Ensemble learning
L'ensemble learning è una tecnica di apprendimento automatico ( machine learning ) basata sulla costruzione di più ipotesi.
Come funziona l'ensemble learning
Il termine ensemble significa "collezione" e indica un insieme di ipotesi che la macchina elabora.
A differenza dei sistemi più semplici, per formulare una previsione la macchina non estrapola una sola ipotesi ma molte.
Nota. Nel machine learning un'ipotesi è un albero decisionale. Un decision tree è costruito selezionando prima gli attributi considerati più rilevanti, poi tutti gli altri secondo una classificazione gerarchica. Ogni albero decisionale ha un margine di errore previsionale.
Perché formulare più ipotesi?
Costruendo più decision tree a partire dallo stesso insieme di dati, si riduce la probabilità di errore, perché ogni albero segue un metodo di ragionamento differente.
E' quindi probabile che gli alberi forniscano risposte diverse.
Nota. Mi piace spiegare l'ensemble learning ricordando una scena del film "L'attimo fuggente", quando il professore sale in piedi sulla cattedra. Dobbiamo sempre guardare le cose da angolazioni diverse, perché il mondo appare diverso. E' proprio quando credete di sapere qualcosa che dovete guardarla da un'altra prospettiva. Anche se può sembrare assurdo.
Quale soluzione scegliere?
Per prendere una decisione la macchina consulta tutti gli alberi decisionali che ha estrapolato.
Poi sceglie la risposta fornita dalla maggioranza degli decision tree.
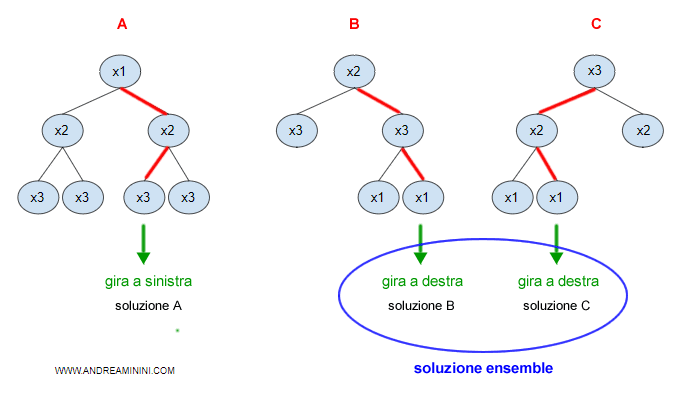
Un esempio pratico
Il processo di ensemble learning è suddiviso in due fasi:
1) La costruzione delle ipotesi
La macchina utilizza un training set ( dati di addestramento ) e a partire da questo insieme di dati costruisce un albero decisionale.
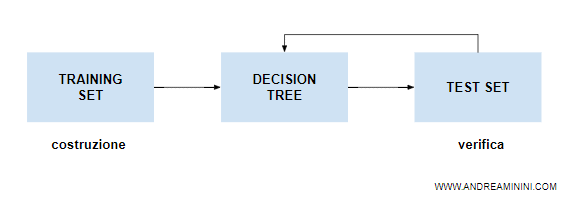
Nota. In questa pagina evito di spiegare come si costruisce un decision tree. Per approfondimenti rimando ai miei appunti su come costruire un albero decisionale.
Nel caso dell'ensemble learning, la macchina elabora N alberi decisionali diversi tra loro.
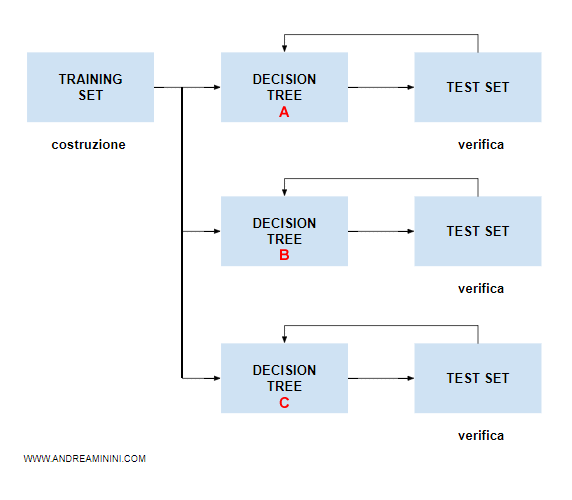
Come fa l'algoritmo a costruire alberi decisionali diversi? Esistono diverse tecniche per costruire più alberi decisionali a partire dallo stesso insieme di addestramento ( training set ). Ad esempio l'algoritmo di boosting.
Ogni albero decisionale ( A, B, C ) si distingue dagli altri per forma, perché la macchina seleziona in modo differente gli attributi. E' un'ipotesi e un metodo di ragionamento a sé.
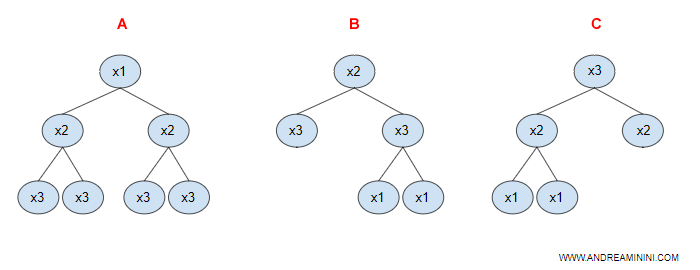
E' quindi probabile che, a parità di condizioni, ogni albero fornisca una risposta differente per risolvere i problemi pratici.
1) La fase decisionale
Per risolvere un problema, la macchina consulta tutti gli alberi decisionali dello spazio delle ipotesi che ha costruito.
Gli alberi decisionali forniscono risposte diverse, perché seguono logiche differenti.
Ogni albero ha una probabilità px di errore.
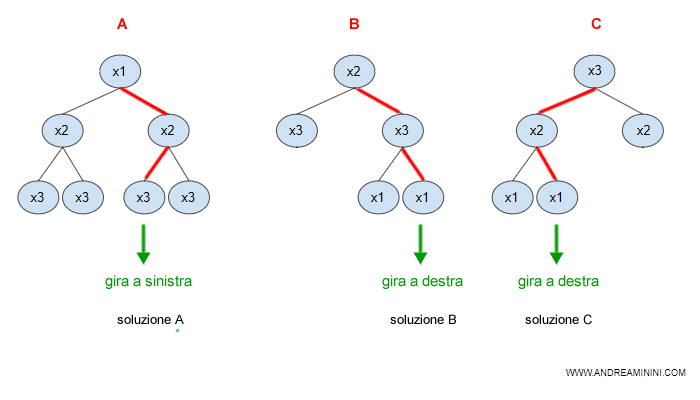
Pur fornendo risposte diverse, è comunque probabile che alcuni decision tree restituiscano la stessa risposta.
A questo punto, la macchina sceglie la soluzione più frequente o quella fornita dalla maggioranza degli alberi decisionali.
In questo modo si riduce la probabilità di errore del sistema decisionale.
Nota. A seconda delle circostanze la regola decisionale può variare. Ad esempio, se il costo dell'errore è molto alto, la macchina adotta la soluzione fornita dal 70%-80% dei decision tree. Se invece il costo è basso, seleziona la soluzione quella più frequente anche se è fornita da pochi decision tree. E così via.
I limiti dell'ensemble learning
Quando si utilizza un solo training set gli alberi decisionali non sono veramente indipendenti l'uno dagli altri
Se l'insieme di addestramento contiene dati fuorvianti, è probabile che influenzi negativamente la costruzione di tutti gli alberi decisionali.
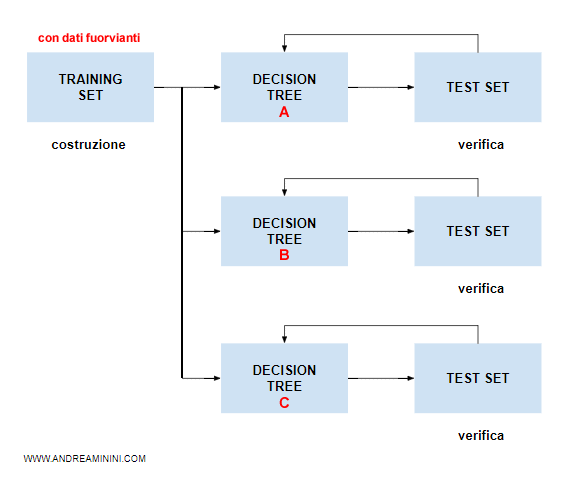
Perché l'insieme di addestramento contiene errori? Un training set è composto da una serie di esempi selezionati a campione. C'è sempre il rischio che il campionamento non sia ben rappresentativo della realtà. Alcune situazioni e circostanze importanti potrebbero essere escluse.
Come risolvere il problema?
Per eliminare questo problema posso aumentare lo spazio dell'ipotesi, usando training set differenti.
In questo modo, ogni albero decisionale ( o gruppo di alberi ) è associato a un training set diverso.
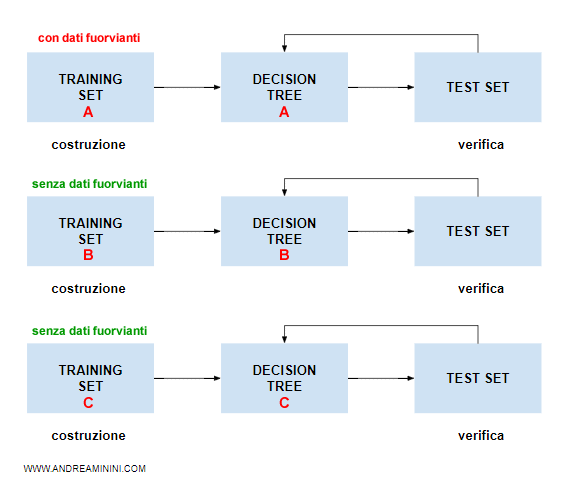
In questo caso gli alberi decisionali A, B e C sono veramente indipendenti tra loro.
Si riduce così il rischio dovuto alla presenza di dati fuorvianti in un insieme di addestramento.
Nota. Quanti più training set si utilizzano, tanto più si riduce è la probabilità di errore della macchina. E' infatti improbabile che gli stessi dati fuorvianti siano presenti in tutti gli insiemi di addestramento.




