La classificazione nel Machine Learning
La classificazione (classification) è un problema tipico dell'apprendimento automatico (machine learning). Consiste nell'assegnare un dato a una categoria sulla base di un modello di classificazione appreso dalla macchina tramite l'intelligenza artificiale.
Ad esempio, un algoritmo decide se un messaggio email in arrivo è spam oppure no. In questo caso le classi sono due: spam e no-spam. La decisione non dipende da un modello di classificazione deciso dal programmatore bensì dall'esperienza della macchina durante l'addestramento oppure da metodi statistici.
Come funziona l'algoritmo di classificazione
Un problema di classificazione può essere risolto tramite diverse tecniche e paradigmi di machine learning.
- ML Supervisionato. La macchina riceve in input degli esempi già classificati con alcuni messaggi spam e no spam ( training set ). Sulla base di questi esempi la macchina costruisce un modello decisionale per classificare le future email.
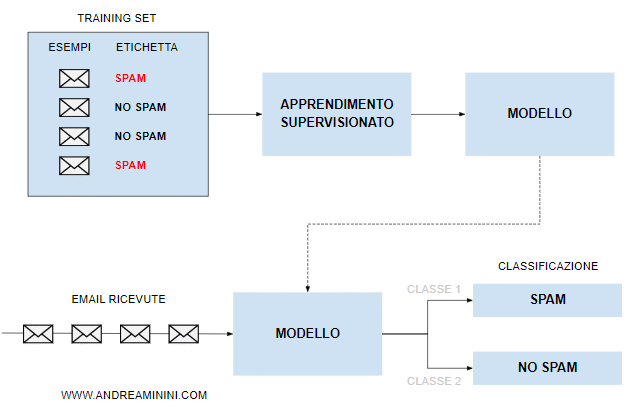
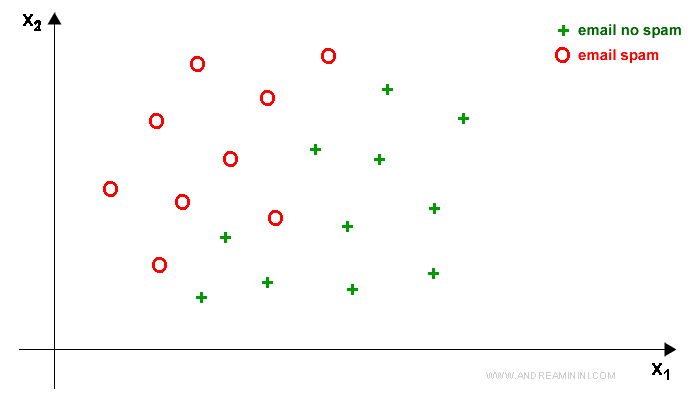
- ML non supervisionato. In questo caso la macchina non ha esempi già classificati. La decisione si basa sulla vicinanza/distanza dei dati. Se i dati di un'email sono simili a quelli di un'altra email spam, allora anche la prima è probabilmente spam. E viceversa. Una tecnica di questo tipo è il clustering.
Esistono diversi algoritmi di classificazione (classifier) più o meno efficienti. La lista sarebbe molto lunga.
E così via.




