L'indice TF-IDF nell'analisi del testo
Cos'è la TF-IDF
Secondo la TF-IDF le parole comuni presenti in tutti i documenti di un archivio sono quelle meno importanti. E' preferibile concentrare l'attenzione sulle parole specifiche.
Ad esempio, una parola comune è contenuta nel 90% dei documenti. Sarebbe inutile e dispendioso selezionarli tutti. Viceversa, una parola specifica è presente soltanto nel 5% dei documenti.
Come funziona l'algoritmo
L'algoritmo è composto da due parti distinte.
- IDF ( Inverse Document Frequency ). Questo indicatore misura la frequenza inversa di una parola tra tutti i documenti. E' molto alto nei termini specifici, mentre è molto basso nelle parole comuni.
- TF ( Term Frequency ). Questa componente misura la frequenza di una parola all'interno di un documento specifico. Quante più occorrenze della parola si presentano nel documento, tanto maggiore è il valore dell'indicatore TF.
Un indicatore empirico è il seguente
TF-IDFx,y = ( Nx,y / N*,y ) * log ( D / Dx )
Il primo fattore è la componente TF. Dove Nx,y è il numero di volte che la parola X si presenta nel documento Dy mentre N*,y è il numero totale delle parole nel documento.
Il secondo fattore è la componente IDF. La variabile D è il numero dei documenti in archivio mentre Dx è il numero dei documenti in cui la parola X compare almeno una volta.
Un esempio pratico di TF-IDF
In una base dati sono presenti 1000 documenti ( N=1000 ). Desideriamo selezionare quelli contenenti la parola chiave "energia rinnovabile".
Il termine è presente soltanto in 5 documenti su 1000. Il suo valore IDF è pari a log 1000/5 ossia IDF=2,3. E' abbastanza alto, si tratta di una parola chiave.
IDF=2,3
In un documento con cento parole la parola "energia rinnovabile" è presente con 5 occorrenze, è ripetuta cinque volte nel testo. Il suo valore TF è pari a 0,05.
TF=0,05
Il prodotto dei due indicatori TF e IDF ci consente di calcolare l'indicatore TF-IDF, ossia l'importanza del documento rispetto alla chiave di ricerca K.
TF-IDF = 0,05 x 2,3 = 0,115
Se avessimo cercato una parola più comune, il suo valore IDF sarebbe stato più basso, riducendo l'importanza del documento.
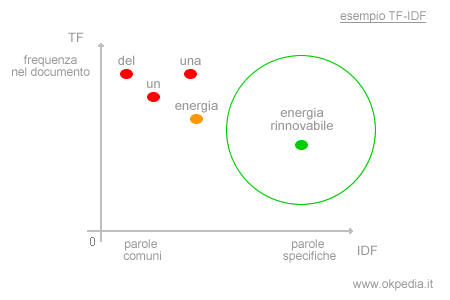
Ad esempio, la parola "energia" è più frequente nei documenti in archivio. Il suo valore IDF è pari 1,1. In questo caso, non si tratta di una parola chiave bensì di una parola principale, una di quelle che compone il lessico di un argomento.
A parità di occorrenze ( TF=0,05 ) la parola "energia" ha minore importanza nel documento.
TF-IDF = 0,05 x 1,1 = 0,055
Da notare, le parole comuni sono presenti in quasi tutti i documenti. Il loro valore IDF è molto alto. Nel processo di selezione la loro importanza è molto bassa.
In alcuni casi, le parole comuni possono anche essere eliminate del tutto dalla query della ricerca ( stop-word ).
A cosa serve
Le parole indice sono il fattore determinante in un'analisi di testo LSA ( Latent Semantic Analysis ).
Non tutte le index word sono importanti e, sicuramente, le parole hanno un peso semantico differente.
Per considerare questo aspetto è utile integrare nell'algoritmo l'euristica TF-IDF ( Term Frequency - Inverse Document Frequency ).
In conclusione
L'argoritmo di ricerca TF-IDF consente di selezionare le risorse dando maggiore importanza a quelle contenenti delle parole specifiche, meno frequenti ma più rilevanti per l'efficacia della selezione.
11 / 07 / 2014




