Come fare machine learning con un classificatore ad albero decisionale su Python
Il classificatore ad albero decisionale è un algoritmo di machine learning supervisionato. In questi appunti spiego come utilizzarlo su Python usando la libreria scikit-learn.
Per prima cosa importo i moduli che mi serviranno per l'esecuzione dello script.
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
from numpy import random
Fisso il random seed per avere risultati non influenzati dalla casualità.
In questo modo posso confrontare tra loro i vari tentativi di addestramento.
random.seed(0)
Per testare l'algoritmo ad albero decisionale utilizzo il dataset Iris.
E' disponibile tra i dataset didattici di scikit-learn.
dataset = load_iris()
Il dataset Iris è composto da 130 esempi.
Ogni esempio misura quattro caratteristiche (lunghezza/larghezza petalo e sepalo) dei fiori Setosa, Virginica, Versicolor.

Estrapolo dal dataset la matrice X con le caratteristiche (features) degli esempi e le classificazioni corrette y (label).
X=dataset['data']
y=dataset['target']
Per addestrare il modello suddivido il dataset in train e test.
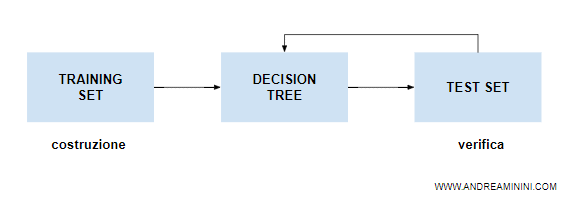
Utilizzo come test set il 30% del dataset.
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.3)
Assegno la classe DecisionTreeClassifier() all'istanza model.
model = DecisionTreeClassifier()
Avvio il processo di addestramento tramite il metodo fit() usando il dataset di train ( training set ).
model.fit(X_train, y_train)
Al termine dell'addestramento verifico l'affidabilità del modello tramite il metodo predict().
Uso il modello per predire la classificazione degli esempi di test (X_test), quelli non usati per addestrare il modello.
Salvo i risultati nel vettore p_test.
p_test = model.predict(X_test)
Infine confronto i risultati con la classificazione corretta degli esempi di test (y_test).
errori = accuracy_score(y_test, p_test)
print(errori)
Il risultato finale è
0.9777777777777777
Il modello classifica il 97,7% degli esempi di test.
E' un buon risultato. Tuttavia... questo è solo un dataset didattico.
E così via.




