Adaboost
Adaboost è un algoritmo di ensemble learning che utilizza il metodo boosting. E' utilizzato nel machine learning.
L'algoritmo è stato sviluppato da Yoav Freund and Robert Schapire. Adaboost è l'abbreviazione di Adaptive Boosting.
A cosa serve
L'algoritmo formula H ipotesi tramite l'algoritmo di ensemble boosting a partire da un training set di N esempi.
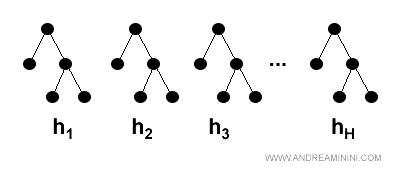
Nota. Ogni ipotesi è costruita con un algoritmo di boosting ed è diversa dalle altre. Ad esempio, ogni ipotesi è un albero decisionale diverso perché è stato costruito usando parametri differenti.
A ciascuna ipotesi assegna un peso z per misurare la sua efficacia.
Infine, l'algoritmo elabora l'ipotesi finale a maggioranza pesata.
Come funziona l'algoritmo AdaBoost
L'algoritmo prende in input una distribuzione iniziale degli esempi.
Un insieme di training set è composto da N esempi del tipo ( x, y ).
Inizialmente tutti gli esempi hanno lo stesso peso ( importanza ) pari a 1/N.
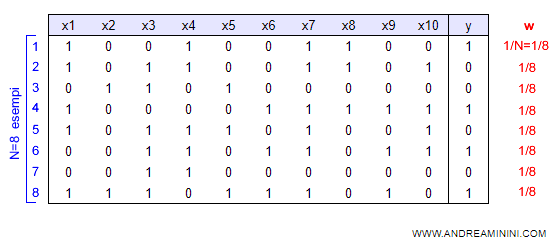
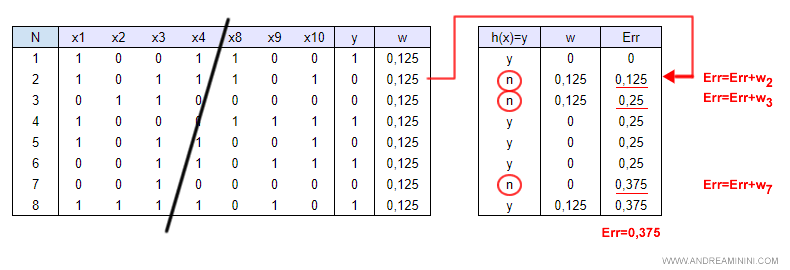
Nota. Nella precedente tabella di training set sono presenti N=8 esempio. Pertanto, il peso iniziale di ciascun elemento del vettore w è pari a 1/N ossia 1/8=0,125.
Infine AdaBoost utilizza un algoritmo di apprendimento (X) per costruire l'ipotesi H in base agli esempi dell'insieme di training.
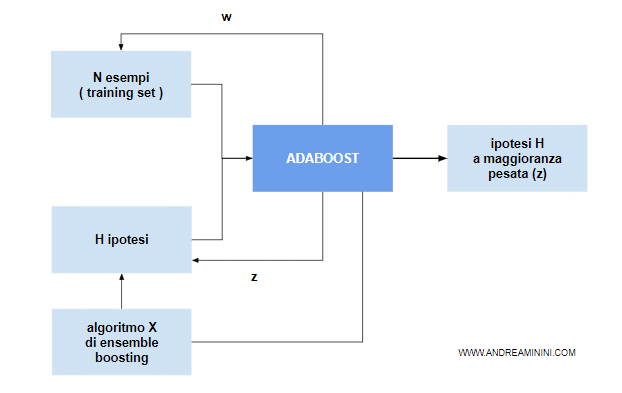
Le H ipotesi sono elaborati dall'algoritmo di apprendimento utilizzando gli N esempi.
Durante l'elaborazione l'algoritmo calcola dei pesi:
- w = vettore di N pesi associati agli N esempi
- z = vettore di H pesi associati alle H ipotesi
Nota. Nel primo ciclo di elaborazione il vettore w è composto da N elementi con valore 1/N. Quindi, inizialmente gli esempi hanno tutti la stessa importanza.
Nel primo ciclo AdaBoost prende in considerazione la prima ipotesi h(1) e la confronta con gli N esempi e ai relativi pesi w.
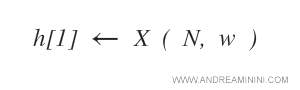
All'ipotesi è associata una variabile errore, inizialmente assegnata a zero.
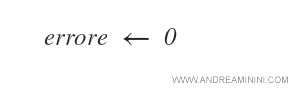
Se l'ipotesi h[1] risponde correttamente a un j esempio, l'algoritmo riduce il peso wj dell'esempio.
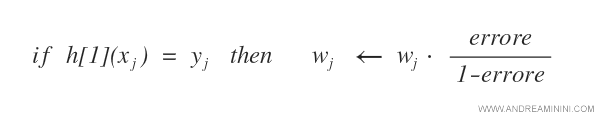
Nota. La formula per variare l'errore può anche essere diversa. In questo caso, azzera il peso dell'esempio in base all'errore cumulato dell'ipotesi.
Viceversa, se l'ipotesi h[1] sbaglia un j esempio, aumenta la variabile errore in base al peso wj dell'esempio.

Nota. Pertanto, se l'algoritmo sbaglia sugli esempi più importanti, la variabile errore viene incrementata molto di più.
Ad esempio, nel seguente caso l'algoritmo sbaglia a rispondere agli esempi 2, 3 e 7.
La variabile dell'errore viene incrementata di volta in volta con il relativo peso (w) dell'esempio sbagliato.
Al termine dell'elaborazione di tutti gli N esempi, l'algoritmo normalizza i nuovi pesi w degli esempi, per fare in modo che la somma dei pesi sia sempre pari a 1.

Poi l'algoritmo calcola il peso z[1] dell'ipotesi h[1].
Il peso dell'ipotesi viene ricalcolato in base all'errore rilevato sugli esempi.
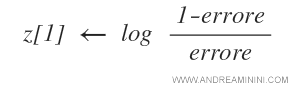
Nel caso in questione, la prima ipotesi ha registrato un errore pari a 0,375.
Quindi il peso dell'ipotesi z[1] è pari a 0,22
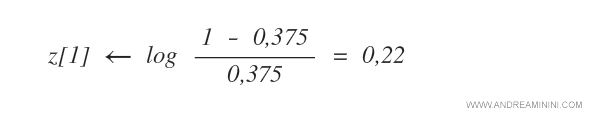
Nota. Il peso dell'ipotesi z è tanto più alto, quanto minore è il valore dell'errore rilevato durante la prova. Pertanto, le ipotesi più performanti hanno un peso z più alto (z→∞) mentre quelle peggiori hanno un peso z tendente a zero (z→0).
A questo punto, il ciclo ricomincia per analizzare l'ipotesi successiva h[2].
E così via.
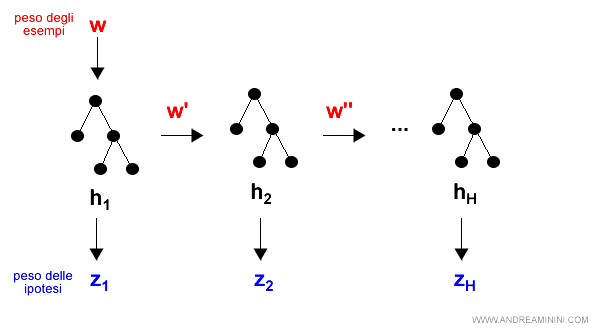
Nota. Nel secondo ciclo i pesi w degli N esempi sono cambiati. Ora gli esempi dove ha fallito l'ipotesi precedente sono diventati più importanti rispetto agli altri.
Infine, dopo aver calcolato tutte le ipotesi, l'algoritmo decide l'ipotesi finale a maggioranza pesata.
Per ciascun esempio, la risposta dell'algoritmo è quella che ottiene la maggioranza sommando i pesi (z) delle ipotesi.
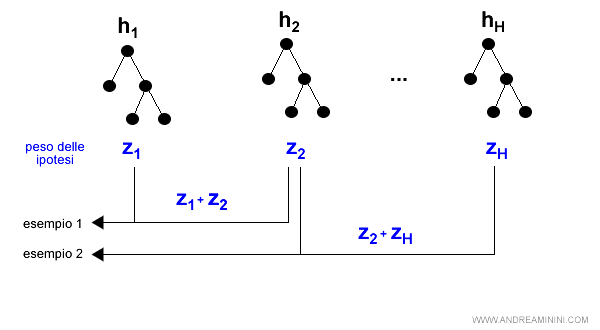
Nota. AdaBoost funziona soltanto nelle situazioni di apprendimento debole, quando le decisioni elaborate dall'algoritmo di apprendimento X sono comunque leggermente migliori rispetto alle scelte casuali.
Un esempio pratico
Nei libri di machine learning è molto frequente trovare questo problema giocattolo per spiegare il funzionamento di AdaBoost.
Problema
L'algoritmo deve disegnare la frontiera tra le X e le O.
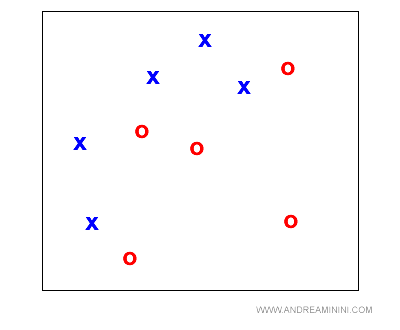
Nota. La frontiera tra le X e le O è intuitiva e si vede a occhio nudo. Tuttavia, non è una frontiera lineare. L'algoritmo deve trovare in modo per individuarla.
AdaBoost è impostato per elaborare H=3 ipotesi.
Prima ipotesi (H1)
La prima ipotesi seleziona due X e tutte le O ma commette 3 errori ( le tre X ).
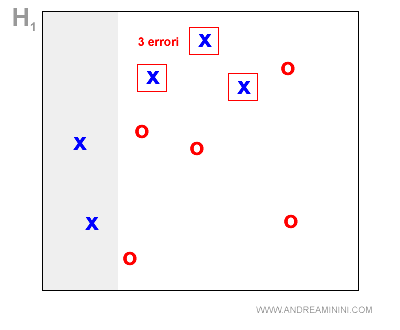
A questo punto, AdaBoost potenzia i tre casi di errore e assegna all'ipotesi H1 il peso z1 = 0,40.
Seconda ipotesi (H2)
Nella seconda iterazione i pesi degli esempi sono cambiati, ora alcuni esempi hanno un peso maggiore e sono più importanti ( le 3 X sbagliate nella prima iterazione ).
La seconda ipotesi seleziona tutte le X ma commette tre errori ( le tre O ).
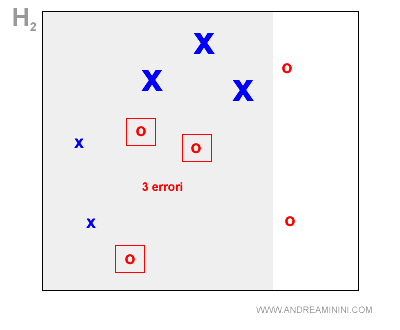
Anche in questo caso AdaBoost potenzia i tre errori e riduce il peso degli altri esempi.
Poi assegna all'ipotesi H2 il peso z2=0.6.
Nota. Pur avendo commesso lo stesso numero di errori rispetto a H1, l'ipotesi H2 ha un peso maggiore ( 0.6>0.4 ) perché classifica bene gli esempi che hanno un peso maggiore ( le tre X sbagliate da H1 ). Nell'ipotesi H1 invece gli esempi avevano tutti lo stesso peso.
Terza ipotesi
Al terzo ciclo l'algoritmo formula l'ipotesi H3.
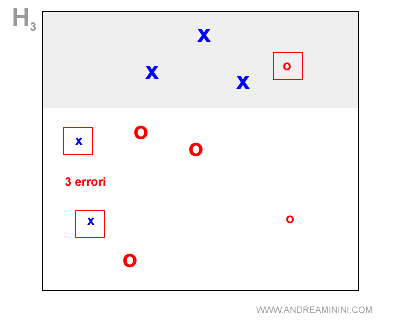
L'algoritmo assegna all'ipotesi H3 il peso z2=0.9.
E' l'ultima ipotesi dell'algoritmo, quindi l'algoritmo non ricalcola i pesi degli esempi.
Nota. L'efficacia delle ipotesi è migliorata nel corso dell'iterazione. Dalla prima ipotesi (z1=0.4) si arriva alla terza ipotesi (z3=0.9).
L'ipotesi finale a maggioranza pesata
A questo punto l'algoritmo sceglie a maggioranza pesata l'ipotesi finale.
Per ciascun riquadro ( o esempio ) si sommano i pesi z delle ipotesi favorevoli e sfavorevoli.
Poi si sceglie l'ipotesi che ha maggioranza pesata.
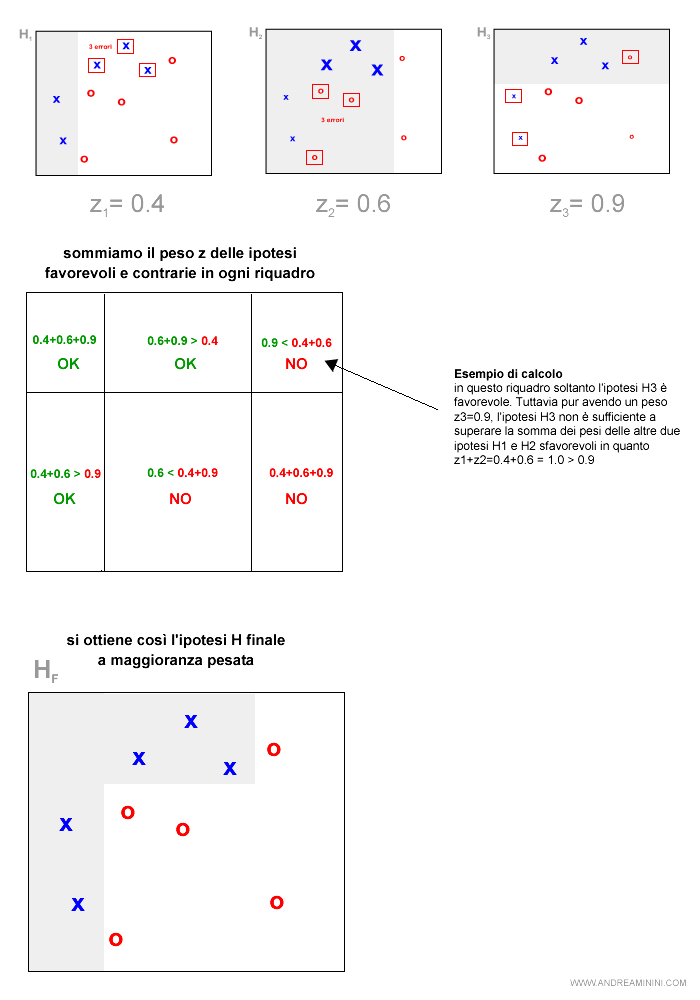
Nell'AdaBoost non vince l'ipotesi che ottiene il peso maggiore ( es. z3 ). Bensì la somma dei pesi delle ipotesi più alta delle altre ( es. .z1+z2>z3 ) per risolvere un particolare esempio del problema.
Il risultato finale è esattamente quello che volevo.
La frontiera separa perfettamente le X dalle O.




