Lo spam semantico
Gli algoritmi di ricerca semantica
I motori di ricerca semantici utilizzano tecniche differenti dai search engine tradizionali per stimare la qualità di un documento nei confronti di un particolare argomento. Un argomento o un concetto ha relazioni con una serie di parole e termini, verbi, ecc. Alcune relazioni sono più forti, altre più deboli. La combinazione dei termini in un documento consente all'algoritmo di associare un documento a un particolare argomento.
Si parla di algoritmo semantico in quanto il processo si basa sull'analisi del testo e delle parole. Non si può parlare però di algoritmo intelligente poiché l'agente razionale non comprende il significato testo ma si limita soltanto a verificare la frequenza delle combinazioni statistiche dei termini ( elementi ) in un documento.
In pratica, a partire dall'insieme di parole di una frase, l'algoritmo individua il contesto che più si avvicina alla combinazione e lo associa alla frase. Ogni frase è associata a un concetto. Il concetto più frequente, quello che si presenta in più frasi, viene considerato come l'argomento principale del documento.
Ad esempio, nel testo seguente prevalgono le frasi con associazioni al contesto bancario e l'algoritmo deduce che l'argomento principale del testo è la banca.
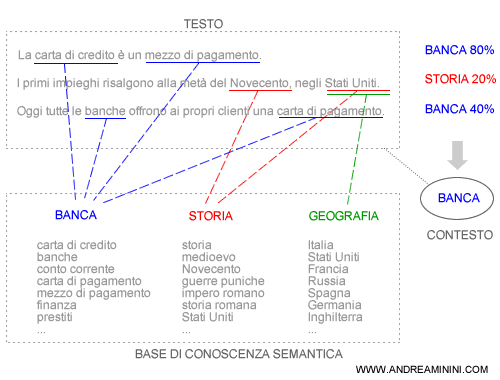
L'algoritmo ha forti limiti cognitivi ma è interessante. Potrebbe funzionare. Tuttavia... non viviamo in un mondo perfetto e, come già accaduto per i link, potremmo assistere alla nascita di nuove tecniche SEO con conseguenze semantiche devastanti per le basi di conoscenza.
Mi spiego meglio. La corrispondenza tra i termini e un concetto viene determinata dalla base di conoscenza semantica del motore di ricerca. Quest'ultima non è una struttura cristallina e apprende nuovi termini e nuove corrispondenze nel corso del tempo.
Ad esempio, quando due fonti informative distinte utilizzano un'associazione innovativa tra un termine (KEY1) e un concetto (KEY2), l'algoritmo semantico instaura una nuova relazione tra queste. Gli autori della relazione innovativa ( fonti ) diventano le più autorevoli sulla combinazione di termini (KEY1+KEY2) e, in parte, rafforzano anche la propria autorevolezza sui motori di ricerca sulle singole parole chiave.
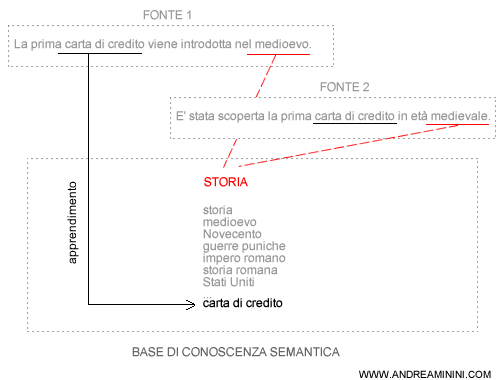
Dallo spam sui link allo spam semantico
Quale abuso e fenomeno di spam potrebbe verificarsi? È molto semplice. Pur di migliorare il posizionamento sui motori di ricerca ci saranno attività SEO che farano di tutto pur di far nascere nuove relazioni semantiche tra termini per ingannare il motore di ricerca e acquisire autorevolezza. Questo fenomeno produce però un inquinamento semantico della base di conoscenza e della rappresentazione di conoscenza, dando vita a una sorta di spam semantico. Alla fine non si riuscirà più a capire quali sono le corrispondenze semantiche naturali tra i termini e quali le corrispondenze semantiche artificiale. Un po' come accade oggi per i collegamenti ipertestuali ( link ) tra le pagine web. L'algoritmo della link popularity era efficace negli anni '90, quando nessuno lo conosceva. Nel corso degli anni duemila gli abusi sono cresciuti inquinando i risultati del motore di ricerca ( spam index ). I motori di ricerca hanno messo in essere delle contromosse, hanno perfezionato i propri algoritmi e introdotto dei filtri anti-spam. Ciò nonostante anche il mondo SEO si è evoluto, mettendo in essere nuove tecniche sempre più raffinate e difficili da individuare, fino al punto da rendere difficoltoso distinguere tra un link. Molto probabilmente, secondo me, accadrà la stessa cosa per i motori di ricerca semantici. Fin quando non ci saranno agenti veramente intelligenti, in grado di leggere il contenuto di una frase, non si giungerà a una soluzione finale. 18 / 06 / 2014
La popolarità semantica
Va comunque considerato anche un altro aspetto. Per influenzare le relazioni semantiche sono necessari molti input online, senza i quali il motore di ricerca non modificherebbe alcuna relazione o, perlomeno, la varierebbe utilizzando delle variabili fuzzy. In pratica, se dieci siti web iniziano a produrre contenuti su una nuova relazione semantica, più o meno vera, non è detto che il search engine la prenda subito in considerazione poiché è poco popolare. Potrebbero verificarsi per ipotesi i seguenti scenari:
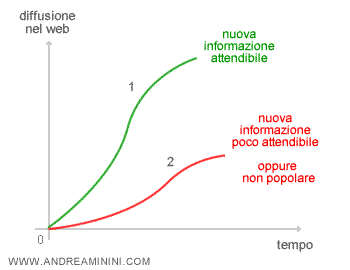
- Diffusione del concetto sulla rete.Soltanto nel momento in cui la relazione viene condivisa, citata e dibattuta online su più risorse tra loro indipendenti ( forum, social network, siti web, query degli utenti sul search engine, ecc. ), la nuova relazione diventa affidabile e la variabile fuzzy si avvicina al valore uno. Ovviamente, quanto più sono autorevoli i siti web che la lanciano, tanto si hanno buone probabilità di farla diventare popolare ( caso 1 ). Viceversa, se a parlarne sono in pochi ( caso 2 ) o la curva di diffusione assume una forma poco naturale, allora il processo di aggiunta della nuova conoscenza si rallenta o si blocca del tutto.
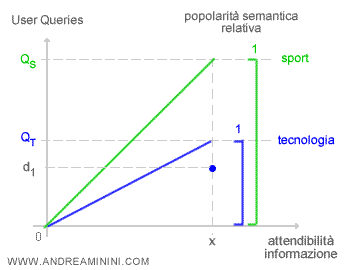
- La popolarità semantica relativa. Alcuni argomenti sono popolari, altri meno. Per evitare che i primi abbiano maggiore peso sulle SERP si dovrebbe ragionare in termini di popolarità semantica relativa. La diffusione di un argomento innovativo A+B sulle queries dovrebbe essere rapportato all'insieme delle queries del contesto A e del contesto B, e non in rapporto all'insieme universo delle ricerche. In questo modo alcune novità di nicchia possono emergere, in quanto popolari nel proprio campo ( es. notizie scientifiche o accademiche ). Ad esempio, la diffusione assoluta d1 di un'informazione è più che sufficiente nel primo contesto ( blu ) ma insufficiente nell'altro ( verde ) in quanto cambia il numero delle queries degli utenti di riferimento. Nel primo caso ( blu ) la variabile fuzzy che misura l'attendibilità della novità semantica è vicina a 1 ( attendibile ), mentre nel secondo caso ( verde ) è al di sotto dello 0.5 ( non attendibile ).
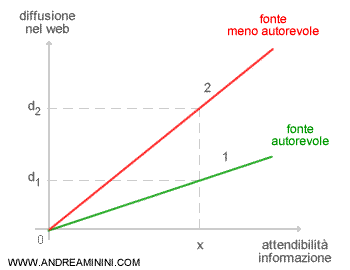
- L'autorevolezza di chi ne parla. L'autorevolezza è un fattore già conosciuto da Google nell'ambito dell'indicizzazione. Il motore di ricerca potrebbe pesare un'associazione semantica innovativa all'autorevolezza delle fonti che ne parlano. Se la novità semantica proviene da siti di scarsa reputazione, o non esperti in materia, il processo di apprendimento potrebbe non partire nemmeno. Se un'ipotesi teorica è lanciata da una università ha un peso (caso 1), se viene lanciata da uno sconosciuto su un blog ne ha un altro (caso 2). Entrambe meritano di essere prese in considerazione ma con un peso differente. Per avere il medesimo livello di attendibilitò, nel primo caso (1) è sufficiente una diffusione d1 mentre nel secondo caso (2) almeno una diffusione pari a d2.
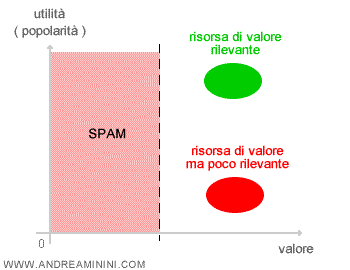
- L'utilità e il valore dell'argomento. Una nuova relazione semantica può essere utile o meno. Quando è utile, gli utenti iniziano a cercarla sul motore di ricerca ed è sufficiente monitorare le queries degli utenti per rendersi conto della sua popolarità. Il valore e l'utilità sono due aspetti diversi dell'informazione. Un'associazione di argomenti potrebbe essere di valore ma poco popolare, se nessun utente la cerca. L'obiettivo principale del search engine è migliorare l'esperienza degli utenti e, pertanto, conferirà una maggiore priorità agli argomenti più popolari, quelli più ricercati dagli utenti nelle queries, e meno a tutti gli altri.
- La normalizzazione tramite le basi di conoscenza esterne. E', infine, possibile correggere il processo di apprendimento automatico tramite il confronto con le basi di conoscenza esterne al web, ufficiali e autorevoli sui singoli topic. Ad esempio, le basi di conoscenza enciclopediche online ( dbpedia, Wikipedia, ecc. ) che vantano un processo di aggiunta delle informazioni soggetto a verifica e controllo manuale. Questa attività di controllo riduce fortemente il rischio di spam. Se una nuova conoscenza non è confermata nel tempo, potrebbe essere considerata irrilevanti e le fonti di origine perdere di reputazione.
In conclusione, lo spam semantico è un fenomeno teoricamente possibile ma anche raro. È improbabile che poche centinaia di informazioni o disinformazioni pubblicate sul web siano sufficienti a influenzare sensibilmente una base di conoscenza in una logica fuzzy. Le fonti innovatrici, quelle che lanciano per primi un nuova relazione A+B, beneficiano immediatamente di una buona posizione sulle serp per le ricerche A+B, ma difficilmente ottengono autorevolezza anche per il topic A e/o per il topic B, fino quando la relazione A+B non diventi sufficientemente popolare e attendibile. Se così fosse, è giusto che i siti innovatori siano premiati in autorevolezza per essere stati i primi a parlarne. In caso contrario è un'informazione poco rilevante oppure spam ed è giusto che le fonti perdano di reputazione e di credibilità generale.




