Overfitting
Nel machine learning l'overfitting è il rischio di sovradattamento durante il processo di apprendimento induttivo.
In cosa consiste? L'algoritmo individua delle false regolarità. Alcuni dati mostrano una relazione tra un attributo irrilevante X e il risultato finale Y. Tuttavia, si tratta di rumori che sporcano i dati e fuorviano l'apprendimento induttivo della macchina.
Detto in modo più semplice, l'algoritmo si adatta (fitting) troppo bene (over) ai dati di training perdendo in generalità.
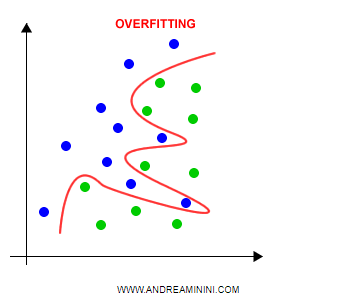
Apparentemente il modello sembra perfetto sui dati di training.
Tuttavia, quando si applica il modello ai dati di test si registrano molti errori.
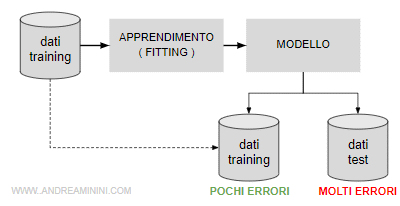
Perché accade l'overfitting?
L'overfitting può avere diverse cause:
- La macchina o il supervisore prende in considerazione nell'insieme di addestramento ( training set ) degli attributi X irrilevanti con la decisione finale Y.
- I dati di training sono insufficienti. Gli esempi sono troppo pochi.
- I dati di training non sono rappresentativi della realtà.
Un esempio pratico di overfitting
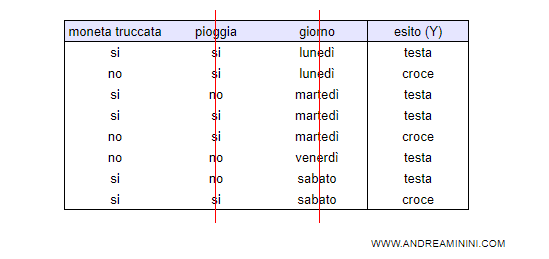
L'insieme di addestramento contiene 10 esempi di lancio della moneta.
L'esito (Y) è testa o croce.
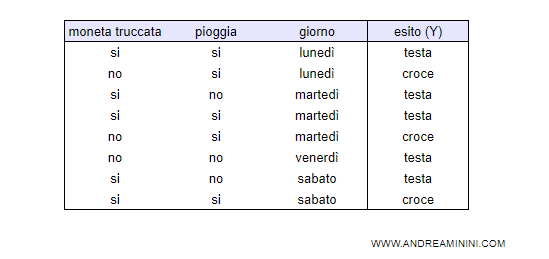
Per ogni lancio sono presi in considerazione tre attributi (X):
- moneta truccata
- pioggia
- giorno della settimana
Nota. In questo esempio due attributi sono irrilevanti ( settimana e pioggia ) mentre un attributo è rilevante ( moneta truccata ). Tuttavia, l'attributo rilevante è probabilistico. Se la moneta è truccata, esce testa in 4 casi su 5 ( 80% ).
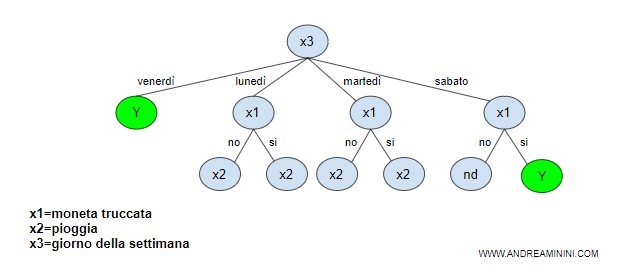
Analizzando i dati, la macchina individua una falsa regolarità: quando si lancia la moneta di venerdì il risultato è sempre croce al 100%.
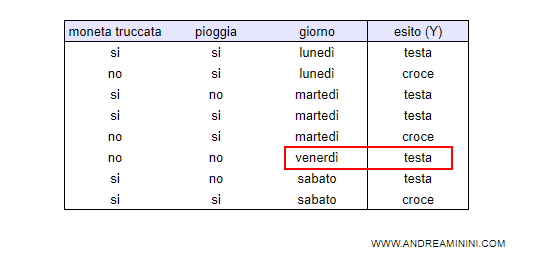
E' ovviamente una relazione di causa-effetto illogica ma questo emerge da processo di apprendimento.
Nella costruzione dell'albero decisionale la macchina seleziona l'attributo ( giorno ) come primo nodo.
Questo è un esempio tipico di sovradattamento ( overfitting ).
Nota. Lo stesso fenomeno accade agli uomini con la superstizione e le varie credenze sulla fortuna o sfortuna. Una persona vede delle regolarità apparenti nella vita quotidiana e le traduce in regole deterministiche ( es. indossare lo stesso maglione blu agli esami porta fortuna ). La causa è sempre la stessa, l'overfitting. Tuttavia, a differenza delle macchine, nel caso degli uomini la superstizione sopravvive anche se successivamente viene smentita dai fatti.
La presenza del falso pattern ( lancio di venerdì ) nell'insieme di addestramento elimina l'unico attributo rilevante probabilistico ( es. moneta truccata ).
In conclusione, la presenza degli attributi irrilevanti porta in secondo piano o nasconde del tutto gli attributi rilevanti nel processo di machine learning.
Il risultato finale è un albero decisionale consistente con i dati ma inutile.
Cosa aumenta il rischio di overfitting?
Il rischio di overfitting aumenta con il numero degli attributi presi in considerazione.
Quanto più aumentano gli attributi, tanto più aumenta la probabilità di incappare in un attributo irrilevante che sporca i dati con un falso pattern.
Nota. D'altra parte ridurre eccessivamente il numero degli attributi crea altre conseguenze. Si rischia di costruire l'albero decisionale su una visione di insieme parziale e soggettiva. Bisogna trovare un punto di incontro tra i due aspetti.
Come evitare l'overfitting
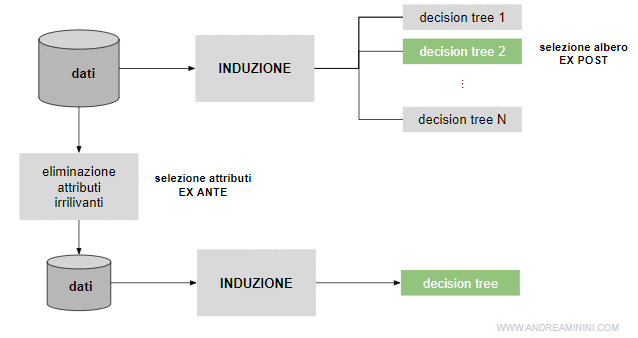
Per ridurre il rischio di overfitting occorre individuare ed eliminare gli attributi irrilevanti dai dati
E' una potatura ex-ante da compiere prima della costruzione dell'albero decisionale.
In questo modo, si elimina il rumore nei dati iniziali e si riduce poi il rischio di costruire l'albero decisionale a partire da un attributo irrilevante.
Il vantaggio della potatura ex-ante. La potatura ex-ante è molto più efficiente rispetto a una ex-post ( a posteriori ). Nella potatura a posteriori si calcolano diversi alberi misurando il grado di efficacia delle decisioni. Poi si seleziona l'albero migliore. Anche in questo modo si individuano gli attributi irrilevanti. E' però una strada che richiede tempo e risorse. La potatura ex-ante, invece, costruisce fin dall'inizio un solo albero decisionale, piccolo ed efficiente. Quindi, si consumano meno risorse e meno tempo.
Come riconoscere un attributo irrilevante?
Esistono diverse tecniche statistiche oggettive per riconoscere gli attributi irrilevanti.
Sono anche detti test di significatività.
Tra queste ci sono le seguenti:
Commenti e osservazioni degli utenti
- salve la definizione data di overfitting dal mio punto di vista non è tra le migliori. la definizione che meglio spiega l'overfitting per me è la seguente: L’overfitting è semplicemente la diretta conseguenza nel considerare i parametri statistici, e quindi i risultati ottenuti, come un’informazione utile senza verificarne la probabilità che siano ottenuti in modo casuale. Ad esempio la probabilità che un polinomio di quarto grado abbia una correlazione di 1 con 5 punti casuali su un piano è del 100%, quindi tale correlazione è inutile e siamo in una situazione di overfitting. (1/8/2019)




