Come caricare un dataset su scikit-learn
La libreria scikit-learn di python integra diversi dataset didattici. Sono utili per fare esperienza con il machine learning.
Cos'è un dataset
Un dataset è un insieme di training ossia un file contenente degli esempi che consentono di istruire la macchina nelle operazioni di classificazione o di regressione.
Come è composto?
Un dataset è composto da n record (esempi). Ogni record è suddiviso in k campi/colonne che individuano le caratteristiche x ( features ) dell'esempio.
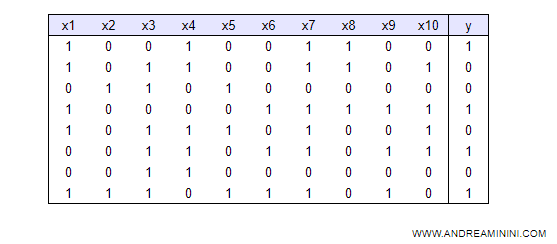
Nei dataset predisposti per il machine learning supervisionato c'è anche un'ulteriore colonna y detta target dove è registrata la risposta corretta.
Come importare un dataset da scikit-learn
Per prima cosa importo in memoria il dataset che mi interessa dal modulo sklearn.datasets.
>>> from sklearn.datasets import load_iris
Poi lo assegno a una variabile di python
>>> X = load_iris()
Nella variabile dataset sono registrati tutti gli esempi.
>>> X
{'data': array([[5.1, 3.5, 1.4, 0.2],
[4.9, 3. , 1.4, 0.2],
[4.7, 3.2, 1.3, 0.2],
[4.6, 3.1, 1.5, 0.2],
[5. , 3.6, 1.4, 0.2],
[5.4, 3.9, 1.7, 0.4],
Per salvare le caratteristiche (features) e le risposte corrette (target) in variabili diverse:
>>> X=dataset['data']
>>> y=dataset['target']
Questa separazione è indispensabile nel ML supervised.
Metodo alternativo
In alternativa posso caricare in memoria tutto il modulo dei dataset.
from sklearn import datasets
Poi richiamare quello che mi interessa
X=datasets.load_iris()
Il risultato finale è lo stesso.
Come dividere il dataset in training e test
Per verificare l'accuratezza di un modello divido il dataset in training set e test set.
- Il training set lo utilizzo per addestrare il modello
- Il test set lo utilizzo per verificare se risponde correttamente
Importo la funzione train_test_split da sklearn.model
from sklearn.model_selection import train_test_split
Poi divido la variabile feature X e target y
X_train, X_test, y_train, y_test = train_test_split(X,y)
La funzione divide le variabili del dataset e le assegna rispettivamente X a X_train e X_test mentre y a y_train e y_train
Se non specifico altri parametri la divisione è al 50%.
Posso comunque modificare la percentuale con il parametro test_size
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.3)
In quest'ultimo esempio il 70% del dataset diventa di training e il restante 30% di test.
Un'altra opzione utile è random_state che mi permette di influire sulla selezione casuale degli esempi
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
Come vedere le caratteristiche del dataset
In genere le informazioni sul dataset sono registrate alla voce 'DESCR'. E' una convenzione abbastanza diffusa.
Una volta caricato il dataset per vedere le informazioni sui campi digito
print(X['DESCR'])
In questo modo ottengo tutte le informazioni che mi servono per cominciare a lavorare con il dataset
Iris plants dataset
--------------------
**Data Set Characteristics:**
:Number of Instances: 150 (50 in each of three classes)
:Number of Attributes: 4 numeric, predictive attributes and the class
:Attribute Information:
- sepal length in cm
- sepal width in cm
Quali sono i dataset di scikit-learn
Ci sono diversi dataset didattici tra cui scegliere.
- load_boston
dataset con i prezzi delle case - load_iris
dataset con le misure di alcuni fiori - load_wine
dataset con le caratteristiche dei vini
E così via




