Apprendimento per regressione
Nel machine learning la regressione lineare è una tecnica di classificazione degli esempi di un dataset ( insieme di training ) per consentire alla macchina di apprendere automaticamente un modello decisionale.
Come funziona
L'algoritmo assegna delle etichette ( categorie ) alle istanze utilizzando una funzione continua.
Ogni riga del dataset è un esempio composto da:
- Gli attributi (X). Sono le variabili predittive che descrivono una categoria.
- Il risultato (Y). E' la variabile target che indica alla macchina il risultato corretto se l'istanza appartenesse all'etichetta Z. E' il dato che istruisce la macchina a decidere in modo giusto.
L'algoritmo di machine learning deve trovare una relazione tra le variabili X e Y tramite la regressione.
y=(x)
Il risultato finale è una linea retta che minimizza la distanza tra gli N esempi dell'insieme di training che appartengono alla stessa categoria.
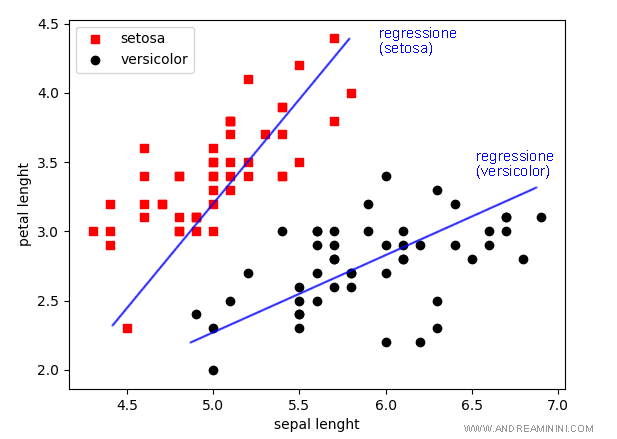
Una volta trovata, la funzione di classificazione può essere utilizzata per valutare istanze diverse dall'insieme di training.
Se le coordinate (x,y) di un'istanza si avvicinano alla funzione di regressione f(x), l'istanza viene classificata con l'etichetta Z.
E così via.




