Text corpora
I text corpora sono raccolte di testo, frasi e dati strutturati registrati in forma elettronica.
A cosa servono? Sono database lessicali utilizzati per creare o testare gli strumenti di Natural Language Processing. Sono usati nel riconoscimento vocale, nella traduzione automatica, nel controllo ortografico e grammaticale, nel text mining, nel text analytics, ecc.
Nel machine learning applicato alla linguistica, i text corpora sono usati come insiemi di training e insiemi di test per individuare le regole sintattiche della lingua.
Come costruire un text corpora
Nei text corpora il testo contiene anche metadati che forniscono informazioni precise sulle parole ( es. lemma, radice/steam, funzione grammaticale, ecc. ).
- POS ( Part Of Speech ). Sono i metadati più importanti perché specificano la funzione grammaticale della parola nel testo.
Esempio. Il tag ADJ indica un aggettivo, ADV un avverbio, N un nome, V un verbo, P una preposizione, DET un articolo, ecc.

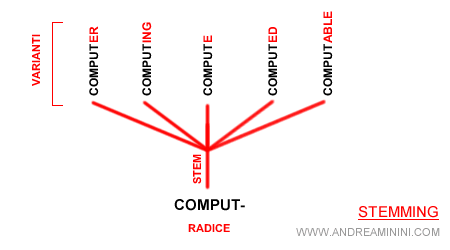
- Word Steam ( radice ). Questo metadato indica la radice di una parola, la parte a cui sono aggiunti i suffissi.
Esempio. La parola "lavoro" è composta dalla radice "lavor-" e dai vari suffissi ("-i", -"o", "-are", ecc. ). Per una spiegazione più ampia rimando alla lettura dell'algoritmo di steamming.
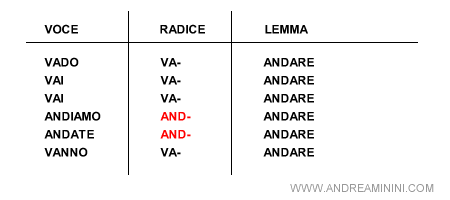
- Word lemmas ( lemmi ). Questo metadato indica il lemma di una parola ossia la forma canonica principale condivisa da più parole.
- Dependency Grammar. I metadati della grammatica delle dipendenze specificano le relazioni tra una parola ( word ) e le altre parole che compongono una frase.

- Constituency grammar. Questi metadati indicano la tipologia e la funzione semantica delle parole o dei gruppi di parole in una frase ( es. luogo, persona, tempo, ecc. ). Esistono varie tipologie di dati strutturati.
Tutte queste informazioni sono usate per analizzare la struttura sintattica e semantica del testo.
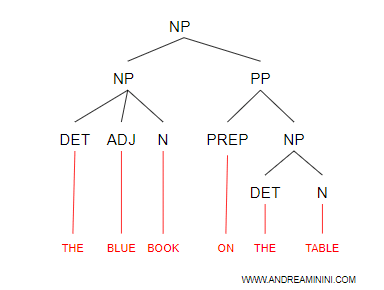
Uno strumento di rappresentazione è l'albero sintattico ( treebanks ).
Elenco di Text Corpora
Ecco una lista di text corpora in lingua inglese
- Key Word in Contest ( KWIC )
- Brown Corpus
- Lancaster-Oslo-Bergen ( LOB ) Corpus
- Collins Corpus
- Child Language Data Exchange System ( CHILDES )
- WordNet
Descrive il dizionario della lingua inglese specificando per ogni parola la definizione, i sinonimi e le relazioni tra le parole. Sono presenti anche molti esempi pratici. - Penn Treebanks
Questo corpus include il POS tagging delle frasi. E' stato creato dalla University of Pennsylvania. - British National Corpus ( BNC )
E' rappresentativo della lingua inglese scritta e parlata in Gran Bretagna. - The American National Corpus ( ANC )
E' rappresentativo della lingua inglese scritta e parlata negli USA. - The Corpus of Contemporary American English ( COCA )
- Google N-gram Corpus
- Reuters Corpus
Esistono text corpora nella lingua italiana? Ce ne sono diversi. Alcuni hanno una valenza accademica, altri sono commerciali. L'enciclopedia Treccani ha pubblicato un elenco di text corpora in italiano. Non è esaustivo ma è molto utile per cominciare. C'è anche un'utile banca dati online su corpus italiano.




