Come fare machine learning con scikit-learn di Python
In questi appunti uso il modulo sklearn della libreria scikit-learn di Python per sviluppare ed eseguire un semplice algoritmo di apprendimento automatico.
Nota. Questo tutorial richiede la presenza della libreria scikit-learn nell'interprete Python. Se non è presente, occorre prima installare la libreria scikit-learn.
Un esempio pratico
Questo codice è uno dei primi esempi pratici di machine learning con il linguaggio python.
Lo script elabora un modello previsionale tramite la libreria scikit-learn.
- import numpy as np
- from sklearn import datasets
- from sklearn.linear_model import Perceptron
- from sklearn.metrics import accuracy_score
- from sklearn.model_selection import train_test_split
- # preparazione dei dati
- iris = datasets.load_iris()
- X = iris.data[:, [2, 3]]
- y = iris.target
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
- # addestramento del modello
- ppn = Perceptron(max_iter=40, tol=0.001, eta0=0.01, random_state=0)
- ppn.fit(X_train, y_train)
- # verifica accuratezza del modello
- y_pred = ppn.predict(X_test)
- print(accuracy_score(y_test, y_pred))
Nei prossimi paragrafi fornisco una spiegazione per ogni singolo passaggio.
L'algoritmo è suddiviso in tre fasi:
- preparazione dei dati
- creazione del modello previsionale ( addestramento )
- verifica del modello
La preparazione dei dati
Per cominciare utilizzo il dataset Iris.
Il modulo Sklearn ha il vantaggio di incorporare diversi dataset di default. Pertanto, non devo caricare il file dall'esterno.
>>> from sklearn import datasets
>>> iris = datasets.load_iris()
Nella prima riga carico la funzionalità datasets di sklearn.
Poi, nella seconda riga, assegno alla variabile iris il dataset con il metodo load_iris().
A questo punto nella variabile iris c'è tutto il dataset iris.
Cos'è il dataset iris? E' un insieme di addestramento composto da 130 esempi che misurano la lunghezza e la larghezza del petalo e del sepalo delle classi di fiori Iris-Setosa, Iris-Versicolor, Iris-Virginica. Analizzando il dataset la macchina impara a classificare correttamente i tre fiori, ossia crea da sé un modello previsionale senza che nessuno l'abbia programmata appositamente per farlo.

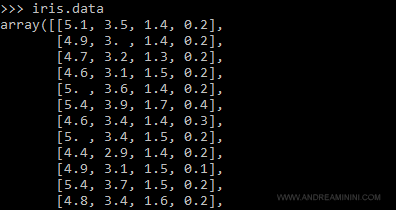
Gli esempi del training set si trovano con il metodo data.
Ogni riga contiene un esempio e ogni esempio è composto da 4 attributi che misurano la lunghezza e la larghezza del petalo e del sepalo in centimetri.
Le risposte corrette degli esempi, invece, sono memorizzate sotto il metodo target
Il vettore è composto da 130 etichette zero, uno e due:
- 0 = Iris-Setosa
- 1 = Iris-Versicolor
- 2 = Iris-Virginica
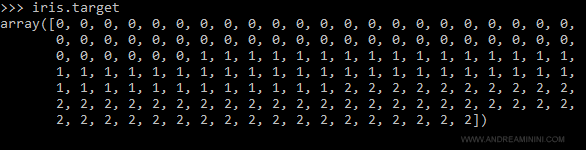
Nota. Gli esempi sono registrati sotto forma di vettori e matrici. E' quindi necessario trattarli con le funzioni di python predisposte per elaborare le matrici e i vettori ( es. numpy ).
Ora carico in memoria la libreria numpy di python per poter eseguire funzioni di calcolo vettoriale e matriciale.
>>> import numpy as np
Nota. Se la libreria numpy non è stata installata, l'interprete python va in errore. In questi casi è sufficiente installare numpy sul PC. Poi chiudere e riaprire python.
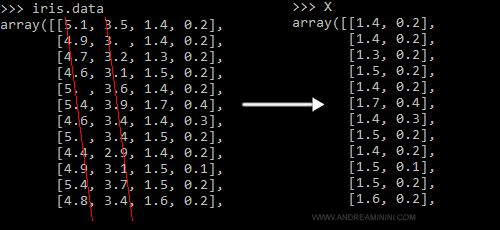
Per semplificità assegno gli esempi ( iris.data ) alla variabile X prendendo soltanto due misure, la colonna 2 e 3.
Le colonne 0 e 1 (le prime due) sono invece eliminate.
>>> X = iris.data[:, [2, 3]]
In questo modo riduco la matrice di 130 esempi da 4 attributi a 2 attributi.
Poi assegno le etichette ( iris.target ) alla variabile y.
>>> y = iris.target
Ora devo dividere il dataset in training set ( insieme di addestramento ) e test set ( insieme di test ).
Per farlo utilizzo la funzione train_test_split
>>> from sklearn.model_selection import train_test_split
>>> X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
La funzione train_test_split ha quattro parametri in input
- Data. Il dataset degli esempi (X)
- Target. Il dataset delle etichette (y)
- Testize. Indica la percentuale di esempi da usare per l'insieme di test. In questo caso è 0.3 ossia il 30%.
- Random_state. E' l'indicatore di randomizzazione che per il momento lascio a zero.
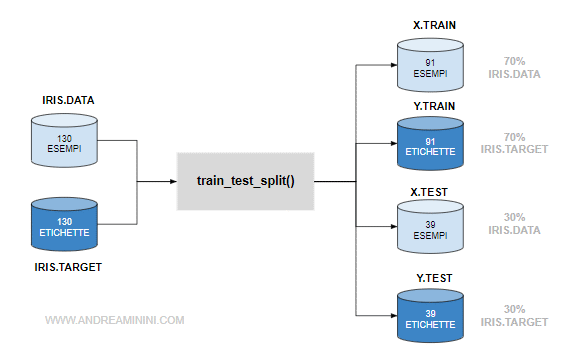
Restituisce in output quattro insieme di dati:
- L'insieme di addestramento (X_train)
- L'insieme di test (X_test)
- Le etichette dell'insieme di addestramento (y_train)
- Le etichette dell'insieme di test (y_test)
Nota. In pratica, la funzione ha diviso l'insieme degli esempi in due insiemi distinti, uno destinato all'addestramento (X.train) e l'altro destinato alla verifica finale (X.test). Poi, ha fatto lo stesso con l'insieme delle etichette (risultati).
I dati sono pronti per essere elaborati.
La creazione del modello previsionale
Per creare un modello previsionale devo scegliere un algoritmo di apprendimento.
Opto per il vecchio perceptron, uno dei primi algoritmi di classificazione della storia.
Fortunatamente la libreria scikit-learn include diversi algoritmi di learning, tra cui c'è anche il perceptron.
Lo carico in memoria.
from sklearn.linear_model import Perceptron
Poi definisco gli iperparametri del processo di learning ( max_iter , tol, eta ).
Dove n_iter indica il numero di cicli ( epoch ) da elaborare mentre il parametro eta0 è il tasso di apprendimento del perceptron.
ppn = Perceptron(max_iter=40, tol=0.001, eta0=0.01, random_state=0)
L'attributo max_iter fissa il numero massimo di iterazioni.
L'attributo tol indica la tolleranza sufficiente per l'uscita dal ciclo.
A questo punto eseguo il process learning tramite il metodo fit per cominciare l'addestramento.
ppn.fit(X_train, y_train)
L'algoritmo legge il training set e crea il modello previsionale.
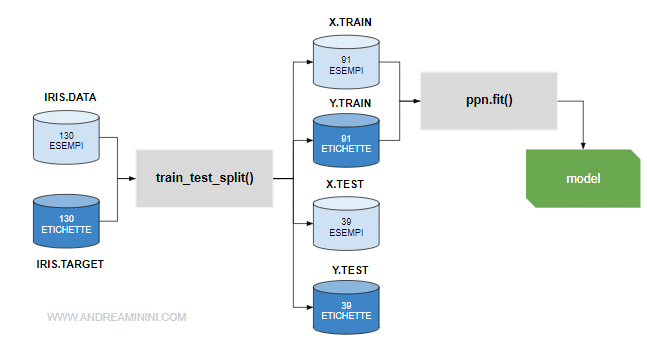
Non resta altro da fare che verificare l'accuratezza del modello, se riesce a formulare una previsione corretta sugli esempi del test set.
La verifica del modello previsionale
Per verificare il modello previsionale, lo applico sugli esempi dell'insieme di test ( X.test ).
Nella libreria scikit-learn c'è un'apposita metodo per verificare il modello. Si tratta del metodo predict().
y_pred = ppn.predict(X_test)
Le risposte del modello sono registrate nella variabile y_pred.
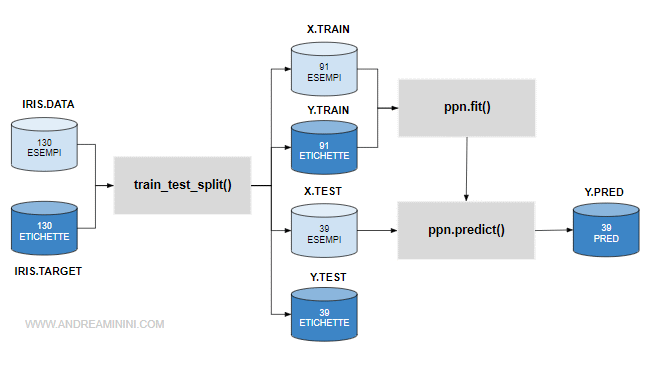
A questo punto devo controllare se le risposte del modello ( y_pred ) coincidono con le etichette corrette ( Y.test ).
Per fare questo utilizzo la funzione accuracy_score di scikit-learn.
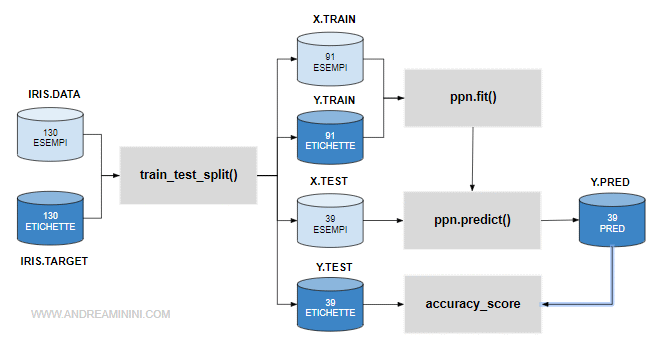
La carico in memoria
from sklearn.metrics import accuracy_score
Poi confronto i dati y_test e y_pred tra loro.
accuracy_score(y_test, y_pred)
La funzione restituisce in output il seguente valore:
0.5777777777777777
Vuol dire che il modello ha un'accuratezza del 57%.
E' decisamente migliorabile ma è soltanto il primo passo utile per cominciare a fare machine learning con il linguaggio python.
Esempio. A parità di altri fattori posso portare l'accuratezza del modello previsionale oltre il 97% tramite la standardizzazione del training set ( vedi esempio ).
Per verificare più nel dettaglio la risposta, itero la predizione per ogni singolo campione del test aggiungendo in coda al programma una for.
for xt,yt in zip(X_test, y_test):
yp=ppn.predict([xt])
print(xt,yt,yp)
In questo modo posso vedere i dati in input (prime due colonne) seguiti dalla risposta corretta (terza colonna) e dal risultato della predizione (quarta colonna).
| X_test | Y_test | Y_pred |
|---|---|---|
| [5.1 2.4] | 2 | [2] |
| [4. 1.] | 1 | [0] |
| [1.4 0.2] | 0 | [0] |
| [6.3 1.8] | 2 | [2] |
| [1.5 0.2] | 0 | [0] |
| [6. 2.5] | 2 | [2] |
| [1.3 0.3] | 0 | [0] |
| [4.7 1.5] | 1 | [2] |
| [4.8 1.4] | 1 | [2] |
| [4. 1.3] | 1 | [0] |
| [5.6 1.4] | 2 | [2] |
| [4.5 1.5] | 1 | [2] |
| [4.7 1.2] | 1 | [0] |
| [4.6 1.5] | 1 | [2] |
| [4.7 1.4] | 1 | [2] |
| [1.4 0.1] | 0 | [0] |
| [4.5 1.5] | 1 | [2] |
| [4.4 1.2] | 1 | [0] |
| [1.4 0.3] | 0 | [0] |
| [1.3 0.4] | 0 | [0] |
| [4.9 2. ] | 2 | [2] |
| [4.5 1.5] | 1 | [2] |
| [1.9 0.2] | 0 | [0] |
| [1.4 0.2] | 0 | [0] |
| [4.8 1.8] | 2 | [2] |
| [1. 0.2] | 0 | [0] |
| [1.9 0.4] | 0 | [0] |
| [4.3 1.3] | 1 | [0] |
| [3.3 1. ] | 1 | [0] |
| [1.6 0.4] | 0 | [0] |
| [5.5 1.8] | 2 | [2] |
| [4.5 1.5] | 1 | [2] |
| [1.5 0.2] | 0 | [0] |
| [4.9 1.8] | 2 | [2] |
| [5.6 2.2] | 2 | [2] |
| [3.9 1.4] | 1 | [2] |
| [1.7 0.3] | 0 | [0] |
| [5.1 1.6] | 1 | [2] |
| [4.2 1.5] | 1 | [2] |
| [4. 1.2] | 1 | [0] |
| [5.5 2.1] | 2 | [2] |
| [1.3 0.2] | 0 | [0] |
| [5.1 2.3] | 2 | [2] |
| [1.6 0.6] | 0 | [0] |
| [1.5 0.2] | 0 | [0] |
Gli errori sono decisamente troppi.
Per avere una visione d'insieme visualizzo graficamente le risposte aggiungendo questo codice alla fine del programma
from mlxtend.plotting import plot_decision_regions
import matplotlib.pyplot as plt
plt.title('Perceptron con Iris')
plot_decision_regions(X_test, y_test, clf=ppn, legend=2)
plt.show()
La funzione plot_decision_regions visualizza i dati del campione nelle aree di classificazione del modello.
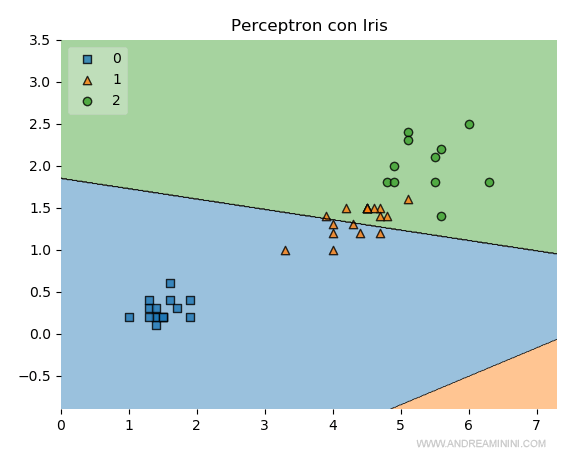
Dal diagramma è subito evidente che il modello non riesce a prevedere la classe 1 (Versicolor), mentre prevede correttamente le altre due (Setosa e Virginica).
In effetti, riguardando la lista delle risposte del modello, tutti gli errori sono relativi a campioni della classe y_test=1.
Come migliorare l'accuratezza del modello?
Ci sono diversi modi per migliorare le performance previsionali del modello.
Ad esempio, aggiungendo la standardizzazione dei dati di training con la pre-elaborazione prima dell'addestramento del modello (ossia prima della riga 11 nel programma iniziale) posso aumentare l'accuratezza al 66%.
#standardizzazione
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
sc.fit(X_train)
X_train = sc.transform(X_train)
X_test = sc.transform(X_test)
Dopo questa modifica il diagramma è leggermente migliorato.
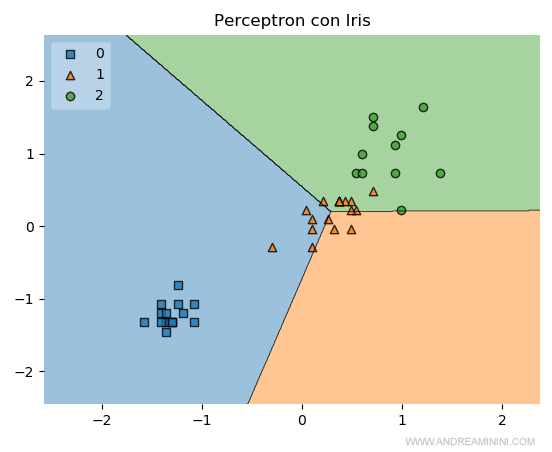
In ogni caso l'accuratezza è ancora troppo bassa.
Per migliorarla ulteriormente posso modificare i parametri dell'addestramento.
Ad esempio, aumento il parametro del tasso di addestramento (eta) da 0,01 a 0,1
ppn = Perceptron(max_iter=40, tol=0.001, eta0=0.01, eta0=0.1, random_state=0)
In questo modo il modello raggiunge un'accuratezza del 88%.
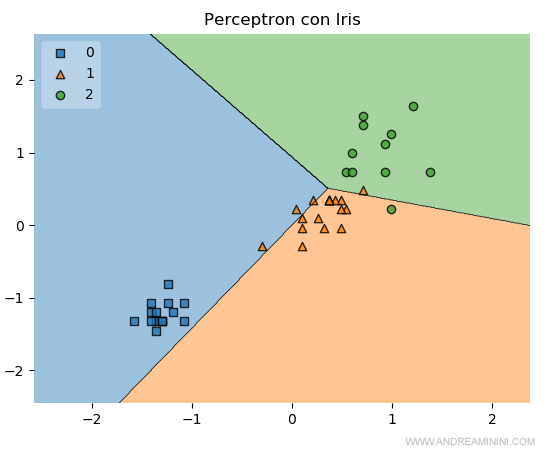
E via dicendo.
La libreria scikit-learn ha molti altri strumenti utili per perfezionare l'accuratezza.
Nota. Il diagramma delle regioni mostra anche una limitazione evidente del Perceptron. L'algoritmo classifica i dati in modo lineare. E' uno dei limiti dell'algoritmo Perceptron perché è raro che i dati siano perfettamente separabili in classi in modo lineare. Pertanto, spesso l'algoritmo non converge a una soluzione. Per superare questo limite occorre cambiare algoritmo.
Come usare il modello di classificazione
Una volta ottenuto un modello di classificazione affidabile, posso usarlo per classificare qualsiasi query senza doverlo ricostruire.
Esempio
Digito le caratteristiche dell query nella funzione ppn.predict().
Poi do invio.
ppn.predict([[5.8, 1.8, 4.1, 2.4]])
Il sistema consulta il modello statistico e mi restituisce la classificazione più probabile.
In questo caso è la classe 2 ( Iris Virginica ) .
array([2])
E così via




