Lo scaling nel machine learning
Nel machine learning lo scaling (o feature scaling) mi permette di normalizzare il range di variazione delle caratteristiche (feature) di un dataset.
A cosa serve? E' una delle operazioni di pre-processing più utili perché migliora la qualità dei risultati finali. A parità di altre condizioni, lo scaling o scalatura riduce il tempo in cui l'algoritmo di apprendimento converge al risultato finale e migliora l'efficacia del modello statistico.
Quando l'intervallo dei valori è molto variabile, la semplice distanza euclidea tra due due punti può diventare fuorviante.
Un esempio pratico
Se una caratteristica ha un'ampia gamma di valori mentre un'altra caratteristica ne ha una più ristretta, la prima caratteristica governa la distanza tra i punti.
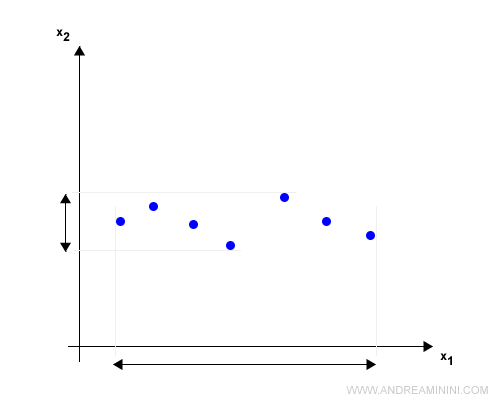
Per evitare questo problema ricorro alla normalizzazione dei dati tramite lo scaling.
Come funziona lo scaling
Esistono diversi metodi di scaling dei dati.
Uno dei più semplici è il ridimensionamento min-max.
L'algoritmo di scaling individua il valore minimo e massimo tra i valori di una caratteristica x.
$$ \begin{cases} \min(x) \\ \max(x) \end{cases} $$
In questo modo riduce il campo di variazione dei valori
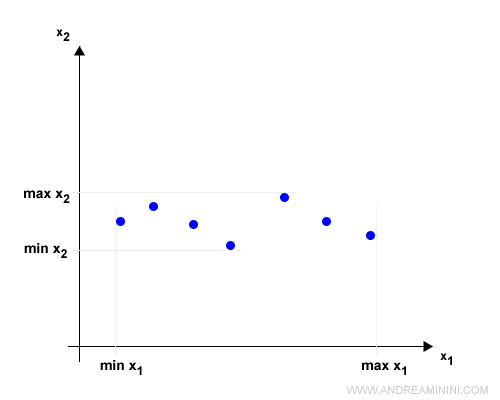
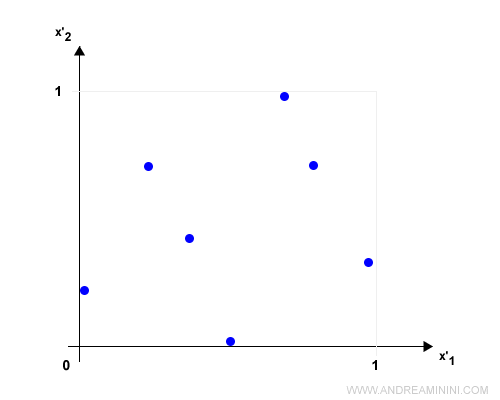
Poi sostituisce ogni valore xi con il valore x'i normalizzato
$$ x'_i = \frac{x_i - min(x)}{max(x)-min(x)} $$
Dove xi è il valore originale mentre x'i è il valore normalizzato.
In questo modo i dati diventano omogenei in una scala da 0 a 1.
E' soltanto un metodo di ridimensionamento. Ce ne sono molti altri.
Ad esempio, la normalizzazione media.
$$ x'_i = \frac{x_i - media(x)}{max(x)-min(x)} $$
Sottovalutare la potenza dello scaling è uno degli errori più diffusi per chi inizia ad approfondire l'apprendimento automatico.
E così via.




