominio che comprendono nell'indirizzo anche il famoso "www" come dominio di primo livello.
www.andreaminini.com
Lo stesso nome di dominio potrebbe essere visualizzato con o senza WWW. Ad esempio, possiamo scrivere "www.andreaminini.com" oppure "andreaminini.com", in entrambi i casi il browser ci indirizza verso lo stesso indirizzo.
andreaminini.com
Quando i contenuti di un sito sono visualizzabili in entrambi i modi, si presentano due siti web duplicati. Il motore di ricerca potrebbe considerarli come sottodomini differenti e indicizzarli entrambi, causando il problema della duplicazione dei contenuti per tutte le pagine del sito web.
La Homepage raggiungibile da diversi indirizzi
La duplicazione dei contenuti può verificarsi nella homepage, quando un la pagina di accoglienza del sito è raggiungibile sia con il nome del dominio che con il nome del file del documento index.
www.andreaminini.com
www.andreaminini.com/index.htm
E' consigliabile fissare anche quest'ultimo errore. Alcuni search engine potrebbero considerare i due indirizzi come due pagine differenti con il medesimo contenuto.
Come risolvere il problema degli indirizzi URL con lo slash
Non copiare le fonti, meglio linkare
Quando dobbiamo citare una fonte, è inutile ripubblicare per intero il suo contenuto all'interno del sito. È preferibile inserire una breve sintesi e un collegamento ipertestuale ( link ) verso la fonte originale.
Se la fonte è esterna perdiamo il lettore, qualora decida di seguire il link, ma ne guadagniamo in termini di buona organizzazione contenutistica interna.
Eliminare le pagine duplicate
Per evitare qualsiasi penalizzazione dal search engine, è opportuno eliminare tutte le visualizzazioni alternative dei documenti. È quindi preferibile limitare la visualizzazione delle pagine senza lo slash, facendo restituire un errore 404 agli stessi indirizzi con la barra finale. O viceversa.
Alla fine del lavoro di rimozione ed eliminazione delle pagine copiate, l'importante è che ci sia soltanto un indirizzo URL per ciascun documento informativo del sito.
Il reindirizzamento delle pagine duplicate verso la pagina originale
Per evitare di perdere l'eventuale posizionamento sulle SERP degli indirizzi con contenuti duplicati, è anche possibile sostituire l'errore 404 con un redirect 301 ( trasferimento permanente ) verso l'indirizzo corretto della pagina.
La deindicizzazione delle pagine copiate ( noindex )
Se non vogliamo rinunciare alle pagine duplicate possiamo ricorrere alla deindicizzazione dei contenuti duplicati, inserendo in tutte le pagine copiate il meta-tag robots noindex.
In questo modo gli spider del search engine le rimuovono dagli indici. Per maggiore sicurezza è preferibile inserire nel meta-tag robots anche il parametro nofollow, in questo modo evitiamo di creare una sovra numero di link verso le stesse pagine.
La canonizzazione degli indirizzi URL
Qualora non fosse possibile l'eliminazione degli indirizzi duplicati o introdurre delle regole di redirect, si può provare a utilizzare la canonizzazione tramite il tag rel=canonical.
Il tag rel=canonical ci consente di indicare l'indirizzo originale del contenuto in tutte le pagine duplicate. Sia nella pagina originale che nelle copie.
Questo accorgimento è conosciuto come canonizzazione delle URL e ci permette di evitare le penalizzazioni del motore di ricerca, poiché siamo noi stessi a indicargli che le pagine duplicate sono copie di un unico documento originale a cui far riferimento.
Ad esempio, il rel=canonical si utilizza nei siti e-commerce che permettono la visualizzazione degli stessi prodotti in più pagine, secondo un criterio o un ordine differente ( es. prezzo, disponibilità, ecc. ). Il rel=canonical inserisce un riferimento in tutti gli ordinamenti possibili verso la pagina contenente l'elenco principale.
In conclusione
I contenuti duplicati non sono mai un buon indicatore di qualità del sito, sia dal punto di vista dell'utente che da quello di un motore di ricerca. Duplicare un contenuto vuol dire non avere la forza per produrre un documento originale. Una buona ottimizzazione on-site è incompatibile con i duplicate contents. Vanno gestiti e, come abbiamo visto, le possibilità a nostra disposizione sono veramente molte.




