Approccio RBL ( Relevant based learning )
Un sistema di machine learning RBL usa la conoscenza pregressa sotto forma di determinazioni. Le determinazioni consentono di trovare nei dati gli attributi più rilevanti per l'apprendimento. E' un apprendimento induttivo basato sulla conoscenza pregressa.
Qual è il vantaggio? L'uso delle determinazioni accelera l'apprendimento perché elimina gli attributi irrilevanti e, quindi, riduce lo spazio delle ipotesi da analizzare.
Cos'è una determinazione?
Una determinazione è una proposizione generale applicata alla realtà.
E' anche detta dipendenza funzionale.
Un esempio di determinazione
La macchina analizza il training set per cercare delle regolarità ( pattern ).
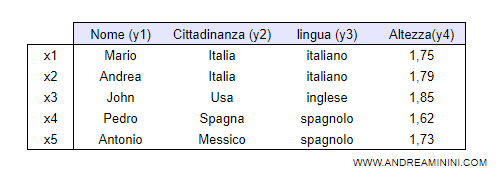
Dall'analisi emerge che tutti i cittadini di una nazione parlano la lingua ufficiale del paese.
Cittadinanza(x,n) ⇒ Lingua(x,l)
Dove x è l'incognita che indica una qualsiasi persona.
Se x è nato in Italia (n="Italia") allora parla la lingua italiana (l="italiano").
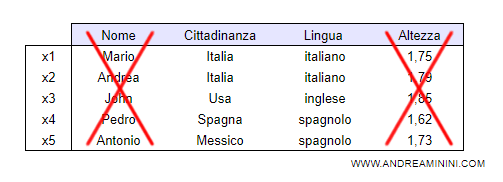
Questa generalizzazione consente alla macchina di escludere due attributi ( Nome, Altezza ) per rispondere alla domanda "parla italiano?"
Le determinazioni rilevanti e irrilevanti
Ovviamente non tutte le determinazioni sono vere o sono utili.
Possiamo quindi distinguerle in:
- Determinazioni rilevanti. Sono le generalizzazioni che aiutano l'apprendimento. Il margine di errore è molto basso.
Esempio. Tutte le persone con cittadinanza italiana parlano l'italiano. Il margine di errore di questa affermazione è molto basso. Va comunque detto che qualsiasi generalizzazione implica un margine di errore, seppure minimo. Per questo motivo, è utile associare le dipendenze funzionali alla logica fuzzy.
- Determinazioni irrilevanti. Sono le generalizzazioni inutili o false che non aiutano l'apprendimento. Anzi, sono fuorvianti. Sono dovute a errori presenti nei dati di training oppure a campioni non rappresentativi della realtà.
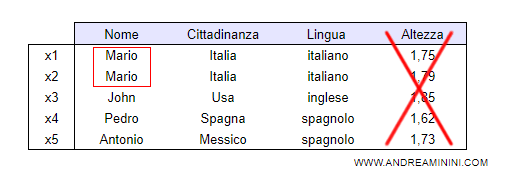
Esempio. Tutte le persone che parlano l'italiano si chiamano Mario. E' chiaramente una generalizzazione fuorviante, dedotta per sbaglio dall'analisi dei dati
Come funziona il sistema RBL
La macchina apprende le regole analizzando un training set.
Dal training set deduce delle generalizzazioni (determinazioni) che ampliano la sua conoscenza pregressa.

La conoscenza a priori deve essere appresa. Quando l'algoritmo trova una determinazione consistente con l'insieme di esempi, la aggiunge alla conoscenza pregressa. Va quindi considerato un costo di ricerca ex-ante o online.
A sua volta la conoscenza pregressa contribuisce a migliorare l'apprendimento.
Le determinazioni e le osservazioni generano altre generalizzazioni. E così via.
Pertanto, dopo i primi cicli iniziali, il process learning diventa sempre più efficiente e più rapido.
La differenza tra EBL e RBL. L'approccio EBL trova tutte le generalizzazioni nel training set e le usa come background. L'approccio RBL invece si concentra soltanto sulle generalizzazioni rilevanti. E' quindi più efficiente ma anche più complesso.
Come trovare le determinazioni?
Esistono diversi algoritmi di ricerca delle determinazioni ( RBDTL ).
Ad esempio, compongo una determinazione con un predicato e verifico se è consistente con gli esempi.
Nazionalità(x, n) → Lingua(x, l)
Dopo aver elaborato tutte le combinazioni a un predicato ( determinazioni minime ) passo ad analizzare quelle a due predicati.
Altezza(x, n)∧Peso(x, p) → Obesità(x, o)
Poi passo a quelli con tre predicati.
E così via.
Attenzione. Questo algoritmo ricerca delle determinazioni ha complessità esponenziale. Il tempo di esecuzione cresce in modo esponenziale con il numero degli attributi p della determinazione consistente minima O(np). Dove n sono gli attributi totali e p gli attributi della determinazione consistente. Pertanto, questo algoritmo conviene soltanto se il numero degli attributi p è basso.
Una volta ridotto lo spazio delle ipotesi H → H' tramite le determinazioni, eseguo l'algoritmo di apprendimento direttamente sullo spazio delle ipotesi ristretto (H').
In questo il processo di learning elabora soltanto gli attributi rilevanti con l'obiettivo da raggiungere.
Pro e contro
I vantaggi del sistema RBL
- Riduzione dello spazio delle ipotesi. L'algoritmo RBL elimina le ipotesi e gli attributi ridondandi. Quanto più lo spazio di ricerca si riduce, tanto più efficiente è la ricerca.
Esempio. Se il dataset contiene n caratteristiche booleane ( 0 o 1 ), la complessità della ricerca è O(2n). L'algoritmo RBL elimina m caratteristiche, facendo scendere la complessità a O(2n-m).
- Apprendimento più veloce. Il learning process è più rapido ed economico perché la macchina concentra l'analisi sulle ipotesi e sugli attributi più rilevanti. E' un processo molto più efficiente rispetto alla semplice costruzione di un albero decisionale.
Gli svantaggi del sistema RBL
- Il costo della ricerca delle determinazioni rilevanti. Non è sempre facile individuare le determinazioni rilevanti. La ricerca delle determinazioni implica comunque un costo computazionale.
Nota. Il costo della ricerca delle determinazioni può comunque essere ammortizzato nel tempo. Ad esempio, le determinazioni potrebbero essere archiviate in una base di conoscenza condivisa da diverse macchine. In questo modo, le nuove macchine/algoritmi possono beneficiarne ed evitano di doverle ricalcolare.
- Un'eccessiva generalizzazione. Un errore nella conoscenza pregressa può limitare eccessivamente lo spazio delle ipotesi, causando la perdita di informazioni rilevanti nei rami più profondi del training set.
Esempio. La macchina deve capire chi ha scritto un'email in italiano. Usa la conoscenza pregressa e limita la ricerca alle sole persone con cittadinanza italiana. Se l'email fosse stata scritta da uno spagnolo che parla l'italiano come seconda lingua o l'avesse fatta tradurre da Google, la macchina non riuscirebbe mai a capirlo.




