Come gestire i dati mancanti nel dataset
Uno dei problemi più frequenti nel machine learning è la qualità dei dati. In particolar modo, la presenza di dati mancanti negli esempi di training.
Un dataset è composto da numerosi esempi.
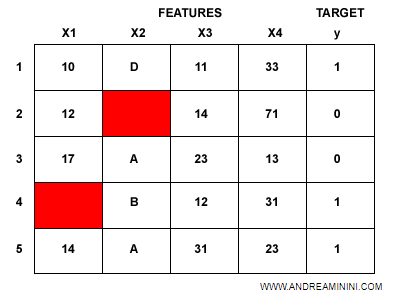
Ogni record (riga) è un esempio di addestramento ed è suddiviso in più campi (colonne).
Le colonne indicano le caratteristiche (feature) prese in considerazione.
Se in un esempio manca il dato di una feature, l'intero processo di addestramento potrebbe risentirne.
Cosa fare per gestire i dati mancanti?
Ci sono due strade possibili:
- Eliminare dal dataset i record incompleti, quelli con dati mancanti in fase di pre-addestramento. Si riduce un po' la dimensione del datase ma, in compenso, si acquista in qualità dei dati. E' la via preferibile.
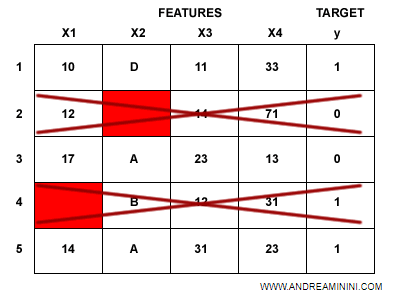
- Sostituire i dati mancanti con altri dati. La sostituzione può essere basata su diverse tecniche. La sostituzione non riduce la dimensione dei dati. In compenso, il dataset diventa meno realistico e la sintesi dei dati rischia di sporcarlo ulteriormente.
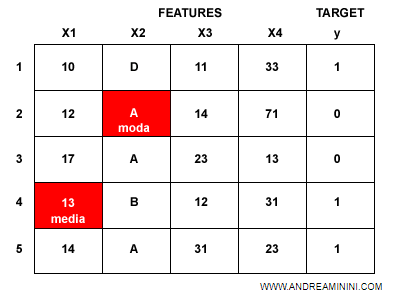
Metodi di imputazione. Esistono diversi metodi di imputazione tra cui scegliere. Ad esempio, posso sostituire un dato numerico mancante con la media della feature oppure, in modo più ragionato, con la media della feature in esempi simili (multivariate imputer).
E così via.




